spring data jpa入门教程
文章目录
- 配置文件
- 编写实体类并创建好对应数据库
- 编写对应Dao类
- Repository常用方法使用规范
- @query注解的使用
- 使用Spring Data进行删除更新操作
- CrudRepository
- PagingAndSortingRepository
- JpaRepository
- 接口继承JpaSpecificationExcutor接口
配置文件
- 首先要在pom中引入相关依赖
<!-- spring-data-jpa -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
<version>1.8.0.RELEASE</version>
</dependency>
<!-- 配置hibernate的实体管理依赖-->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>4.3.6.Final</version>
</dependency>
- 在application.properties中配置好数据库和jpa的配置
#通用数据源配置
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://127.0.01:3306/springdata?charset=utf8mb4&useSSL=false
spring.datasource.username=root
spring.datasource.password=1234
# Hikari 数据源专用配置
spring.datasource.hikari.maximum-pool-size=20
spring.datasource.hikari.minimum-idle=5
# JPA 相关配置
spring.jpa.database-platform=org.hibernate.dialect.MySQL5InnoDBDialect
spring.jpa.show-sql=true
spring.jpa.hibernate.ddl-auto=update # !注意不要用create
ddl-auto区别
- ddl-auto:create:每次运行该程序,没有表格会新建表格,表内有数据会清空。
- ddl-auto:create-drop:每次程序结束的时候会清空表。
- ddl-auto:update:每次运行程序,没有表格会新建表格,表内有数据不会清空,只会更新。
- ddl-auto:validate:运行程序会校验数据与数据库的字段类型是否相同,不同会报错。
编写实体类并创建好对应数据库
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
import lombok.Data;
/**
* @ Author zhangbin
* @ Date 2019/05/20
*/
@Data
@Entity
public class Teacher {
//配置表的id,并且是使用自增
@Id
@GeneratedValue
private Integer id;
private String name ;
private String classNumber ;
}
编写对应Dao类
import org.springframework.data.jpa.repository.Modifying;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.Repository;
import org.springframework.data.repository.RepositoryDefinition;
import org.springframework.data.repository.query.Param;
import java.util.List;
/**
* @ Author :zhangbin
* @ Date :2019/05/20
*/
//有两种方式,要么用注解要么用继承
//@RepositoryDefinition(domainClass = Teacher.class ,idClass = Integer.class)
public interface TeacherRepository extends Repository<Teacher , Integer> {
//===============使用springdata默认方式=============================
/**
* 根据名字查询老师
* @param name
* @return
*/
Teacher findByName(String name);
/**
* 根据班级名称进行查询老师(这里用到模糊匹配like)
* @param classNumber
* @return
*/
List<Teacher> findByclassNumberLike(String classNumber);
}
分析
-
(1)首先,我们这个接口是需要继承Repository这个接口
-
(2)泛型参数:第一个是我们制定这个接口所需要进行操作的实体JavaBean,第二个是我们实体JavaBean中主键的类型。(因为我这主键是id,用的Integer类型)
-
(3)继承的Repository这个接口有什么用?让我们看看源码分析一下
可以看到这是一个空接口,它的作用是什么呢? -
第一点:Repository是一个空接口,即是一个标记接口。
-
第二点:若我们定义的接口继承了Repository,则该接口会被IOC容器识别为一个Repository Bean,纳入到IOC容器中,进而可以在该接口中定义满足一定规范的方法。IOC容器中实际存放了继承了Repository的接口的实现类,而这个实现类由spring帮助完成 。在applicationContext.xml中我们配置了springdata:这里的base-package指定了Repository Bean所在的位置,在这个包下的所有的继承了Repository的接口都会被IOC容器识别并纳入到容器中,如果没有继承Repository则IOC容器无法识别。
-
第三点:我们也可以通过注解的方式替代继承Repository接口@RepositoryDefinition(domainClass=需要处理的实体类的类型,IdClass=主键的类型)。
-
第四点:看看它有哪些子类:
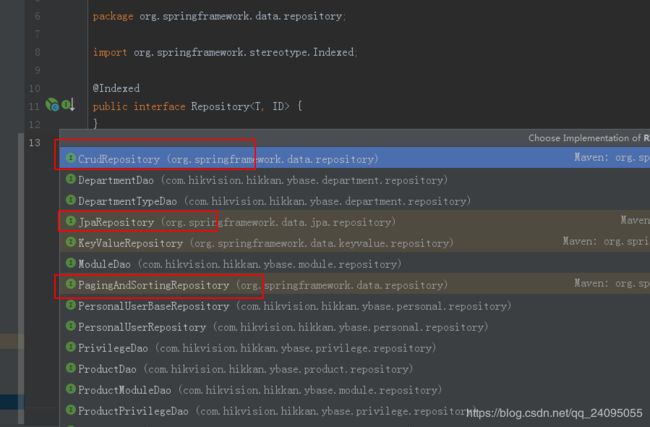
比较常用的是标出来的三个,CrudRepository、JpaRepository、PagingAndSortingRepository。
这样在我们通过controller和service层层调用(此处逻辑代码过于简单不予列出)之后就会发现数据被查出来了,可是我们也没有写这个dao接口的实现类啊,这就是Repository的强大之处,它内部集成了我们常用的方法,我们可以在继承他后可以直接调用相关方法了。这里我们使用到的是findby方法和模糊匹配findby..like方法,那它都给我们提供了哪些方法呢?
