看懂这篇文章你就能理解索引了!!!
从数据结构底层彻底理解Mysql索引
- 前言
- 索引数据结构红黑树,hash,B+树详解
- 聚簇索引&聚集索引&稀疏索引到底是什么
- 为什么推荐InnoDB表必须建主键?并且推荐整形自增?
- 为什么非主键索引结构叶子节点存储的是主键值?
- 什么是回表?
- 联合索引底层数据结构什么样
- 小结
前言
其实最近学了很久,一直想写点什么。这次 开始写个mysql专题,从mysql索引底层开始写,然后是explain,索引优化,索引设计,sql优化,mysql锁等等;分库分表的以后会写。
索引数据结构红黑树,hash,B+树详解
先了解索引的本质到底是什么:
索引是帮助MySQL高效获取数据的排好的数据结构。
那么索引的数据结构可以有哪些类型呢,我们在这里一步一步往下分析。

比如说 select * from t where t.Col2=89,这条sql语句它会从上往下一条一条去找,大家可能会觉得它们靠的很近,其实不是这样;大家知道数据是存到磁盘上去了,第一次存的时候存到了1个点位,下次存的时候的点位不一定是挨着的了。因为写下条数据可能过了几天,这其中有程序把中间的写满了,导致会出现俩个点位差的很远。换句话说其实就是数据表在磁盘上面是随机分布的。
我们在磁盘上面拿数据会和磁盘做次交互,也就是1次IO。1次磁盘IO读取效率是不高的,所以就这样1次1次去做磁盘IO读取表的数据,去做比对。查找回收很低效的,所以要减少查找次数。这个时候索引就上场了。
那么我们可以把Col2建个索引,那索引其实就是一种数据结构
-
二叉树
我们可以拿Col2这列做个索引,key是索引字段的值,value是值所在的磁盘文件地址,例如77就是key,0x56就是对应的value。

那么我们把索引数据放到二叉树里。
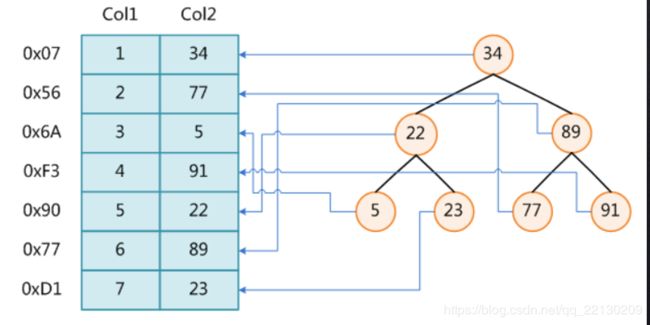
二叉树特点就是左边的小于根节点,右边的大于根节点,比如说我们查找89,经过2次比对,发现找到了。所以用二叉树查找会比单纯的全表扫描效率高。(这里的二叉树认为是二叉搜素树)但是会有缺点:
如果我们查找的Col1,他是顺序的,这种数据放到二叉树里会和链表一样,是1个瘸腿二叉树
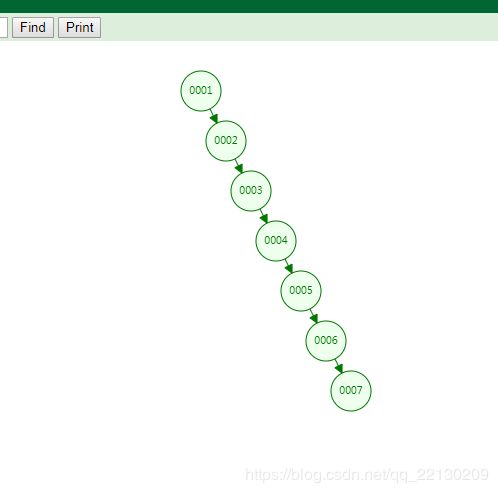
这种查找效率是非常慢的,和全表扫描没什么区别。 -
红黑树

