yolov3 loss函数探索(二):diou/ciou-darknet
yolov3 loss函数探索(二):diou/ciou-darknet
1.简介
IOU:IOU损失考虑检测框和目标框重叠面积。
GIOU:GIOU损失在IOU的基础上,解决边界框不重合时的问题。
DIOU:DIOU损失在IOU的基础上,考虑边界框中心距离的信息。
CIOU:CIOU损失在DIOU的基础上,考虑边界框宽高比的尺度信息。
GIOU相关资料:yolov3中loss函数的探索(一):ori-darknet、giou-darknet https://blog.csdn.net/qq_33270279/article/details/102631557
D/CIOU论文:https://arxiv.org/pdf/1911.08287.pdf
D/CIOU开源项目:https://github.com/Zzh-tju/DIoU-darknet
2.核心思想
(1)现存问题
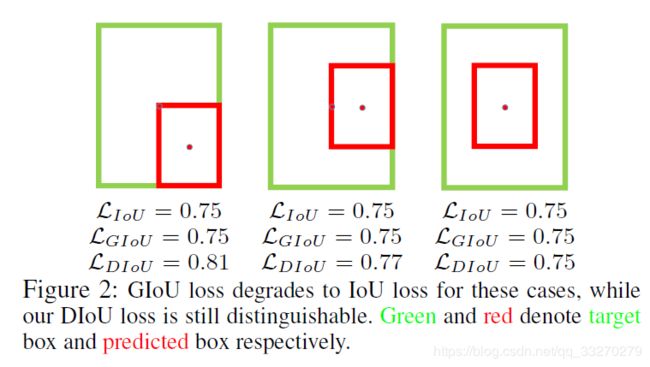
IOU、GIOU没有考虑真值框与预测框中心的之间的距离信息,实际情况下,中心点的距离越小框预测的越准。DIOU可以很好的反应中心点距离的情况,如下图所示:
(2)仿真验证
实验过程:
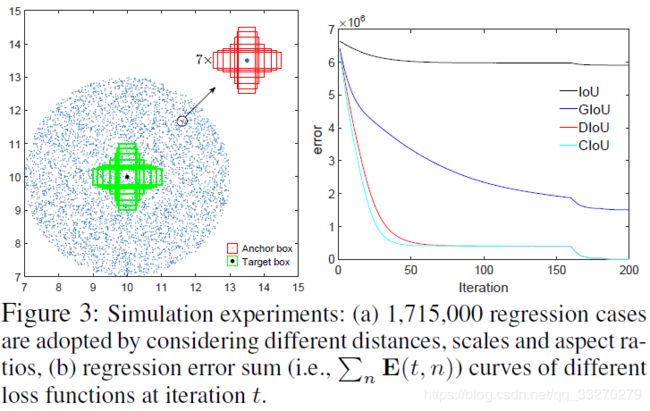
图3(a)展示仿真方案:
绿色框代表仿真实验需要回归的七个不同尺度的目标框,七个目标框的中心点坐标都是(10 * 10);
蓝色的点代表了所有anchor的中心点,中心点的分布如下图所示,各个方向都有,各种距离都有,当然每个anchor得一个中心点都包含有七个不同面积的anchor框。而且每个面积的anchor框又有不同的比例尺寸。因此一共有5000个蓝色点,有5000 * 7 * 7个anchor框,而且每个框都需要回归到7个目标框去,因此一共有5000 * 7 * 7 * 7个回归案例。
图3(b)展示实验结果:
不同loss函数迭代200次的实验结果,D/CIOU loss函数能够达到相同的loss值,但是CIOU收敛速度更快。
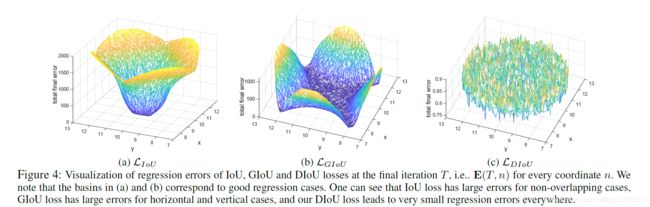
图4(a)(b)©立体展示误差的分布情况:
从图中可以得到以下结论:
一:IoU:从IoU误差的曲线我们可以发现,anchor越靠近边缘,误差越大,那些与目标框没有重叠的anchor基本无法回归。
二:GIoU:从GIoU误差的曲线我们可以发现,对于一些没有重叠的anchor,GIoU的表现要比IoU更好。但是由于GIoU仍然严重的依赖IoU,因此在两个垂直方向,误差很大,基本很难收敛,这就是GIoU不稳定的原因。
在垂直和水平方向误差大的原因如下:

