紧接上文所述,在这篇文章中我将对Mapper映射文件进行详细的说明。
Mapper映射文件是一个xml格式文件,必须遵循相应的dtd文件规范,如ibatis-3-mapper.dtd。我们先大体上看看支持哪些配置?如下所示,从Eclipse里截了个屏:
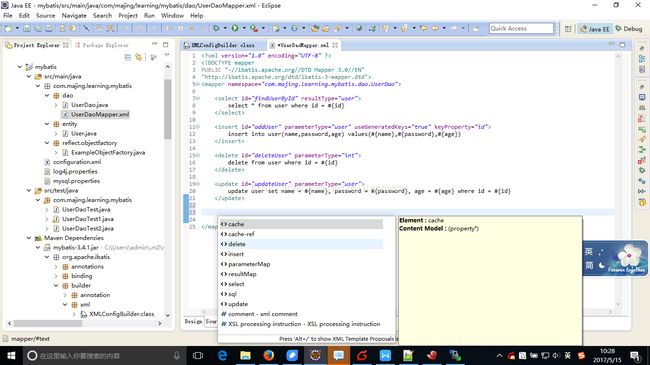
从上图可以看出,映射文件是以
下文中,我们将首先对增删改进行描述,然后对查进行详细说明,最后对其他五个元素进行简单说明。
(1)insert、update、delete
我们先从配置文件看起:
id="addUser" parameterType="user" flushCache="true" statementType="PREPARED" keyProperty="" keyColumn="" useGeneratedKeys="false" timeout="20">
上面给出了一个比较全面的配置说明,但是在实际使用过程中并不需要都进行配置,可根据自己的需要删除部分配置项。
在这里,我列举出我自己的配置文件,精简之后是这样的:
insert into user(name,password,age) values(#{name},#{password},#{age}) delete from user where id = #{id} update user set name = #{name}, password = #{password}, age = #{age} where id = #{id}
这里的parameterType设置成user是因为如果不设置的情况下,会自动将类名首字母小写后的名称,原来的类名为User。不过,建议大家还是使用typeAlias进行配置吧。唯一需要说明的就是
在数据库里面经常性的会给数据库表设置一个自增长的列作为主键,如果我们操作数据库后希望能够获取这个主键该怎么弄呢?正如上面所述,如果是支持自增长的数据库,如mysql数据库,那么只需要设置useGeneratedKeys和keyProperties属性便可以了,但是对于不支持自增长的数据库(如oracle)该怎么办呢?
mybatis里面在
keyProperty="id" resultType="int" order="BEFORE" statementType="PREPARED">
针对不能使用自增长特性的数据库,可以使用下面的配置来实现相同的功能:
select seq_user_id.nextval as id from dual insert into user(id, name, password, age, deleteFlag) values(#{id}, #{name}, #{password}, #{age}, #{deleteFlag})
讲完了insert、update、delete,接下来我们看看用的比较多的select。
(2)select、resultType、resultMap
我们先来看看select元素都有哪些配置可以设置:
我们还是从具体的示例来看看,
这里我们根据用户id去查询这个用户的信息,resultType=User是一个别名,如果我们接触到的是这种一对一的问题,那么可以简单的定义一个实体,这个实体代表数据库表中的一条记录即可。但是如果我们遇到一对多的问题呢,就拿这里的查询用户信息来说,如果每个用户有各种兴趣,需要维护每个用户的兴趣信息,那么我们可能就存在下面的数据表结构:
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) NOT NULL, `password` varchar(255) NOT NULL, `age` int(3) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8; CREATE TABLE `userinterests` ( `userid` int(11) DEFAULT NULL, `interestid` int(11) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `interests` ( `interestid` int(11) NOT NULL, `interestname` varchar(255) DEFAULT NULL, PRIMARY KEY (`interestid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
其中user表用于记录用户信息,interests表用于维护所有的兴趣标签,而userinterests用于维护每个用户的兴趣情况。
这时候,如果我们需要根据用户id去查询用户的信息和兴趣信息该怎么做呢?这时候我们就要用到
在配置查询的返回结果时,resultType和resultMap是二选一的操作。对于比较复杂的查询结果,一般都会设置成resultMap。
resultMap该怎么配置呢?又支持哪些配置呢?我们看看下面:
根据上面的说明,我们来看看之前的问题怎么解决?
先截图给出三个表的数据情况:



接着,我们来定义兴趣类,并改写之前的用户实体类
package com.majing.learning.mybatis.entity;
public class Interests {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Interests [id=" + id + ", name=" + name + "]";
}
}
package com.majing.learning.mybatis.entity;
import java.util.List;
public class User2 {
private int id;
private String name;
private String password;
private int age;
private List interests;
private String author;
public List getInterests() {
return interests;
}
public void setInterests(List interests) {
this.interests = interests;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User2 [id=" + id + ", name=" + name + ", password=" + password + ", age=" + age + ", interests=" + interests + ", author=" + author + "]";
}
}
紧接着,我们改写Dao接口:
package com.majing.learning.mybatis.dao;
import com.majing.learning.mybatis.entity.User2;
public interface UserDao2 {
/**
* 查询
* @param userId
* @return
*/
User2 findUserById (int userId);
}
然后,我们给相关实体类创建一下别名:
然后再创建一个对应跟UserDao2对应的Mapper映射文件:
最后将这个映射文件添加到
下面我们来写个测试代码来测试一下是否可以正常运行:
public class UserDaoTest3 {
@Test
public void testFindUserById(){
SqlSession sqlSession = getSessionFactory().openSession(true);
UserDao2 userMapper = sqlSession.getMapper(UserDao2.class);
User2 user = userMapper.findUserById(10);
System.out.println("记录为:"+user);
}
// Mybatis 通过SqlSessionFactory获取SqlSession, 然后才能通过SqlSession与数据库进行交互
private static SqlSessionFactory getSessionFactory() {
SqlSessionFactory sessionFactory = null;
String resource = "configuration.xml";
try {
sessionFactory = new SqlSessionFactoryBuilder().build(Resources.getResourceAsReader(resource));
} catch (IOException e) {
e.printStackTrace();
}
return sessionFactory;
}
}
运行代码后,我们可以看到成功啦!
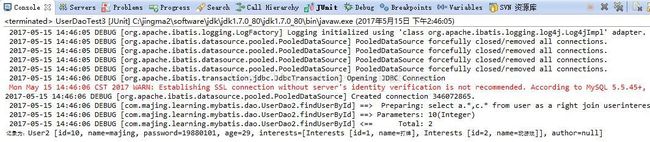
(3)sql
sql元素的意义,在于我们可以定义一串SQL语句,其他的语句可以通过引用它而达到复用它的目的。因为平时用到的也不多,这里就不多介绍了,感兴趣的朋友可以自行查阅资料了解一下。
(4)cache、cache-ref
关于缓存的这块逻辑还没有研究过,后面专门写篇文章针对缓存进行针对性的说明,敬请关注。
到此这篇关于Mybatis中Mapper映射文件使用详解的文章就介绍到这了,更多相关Mybatis Mapper映射文件内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!