Repository常用方法使用规范
| 关键字 | 方法命名 | sql where字句 |
|---|---|---|
| And | findByNameAndPwd | where name= ? and pwd =? |
| Or | findByNameOrSex | where name= ? or sex=? |
| Is,Equals | findById,findByIdEquals | where id= ? |
| Between | findByIdBetween | where id between ? and ? |
| LessThan | findByIdLessThan | where id < ? |
| LessThanEquals | findByIdLessThanEquals | where id <= ? |
| GreaterThan | findByIdGreaterThan | where id > ? |
| GreaterThanEquals | findByIdGreaterThanEquals | where id > = ? |
| After | findByIdAfter | where id > ? |
| Before | findByIdBefore | where id < ? |
| IsNull | findByNameIsNull | where name is null |
| isNotNull,NotNull | findByNameNotNull | where name is not null |
| Like | findByNameLike | where name like ? |
| NotLike | findByNameNotLike | where name not like ? |
| StartingWith | findByNameStartingWith | where name like ‘?%’ |
| EndingWith | findByNameEndingWith | where name like ‘%?’ |
| Containing | findByNameContaining | where name like ‘%?%’ |
| OrderBy | findByIdOrderByXDesc | where id=? order by x desc |
| Not | findByNameNot | where name <> ? |
| In | findByIdIn(Collection c) | where id in (?) |
| NotIn | findByIdNotIn(Collection c) | where id not in (?) |
| True | findByAaaTue | where aaa = true |
| False | findByAaaFalse | where aaa = false |
| IgnoreCase | findByNameIgnoreCase | where UPPER(name)=UPPER(?) |
@query注解的使用
方法这么多,想要全部记住还是很困难的,所以我们也可以选择使用@query注解来进行开发。
//==============使用query注解开发==============================================
/**
* 通过query注解进行开发模糊匹配(利用索引参数的方法)
* @param classNumber
* @return
*/
@Query("select t from Teacher t where t.classNumber like %?1%")
List<Teacher> queryTeacher(String classNumber);
/**
* 通过老师的名字来进行查询数据
* @param name
* @return
*/
@Query("select t from Teacher t where t.name = ?1")
Teacher queryTeacherByName(String name );
/**
* 通过老师的名字来进行查询数据(利用命名参数的方法,注意query注解的写法不一样的)
* @param name
* @return
*/
@Query("select t from Teacher t where t.name = :name")
Teacher queryTeacherByName2(@Param("name") String name );
/**
* 使用原生的SQL语句进行操作(注意from这时候用的就是数据库的表名,而不是实体类名)
* 必须添加nativeQuery = true,因为默认是false的
* @return
*/
@Query(nativeQuery = true , value = "select count(1) from teacher")
long countTeacherNumber();
使用Spring Data进行删除更新操作
我们之前都是写的查询操作,那么如果进行更新和删除操作,是不是也是一样的?
然而,请注意,并不是的,而且特别要注意下面两点:
(1)对于更新和删除操作,必须在接口的方法上面添加@Modifying注解,这样就用于标识这是一个修改的操作
(2)必须在调用这个接口方法的地方(一般就是service层)使用事务,即用@Transactional注解进行标识。
- dao接口
//================进行springdata的更新删除的处理======================
/**
* 根据老师表的id进行修改对应数据的老师名字
* 必须要添加@Modifying注解,并且要在调用的方法上添加事务注解@Transactional
* @param name
* @param id
*/
@Modifying
@Query("update Teacher t set t.name = ?1 where t.id = ?2")
void updateTeacherById(String name , Integer id);:
- service层代码
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import javax.transaction.Transactional;
import java.util.List;
/**
* @ Author :zhangbin
* @ Date :2019/05/20
*/
@Service
public class SpringDataService {
@Autowired
private TeacherRepository teacherRepository;
@Autowired
private TeacherCrudRespository teacherCrudRespository;
/**
* 根据id进行修改老师的名字
* @param name
* @param id
*/
@Transactional
public void updateTeacher(String name , Integer id){
teacherRepository.updateTeacherById(name , id);
}
}
CrudRepository
CrudRepository继承了Repository接口,并添加了些基本的增伤改查方法。
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package org.springframework.data.repository;
import java.util.Optional;
@NoRepositoryBean
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S var1);
<S extends T> Iterable<S> saveAll(Iterable<S> var1);
Optional<T> findById(ID var1);
boolean existsById(ID var1);
Iterable<T> findAll();
Iterable<T> findAllById(Iterable<ID> var1);
long count();
void deleteById(ID var1);
void delete(T var1);
void deleteAll(Iterable<? extends T> var1);
void deleteAll();
}
PagingAndSortingRepository
PagingAndSortingRepository继承了CrudRepository,并添加了分页方法。
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package org.springframework.data.repository;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
@NoRepositoryBean
public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort var1);