红框内部分:C为两个框的最小外接矩形,此部分表征除去两个框的其余面积,相同的中距离的情况下,水平垂直方向时,此部分面积最小,对loss的贡献也就越小,从而导致在垂直水平方向上回归效果较差。
三:DIoU:从DIoU误差的曲线我们可以发现,对于不同距离,方向,面积和比例的anchor,DIoU都能做到较好的回归。
问题分析:

再用一张很形象的图,来说明GIoU不稳定以及收敛很慢的原因。上图中第一行三张图展示的是GIoU的回归过程,其中绿色框为目标框,黑色框为anchor,蓝色框为不同次数的迭代后,anchor的偏移结果。第二行三张图展示的是DIoU的回归过程,其中绿色框为目标框,黑色框为anchor,红色框为不同次数的迭代后,anchor的偏移结果。从图中我们可以看到,GIoU在回归的过程中,从损失函数的形式我们发现,当IoU为0时,GIoU会先尽可能让anchor能够和目标框产生重叠,当两个框产生包含关系时,GIoU会渐渐退化成IoU回归策略,因此整个过程会非常缓慢而且存在发散的风险。而DIoU考虑到anchor和目标之间的中心点距离,可以更快更有效更稳定的进行回归。
基于GIoU存在的问题,作者提出了两个问题:
a 直接最小化anchor框与目标框之间的归一化距离是否可行,以达到更快的收敛速度。
b 如何使回归在与目标框有重叠甚至包含时更准确、更快。
(3)DIoU
作者为了回答第一个问题:提出了Distance-IoU Loss
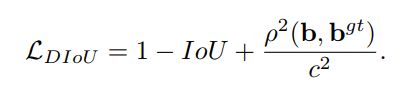
上述损失函数中,b,bgt分别代表了anchor框和目标框的中心点,且p代表的是计算两个中心点间的欧式距离。c代表的是能够同时覆盖anchor和目标框的最小矩形的对角线距离。因此DIoU中对anchor框和目标框之间的归一化距离进行了建模。直观的展示如下图所示。

DIoU的优点如下:
1.与GIoU loss类似,DIoU loss在与目标框不重叠时,仍然可以为边界框提供移动方向。
2.DIoU loss可以直接最小化两个目标框的距离,因此比GIoU loss收敛快得多。
3.对于包含两个框在水平方向和垂直方向上这种情况,DIoU损失可以使回归非常快,而GIoU损失几乎退化为IoU损失。
(4)CIoU
作者为了回答第二个问题:提出了Complete-IoU Loss
一个好的目标框回归损失应该考虑三个重要的几何因素:重叠面积、中心点距离、长宽比。
GIoU:为了归一化坐标尺度,利用IoU,并初步解决IoU为零的情况。
DIoU:DIoU损失同时考虑了边界框的重叠面积和中心点距离。
然而,anchor框和目标框之间的长宽比的一致性也是极其重要的。基于此,作者提出了Complete-IoU Loss。

上述损失函数中,CIoU比DIoU多出了阿尔法和v这两个参数。其中阿尔法是用于平衡比例的参数。v用来衡量anchor框和目标框之间的比例一致性。
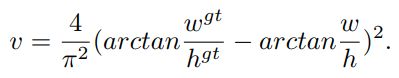