再次查找6的时候发现,3次就找到了。那么为什么mysql索引没选择这种呢?
其实还是因为树的深度决定的。
我们工作中的表数据会很大,比如我们有500万行数据,树的高度可能会几十行。假设我们树的高度是20行,假如我们要查找的元素在叶子结点,从根节点出发我们要遍历20次查找才能找到。
20次磁盘IO效率也会非常低,这样肯定是不行的。
其实问题的本质是和树的高度紧密相关。2-3层高度还是可接受的。 -
Hash
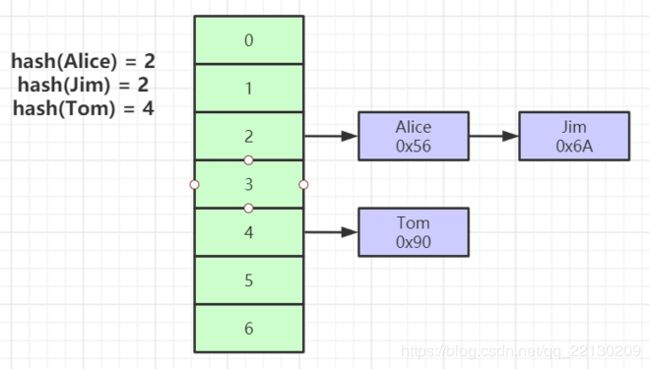
比如Col2作为hash索引,经过hash计算,放到相应地方。对索引的key进行一次hash计算就可以定位出数据存储的位置。按道理来说hash效率更高些,但是99%情况不是,hash索引仅能满足 “=”,“IN”,不支持范围查询,还有hash冲突问题。 -
B树
我们可以把横向放的索引元素越多,那么树的深度就会越少。

一个大的结点放很多索引元素。data是索引文件所在的磁盘的地址,小节点就是K-V特点:叶节点具有相同的深度,叶节点的指针为空 所有索引元素不重复 节点中的数据索引从左到右递增排列其实mysql里也没用这种,而是用到了它的变种B+树
-
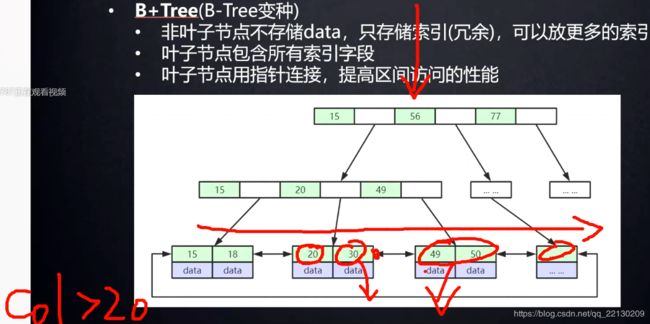
B+树(重点来了);

我们可以看到,B+树种非叶子结点都是没有data了,都放到了叶子结点里。
意味着叶子结点有我们这张表的所有索引。
特点: 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引。
叶子节点用指针连接,提高区间访问的性能。
它的每一个结点从左到右是有序的,这一点B树也是具备的。这就是排好序。
那么我们看下查找过程
比如查找30,会从根节点开始。进行1次磁盘IO找到,把它load到内存去。

拿30去内存里做比对,通过二分查找,快速定位,发现在15和56之间。那么找到了

进行一次磁盘IO找到这一页数据,我们把它加载到内存,发现介于20-49之间,继续往下。

进行一次磁盘IO找到,把这个叶子结点load到内存进行比对,发现找到,再把30对应的磁盘文件地址去磁盘上找这一行数据。
1次磁盘IO的时间是远大于在内存中比对的时间的。那么可不可以把所有索引元素的数据都放到根节点上呢?这样岂不是1次磁盘IO,加载到内存中比对即可吗?
肯定是不行的,因为这样在数据量巨大的情况下,会瞬间使内存使用率过高,把内存撑爆,并且也不会很快,而且1次磁盘IO也弄不了这么多数据。
之前的红黑树是因为高度太高,那么B+树真的解决了高度的问题了吗。
是真的解决了,mysql认为每个结点就是1个页,默认1页的大小是16KB。那么我们可以估算下3层高度能存储多少数据。
一张表假设用bigint做主键,8B,1个地址大概是6B。那么1页是16KB,可以存放16KB/14B=1170个结点。第二层同理1170个,那么叶子结点, 最多也就1KB,这个叶结点16个。那么一共放
最多也就1KB,这个叶结点16个。那么一共放
1170x1170x16=2190万。这样的数据量也就用了3行。经过了3次磁盘IO就找到了元素。
mysql会把根节点常驻内存,那就更快了。高版本会把所有非叶子结点加载到内存,那么可能也就1次磁盘IO把叶子结点加到内存。
那么mysql索引为什么选择B+树而不选择B树?

