基于深度学习的立体匹配
目录
- 基于深度学习的立体匹配
- 1. 背景
- 2. 解决方案
- 2.1监督学习算法
- 2.1.1 PSM-Net
- 2.1.2 EdgeStereo
- 2.1.3 GwcNet
- 2.1.4 GA-Net
- 2.1.5 SSPCV-Net
- 2.1.6 WSM-Net
- 3. 算法验证及落地思考
- 3.1 算法的复现
- 3.2 Middleburry v3 评估
- 3.3 落地思考
基于深度学习的立体匹配
1. 背景
传统的立体匹配算法多围绕损失计算和视差优化进行研究:
-
设计良好的度量函数来计算匹配损失;
-
使用局部或全局的方法为每个像素分配视差值。
这些算法均采用人工设计的浅函数,对于病态区域(如纹理少的区域等)往往不能得到正确的结果。
2. 解决方案
- 基于监督学习的立体匹配方案(一般使用激光雷达获得样本准确的视差信息作为GroundTruth,样本的精度直接影响学习的效果。常用的数据集sceneFlow 数据集及kitti数据集)

- 基于非监督学习的立体匹配方案(无需样本的视差真值,只需要左右图像即可,左->视差<-右(三维数据相互验证,迭代训练实现))
论文《Unsupervised Learning of Stereo Matching》

2.1监督学习算法
基本思路:
网络结构主要由4个部分组成(特征提取、空间金字塔特征融合、匹配损失计算和视差回归)
•使用CNN分别对左右视角图像进行特征提取,并融合多尺度特征;
•连接左视角特征和平移的右视角特征,构建视差维度上稀疏的损失体,再使用3DCNN 学习并根据几何上下文信息计算匹配损失;
•重采样损失体到原始图片尺寸,用Softmax函数将损失值转化为视差概率分布,并通过视差回归函数输出亚像素的预测视差。
注:3D卷积的理解(https://www.jianshu.com/p/1bb8618dd7ae )
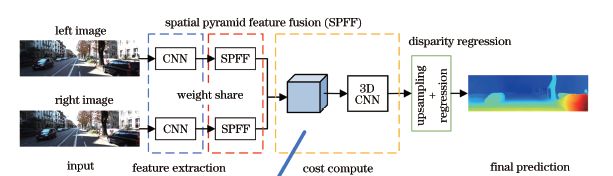
2.1.1 PSM-Net
Code(https://github.com/JiaRenChang/PSMNet)
•创新点1(红框)-- 引入了空间金字塔池化模块(spatial pyramid pooling,SPP)。用SPP聚合多尺度的信息。
•创新点2(黄匡)-- 堆叠漏斗网络(stacked hourglass networks),用3D卷积做的encoder-decoder结构。降低算力,融合多级特征。
| Error Rate-3 | Cost_time | device |
|---|---|---|
| 2.32 | 0.41s | Nvidia GTX Titan Xp |

2.1.2 EdgeStereo
网络不仅能够预测视差图,还训练一个边缘子网络预测边缘图,将边缘信息整合到主网络中,指导视差学习。
| Error Rate-3 | Cost_time | device |
|---|---|---|
| 2.08 | 0.32s | Nvidia GTX Titan Xp |

2.1.3 GwcNet
Code(https://github.com/xy-guo/GwcNet )
提出了“组相关”。所谓“Group-wise”就是对多通道的特征图沿着通道分组。比如文中实验部分提到的左右特征图是320通道的,就分为了40组,每组8个通道。组相关的计算是按照向量内积的方式,但是因为一组有多个通道,又不会丢失很多信息。
| Error Rate-3 | Cost_time | device |
|---|---|---|
| 2.11 | 0.32s | GPU @ 2.0 Ghz |