从阿尔法参数的定义可以看出,损失函数会更加倾向于往重叠区域增多方向优化,尤其是IoU为零的时候。
(5)Diou-nms
在CIOU loss函数的基础上,作者对比了origin-nms和Diou-nms,结果如下图:

如图所示,在每个置信度的情况下,Diou-nms都好于origin-nms函数。

如上图所示,重叠目标的检测效果,Diou-nms的效果也优于origin-nms。
(6)论文结果
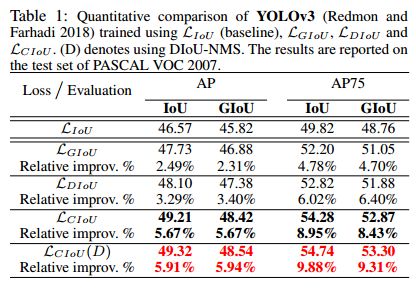
(D)代表后处理中采用Diou-nms函数。
3.源码解读
开源项目DIoU-darknet:https://github.com/Zzh-tju/DIoU-darknet
参考项目g-darknet:https://github.com/generalized-iou/g-darknet
1.工程变动:
cfg文件:
loss函数的类型可以通过文件中的iou_loss选项进行选择,在.cfg中的每[yolo]一层上指定。当前的有效选项是:[iou|giou|mse|diou|ciou]
iou_loss=mse #原始darknet loss函数类型(全部mse)
iou_loss=iou #x,y,w,h由mse损失函数换位box的iou-loss,confidence和class用mse。
iou_loss=giou #x,y,w,h由mse损失函数换位box的giou-loss,confidence和class用mse。
iou_loss=diou #x,y,w,h由mse损失函数换位box的diou-loss,confidence和class用mse。
iou_loss=ciou #x,y,w,h由mse损失函数换位box的ciou-loss,confidence和class用mse。新增不同维度loss函数的权重参数,表征其在总loss的重要程度,在.cfg中的每[yolo]一层上指定。具体如下:
cls_normalizer=1 #class和confidence的权重参数,默认值1
iou_normalizer=0.5 #box-iou的权重参数,默认值1。
#通过验证,以上参数的初始化为最优。新增不同nms函数的选择,在.cfg中的每[yolo]一层上指定。具体如下:
nms_kind=greedynms #原始nms函数,采用iou作为指标
nms_kind=diounms #采用Diou-nms函数,采用diou作为指标:DIoU = IoU - R_DIoU ^ {beta1}
beta1=0.6 #当选用diounms时,需要设置权重阈值。data文件:
classes= 20
train = ../train.txt
valid = ../valid.txt
names = data/xx.names
backup = backup
prefix = ciou #新增输出前缀参数。数据增强:
用AlexeyAB’s fork中的OpenCV实现的方式替换了原darknet中的数据加载和增强的方式。
数据增强函数在darknet\src\image_opencv.cpp中的image image_data_augmentation()。
注:其余操作与原darknet一致,请参考:Darknet-Yolov3训练自己的数据指导手册https://blog.csdn.net/qq_33270279/article/details/103151282,该工程剩余新增功能暂不做尝试
2.diou-nms源码解析:
代码位置(src\box.c),具体的变动,如下图所示:

DIoU = IoU - R_DIoU ^ {beta1}代码如下:

4.实验论证
1.训练自己的数据时,cls_normalizer,iou_normalizer的取值需要反复试验才能选取最佳阈值。
2.训练自己的数据时,会出现loss过大(梯度爆炸所致),导致训练的模型不能检出目标。log文件出现如下:
解决办法:
多尝试几次,会成功的(模型的初始权重随机)。
加载预训练模型。
在前1000次迭代过程中,添加限制梯度的阈值。
3.训练自己数据时,框的回归效果较于mse、giou,有明显提升(框稳定且准确),但样本较少的类别AP较低。