1.树的高度决定的。
我们估算小B+树存储2000多万数据得多高,每个结点16个元素,(默认每个结点还是16KB,1个结点1KB大小),取16为底2000万的对数得到是8层,可以看到存储相同数据量,B+树仅用3层。
B+树的高度是非叶子结点能存储多少索引元素确定的。
2.B+树可以很好的支持范围查找
假设我们找Col1大于20小于50,从根节点出发,找到叶子结点,从20出发拿出来根据指针定位到下个结点,这样一直拿,就可以了,找到50就不需要再找了。
这也就解释了,指针可以提高区间的访问性。B树没有指针,找完20,会继续从根节点往下找,效率会低得多。mysql的叶子结点指针是双箭头,对传统B+树做了优化。
这就是B树和B+树两个重要区别
聚簇索引&聚集索引&稀疏索引到底是什么
索引是存放到磁盘上的,可以看下他们什么样,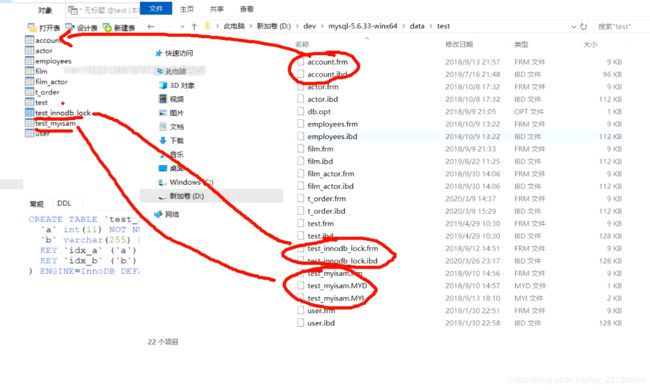
mysql存储引擎是形容数据库表的,用的比较多的为InnoDB和MyISAM俩种。
MyISAM索引文件和数据文件是分离的(非聚集)
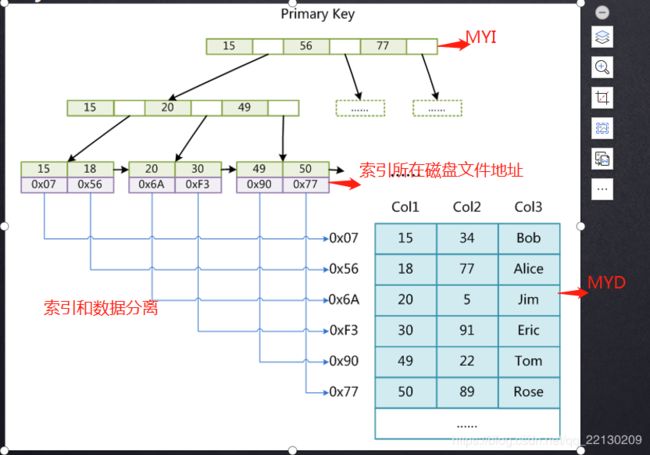
这种结构就是稀疏索引(非聚集索引)
InnoDB引擎
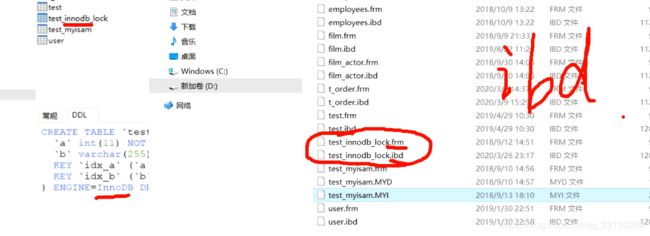
数据和索引是在一起的,如下图
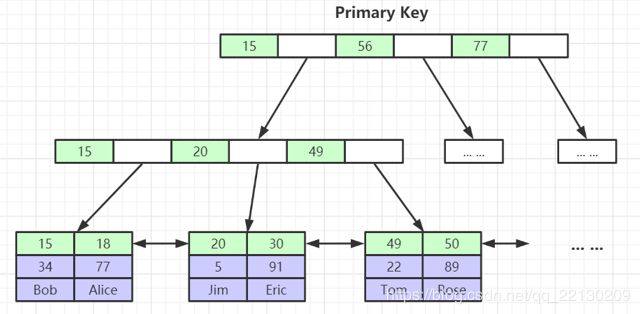
区别就是叶子存放的是正行数据,而MyISAM存放的是磁盘文件地址。
由此可以看出聚集索引和非聚集索引的区别了:索引和数据分开存储的——非聚集索引(稀疏),一起存储的就是聚集(聚簇)索引。
那么单从索引角度来说,是聚集索引快,还是非聚集索引快?
聚集的还是要快点。非聚集索引先从MYI文件拿到地址,再从MYD文件取数据,相当于跨文件去查找。
为什么推荐InnoDB表必须建主键?并且推荐整形自增?
从上边的聚集索引结构可以看出,InnoDB以B+树组织,如果有主键,这张表自带主键索引。那就可以用主键组织这张表的所有数据。那么如果不见主键,mysql该如何去做呢?它会从第一例找一列,数据不重复唯一的列,作为主键,用这一列索引数据来组织B+树。如果没选到,mysql会建个隐藏列,类似于rowid一样。mysql数据库资源是非常宝贵的,这种事情肯定是我们自己做的。
第2个问题,先说下为什么是整型?查找数据从根节点出发,会经过很多次比对。那么整型比大小肯定比字符串比大小快,字符串比较按照ASCII码;还有整型占用的空间比字符串的要小。
为什么推荐自增
我们看下不自增的情况:

