爬虫demo:52nlp上的招聘求职数据
Created on 2020-02-10
@author 假如我年华正好
目的:爬取 我爱自然语言 网站上的 招聘求职数据
环境:Python 3
爬虫的两大步骤:
-
发送请求(request),获取数据(response)
向网址所在的服务器发送请求,即HTPP Request,服务器正常响应后会得到一个Response,其内容便是所要获取的页面内容。
使用工具:
requests模块 -
解析网页内容
使用工具:
BeautifulSoup模块 —— HTML/XML解析器- Beautiful Soup 主页
- Beautiful Soup 4.4.0 文档
分析目标网页
本文欲爬取 我爱自然语言 网站上的 招聘求职数据,主要有两个页面:第一为职位的列表页;第二为职位的详情页。示例如下:

在网页上,单击右键 —> 查看网页源代码,可以看到网页的html源码,我们通过 request 得到的内容就是这个。
而Beautiful Soup 可以将我的得到的复杂HTML文档,转换成一个复杂的树形结构,树每个节点都是Python对象。所有对象可以归纳为4种:Tag , NavigableString , BeautifulSoup ,Comment 。
下面对两个页面的源码进行分析:
(1)页面1:职位的列表页
先找到我们需要的内容所在部分,即职位列表的源码部分;

以其中一行为例,分析源码的结构:

分析发现:
- 职位列表的行的 tag 的名字为
div,其 class 有两种:class="row"和calss="row-alt"; - 职位类型(全职or实习)如何获取:div —> span —> img[“alt”] (div tag 下的 span tag 下的 img tag 的 alt 属性值)
- 职位详情页链接如何获取:div —> span —> a[“href”]
- 职位发布公司如何获取:
- 工作地点如何获取:
- 发布时间如何获取:div —> span.get_text()
下面用代码演示如何获取其中的内容:
import requests
from bs4 import BeautifulSoup
# 第一步:发送请求获取,获取数据
url = 'http://www.nlpjob.com/jobs'
resp = requests.get(url) # 发送请求
text = resp.content.decode("utf-8") # 解码
soup = BeautifulSoup(text, "html5lib") # 实例化成 BeautifulSoup 对象# 第二步:解析内容
# 获取所有行的 tag,返回为 bs 对象组成的列表 (对属性的限制方式有以下两种)
content = soup.find_all('div', class_="row-alt")
content += soup.find_all('div', attrs={'class': "row"})
# 以其中一行为例:
cont = content[0]
row_info = cont.find_all('span', class_="row-info")[0]
# 职位类型
job_type = cont.find_all('img')[0]['alt']
print(job_type)
# 详情链接
href = row_info.find_all('a')[0]['href']
print(href)
# 内容标题/摘要
title = row_info.find_all('a')[0].get_text() #.get_text() = .strings
print(title)
# 公司&工作地点
la = row_info.get_text()
print(la)
# 发布时间
time_posted = cont.find_all('span', class_="time-posted")[0].get_text()
print(time_posted)Out[9]:全职
http://www.nlpjob.com/job/61399/%e5%9b%be%e6%a3%ae%e6%9c%aa%e6%9d%a5%e7%a7%91%e6%8a%80%e6%9c%89%e9%99%90%e5%85%ac%e5%8f%b8-at-%e5%9b%be%e6%a3%ae%e6%9c%aa%e6%9d%a5%e7%a7%91%e6%8a%80%e6%9c%89%e9%99%90%e5%85%ac%e5%8f%b8/
图森未来科技有限公司
图森未来科技有限公司 at 图森未来科技有限公司, 不限地址
2020-02-07
注意:列表页的翻页问题

发现不同页只是url最后面的 ?p= 不一样,所以本文采取:写个循环,直接按规律修改 url ,循环爬取不同页。
(2)页面2:职位的详情页
详情页内容比较单纯,只需爬取职位描述:

演示代码如下:
detail_url = "http://www.nlpjob.com/job/61376/"
resp = requests.get(detail_url)
text = resp.content.decode("utf-8")
soup = BeautifulSoup(text, "html5lib")
job_description = soup.find('div', id='job-description')
job_description.get_text().replace('\t', '')完整代码
以下为 demo 的完整代码,其中对html源码的解析的大逻辑前文已经介绍,部分细节不再详述。
本文只爬取了2019年以后的职位信息(1-28页),,
每一页耗时约1分钟,,
如下:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import pandas as pd
import re
import requests
from bs4 import BeautifulSoup
import time
def mul_delimiters_split(text, *dels):
'''多个分隔符对字符串进行分割,并且分隔符可以是长短不一的'''
delimiters = dels
regexPattern = '|'.join(map(re.escape, delimiters)) # 'a|\\.\\.\\.|\\(C\\)'
return re.split(regexPattern, text)
def parse_url_list(url):
'''
爬取并解析职位列表页面数据
'''
resp = requests.get(url)
text = resp.content.decode("utf-8")
soup = BeautifulSoup(text, "html5lib")
data = []
content = soup.find_all('div', class_="row-alt")
content += soup.find_all('div', attrs={'class': "row"})
for cont in content:
# 发布时间
time_posted = cont.find_all('span', class_="time-posted")[0].get_text()
time_posted = time_posted.replace(' ', '', )
row_info = cont.find_all('span', class_="row-info")[0]
# 职位类型
job_type = row_info.find_all('img')[0]['alt']
# 详情链接
href = row_info.find_all('a')[0]['href']
# 内容标题/摘要
title = row_info.find_all('a')[0].get_text() #.get_text() = .strings
# 公司&工作地点
la = mul_delimiters_split(row_info.get_text(), ' at ', ' in ', ', ')[1:]
# 储存结果
result = {'time_posted': time_posted,
'job_type': job_type,
'href': href,
'job_description': parse_url_detail(href),
'title': title,
'company': la[0],
'location': la[1].replace('\t', '')
}
data.append(result)
return pd.DataFrame(data)
def parse_url_detail(detail_url):
'''
爬取并解析职位详情页数据
'''
resp = requests.get(detail_url)
text = resp.content.decode("utf-8")
soup = BeautifulSoup(text, "html5lib")
job_description = soup.find('div', id='job-description')
return job_description.get_text().replace('\t', '')
def main():
urls = ["http://www.nlpjob.com/jobs/?p=" + str(i) for i in range(1, 28)]
data = pd.DataFrame()
for url in urls:
s = time.time()
print('正在爬取' + url + ' ...')
temp = parse_url_list(url)
data = data.append(temp)
print('完成!耗时 %s' %(time.time() - s))
# 保存
data.to_csv('../data/jobs.csv')
return data
if __name__ == '__main__':
data = main()最后的结果示例:
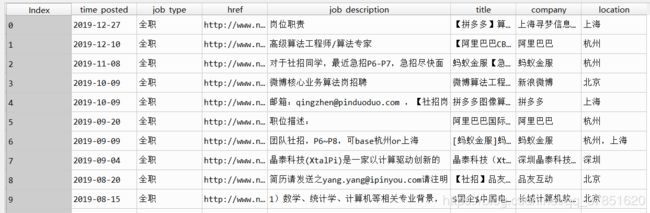
-------完--------