Page<T> findAll(Pageable var1);
}
要访问User页面大小为20 的第二页,您可以执行以下操作:
PagingAndSortingRepository<User, Long> repository = // … get access to a bean
Page<User> users = repository.findAll(PageRequest.of(1, 20));
// or
PageRequest pageRequest = new PageRequest(0, 5);
Page<Teacher> page = teacherPagingAndSortRespository.findAll(pageRequest);
// or
//按照id的降序进行排序
Sort.Order sortOrder = new Sort.Order(Sort.Direction.DESC, "id");
//构建排序对象
Sort sort = new Sort(sortOrder);
//把分页和排序对象放入参数
PageRequest pageRequest = new PageRequest(0, 5 , sort);
Page<Teacher> page = teacherPagingAndSortRespository.findAll(pageRequest);
JpaRepository
JpaRepository继承了PagingAndSortingRepository接口完善了分页排序的功能。
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package org.springframework.data.jpa.repository;
import java.util.List;
import org.springframework.data.domain.Example;
import org.springframework.data.domain.Sort;
import org.springframework.data.repository.NoRepositoryBean;
import org.springframework.data.repository.PagingAndSortingRepository;
import org.springframework.data.repository.query.QueryByExampleExecutor;
@NoRepositoryBean
public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
List<T> findAll();
List<T> findAll(Sort var1);
List<T> findAllById(Iterable<ID> var1);
<S extends T> List<S> saveAll(Iterable<S> var1);
void flush();
<S extends T> S saveAndFlush(S var1);
void deleteInBatch(Iterable<T> var1);
void deleteAllInBatch();
T getOne(ID var1);
<S extends T> List<S> findAll(Example<S> var1);
<S extends T> List<S> findAll(Example<S> var1, Sort var2);
}
接口继承JpaSpecificationExcutor接口
说明:不属于Repository体系,实现一组 JPA Criteria 查询相关的方法。Specification:封装 JPA Criteria 查询条件。通常使用匿名内部类的方式来创建该接口的对象。
主要接口方法如下:主要就是条件过滤,比如我们在分页的时候需要一些条件,这样就可以更好的进行分页处理。
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package org.springframework.data.jpa.repository;
import java.util.List;
import java.util.Optional;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
import org.springframework.data.jpa.domain.Specification;
import org.springframework.lang.Nullable;
public interface JpaSpecificationExecutor<T> {
Optional<T> findOne(@Nullable Specification<T> var1);
List<T> findAll(@Nullable Specification<T> var1);
Page<T> findAll(@Nullable Specification<T> var1, Pageable var2);
List<T> findAll(@Nullable Specification<T> var1, Sort var2);
long count(@Nullable Specification<T> var1);
}
示例代码如下:(用于实现分页和过滤的作用)
package com.hnu.scw.repository;
import com.hnu.scw.model.Teacher;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
import org.springframework.data.repository.PagingAndSortingRepository;
/**
* @ Author :zhangbin
* @ Date :2019/05/20
*/
public interface TeacherJpaSpecificationExecutorRepository extends PagingAndSortingRepository<Teacher , Integer> ,JpaSpecificationExecutor<Teacher >{
}
import jdk.nashorn.internal.runtime.Specialization;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Sort;
import org.springframework.data.jpa.domain.Specification;
import javax.persistence.criteria.*;
/**
* @ Author :zhangbin
* @ Date :2019/05/20
*/
public class JpaSpecificationExecutorService {
//用于操作老师实体的接口
@Autowired
private TeacherJpaSpecificationExecutorRepository teacherJpaSpecificationExecutorRepository;
/**
* 进行测试JpaSpecificationExecutor这个接口的相关方法
* 实现查询第一页的前五条数据根据id升序排序,并且id要大于20
*/
public List<Teacher> testJpaSpecificationExecutor(){
//设置分页要进行过滤的条件
Specification specification = new Specification<Teacher>(){
@Override
public Predicate toPredicate(Root<Teacher> root,
CriteriaQuery<?> criteriaQuery,
CriteriaBuilder criteriaBuilder) {
Path path = root.get("id");
//设置过滤条件为id大于20 ,其中的gt就是表示大于
Predicate predicate = criteriaBuilder.gt(path , 20);
return predicate;
}
};
//按照id的降序进行排序
Sort.Order sortOrder = new Sort.Order(Sort.Direction.ASC, "id");
//构建排序对象
Sort sort = new Sort(sortOrder);
PageRequest pageRequest = new PageRequest(0, 5 , sort);
//把分页和排序对象以及过滤对象放入参数
Page<Teacher> page = teacherJpaSpecificationExecutorRepository.findAll(specification ,pageRequest);
return page.getContent();
}
}
参考博客:https://blog.csdn.net/Cs_hnu_scw/article/details/80786161
参考资料:https://docs.spring.io/spring-data/jpa/docs/2.1.8.RELEASE/reference/html/