如果不是自增的,根据B+树特点,会进行分裂和平衡。如果是自增的相当于一直往后边加。所以自增效率高。
为什么非主键索引结构叶子节点存储的是主键值?

对于MyISAM引擎来说没什么区别。对于InnoDB来说:
注意看图:非叶子结点和主键索引的没什么区别。叶子结点存的是主键。为什么2级索引不能把数据都放到叶子结点?
1.节约存储空间,如果有3,4个索引就要放3,4份数据。肯定是浪费空间的。
2.一致性。都放到叶子结点,插入数据时,主键索引和2级索引都要插完之后才能认为成功。如果有一处不成功就会有问题。如果叶子结点存主键,可以先让主键索引插入数据成功,再把主键放到这边来,减少复杂度。
二级索引其实也是非聚集索引,他会先找到叶子结点主键,然后回表去主键索引找到数据。
什么是回表?
ibd文件里,用二级索引去查,假设查找Alice,根据B+树结构快速定位到叶子结点拿到主键,再去回到主键索引里去找,定位到相应数据。

可以把聚集索引当做整张表,这就是回表的概念。
联合索引底层数据结构什么样
一张表是不推荐建很多单值索引,一般是建2-3个联合索引。以后我会写如何设计联合索引,那么我们看下底层数据
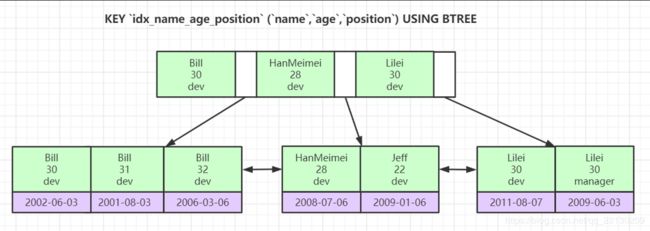
这里演示了下3个字段的联合索引,这里面涉及到了索引最左前缀原理,会按照索引建立的先后顺序。这里按照name,age,position,比如查找HanMeiei,HanMeimei
这里举个例子:

哪些字段会走索引呢?第1个会走,2和3语句不会走。
还是看上边的联合索引数据结构图,发现name和age是能通过索引树找到的,而第2条数据,跳过name在整张表里age就不是排好序的。

如果排好序第一个30找到就不用找了,但是跳过第一个字段就不是了,进行了全表扫描。
第3条也是如此。这也就是最左前缀原则的原理。
小结
本章主要是介绍了下mysql的底层数据结构。这对于理解索引优化很重要。下章节会开始进行Explain解释,以及后续的索引优化。