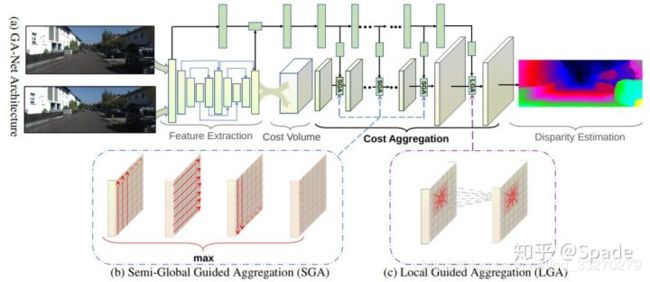
2.1.4 GA-Net
Code(https://github.com/feihuzhang/GANet )
本文主要针对立体匹配中的代价聚合(从得到cost volume到softmax回归计算视差这一部分)进行优化,传统方法就是堆叠的3D卷积,3D卷积的参数量是很高的。而本文中提出了两种网络层,用更少的参数就可以达到相同的效果。一种是对半全局匹配的修改,称为半全局聚合层(semi-global aggregation layer),另一种是局部指导的聚合层(local guided aggregation layer),也是借鉴传统立体匹配方法的代价滤波策略(后面会稍微具体地解释)。前者聚合全图多个方向的代价,使得在遮挡区域、低纹理区域也有较好的估计;后者聚合局部代价来处理那些较细的结构和物体边缘。
| Error Rate-3 | Cost_time | device |
|---|---|---|
| 1.81 | 1.8s | GPU @ 2.5 Ghz |
2.1.5 SSPCV-Net
•加入语义分割任务
•构建多个不同尺度的cost volume
•针对多个cost volume,提出一种融合方式
| Error Rate-3 | Cost_time | device |
|---|---|---|
| 2.11 | – | – |

2.1.6 WSM-Net
Code (https://github.com/wyf2017/WSMCnet )
提出一种在视差维度上使用稀疏损失体进行立体匹配的方法。采用宽步长平移右视角特征图构建稀疏的三维损失体,使三维卷积模块所需的显存和计算资源均降低数倍。采用多类别输出的方式对匹配损失在视差维度上进行非线性上采样,并结合两种损失函数训练模型,在保证运行效率的同时提高算法精度。在KITTI测试集上,与基准算法相比,所提算法不仅提高了精度,而且运行时间缩短了约40%。
| Error Rate-3 | Cost_time | device |
|---|---|---|
| 2.13 | 0.39s | GTX 1070 |

3. 算法验证及落地思考
3.1 算法的复现
测试数据集:kitti2015-train
测试网络:GA-Net;WSM-Net
| 网络名称 | 分辨率: W*H | EPE: 复现 | ER-1: 复现/BenchMark | ER-3: 复现/BenchMark | device: 复现/BenchMark | CostTime: 复现/BenchMark |
|---|---|---|---|---|---|---|
| GA-Net-deep | 1248*384 | 0.35 | 4.27/8.7 | 0.48/1.81 | 2080ti 11G /GPU @ 2.5 Ghz | 2.34/1.8 |
| GA-Net-11 | 1248*384 | 1.16/0.95 | 54.31 | 1.85 | 2080ti 11G /GPU @ 2.5 Ghz | 1.60/0.95 |
| WSMCnetEB_S2C3F32 | 768*384 | 0.74 | 5.85 | 2.08/2.13 | 2080ti 11G /GTX 1070 | 0.33/0.39 |
| WSMCnetEB_S3C3F32 | 768*384 | 0.84 | 7.39 | 2.61 | 2080ti 11G /GTX 1070 | 0.26 |
| WSMCnet | 768*384 | 0.73 | 5.83 | 2.13 | 2080ti 11G /GTX 1070 | 0.57 |
EEP表示预测视差与真值之间的差值绝对值。
ED1表示每组图像对评价区域的错误像素百分比,其中EEP小于3或者1pixel或EEP小于真值5%时,认为是正确像素,否则为错误像素。
GA-Net-n:n为3D卷积的数量。
*_SmCnF32:m为3D卷积稀疏步长;n为每个平移步长内,对匹配损失进行多类别预测的数。
3.2 Middleburry v3 评估
数据:Middleburry stereo Evaluationv3–Adirondack
模型:GA-Net-deep
模型分辨率:960*672
Kitti性能:
EPE Error:0.35
Error Rate1: 0.087
Error Rate3: 0.0181



…
结论:模型的鲁棒性不强,在新场景下,性能下降严重。
3.3 落地思考
- GA实时模型的速度对比:
device:TESLA P40 GPU
分辨率:1000*300
帧率:15-20

- 常见的立体匹配模型,算力达到1Tops,移动端的直接部署较难,也存在轻量级的模型如下表,效果能否接受还需验证(未找到开源项目)。
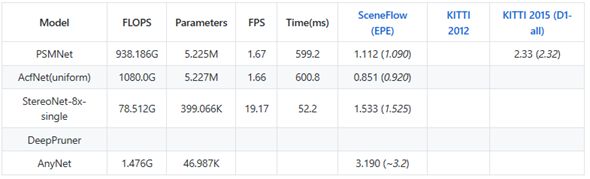
- 影响落地的两个因素性能和效率都不是很乐观,这方面的知识还需要深入学习和研究。
参考:https://www.zhihu.com/people/spade-66-82/posts(总结的非常到位)