论文笔记:NSGA-Net: Neural Architecture Search using Multi-Objective Genetic Algorithm
NSGA-Net: Neural Architecture Search using Multi-Objective Genetic Algorithm
来源:paper, code, MSU, GECCO-2019, first Submitted on 8 Oct 2018
词汇:
Words Meaning genetic algorithm 遗传算法 mutation 突变 crossover 互换,交叉 population 种群
摘要
设计目标:
- 考虑多重和复杂目标的方法
- 有效平衡在神经网络潜在空间中的探索和利用
- 在一次运行中寻找多个不同的权衡网络架构
NSGA-Net 是一个基于种群的搜索算法,分三步探索可能的神经网络结构空间
- 种群初始化,基于来自人工设计结构的先验知识
- 探索,比较结构之间的互换与突变
- 利用,通过贝叶斯网络的形式使用存储在整个神经结构评价历史中的隐藏的有用信息
希望同时优化错误评价函数和计算复杂性
Introduction
此前使用的 NAS 方法:
- STOA 的增强学习方法需要消耗大量的计算,对于都多空间的利用是低效的
- 基于梯度下降的方法只关注单目标的评价函数最小化,多余多重的、复杂的目标不是很适合
- 大多数 STOA 方法搜索一个计算 block,然后通过足够次数的重复来完成网络
NSGA-Net 的显著特征在于:
- 多目标优化:现实应用中 NAS 需要小的网络,同时保证准确性
- 灵活的结构搜索空间:NSGA-Net 在整个网络结构中搜索,通过重复 block 对于不同的任务可能得不到最优解
- 非主导排序:NSGA-Net 最核心的模块就是 Non-Dominated Sorting Genetic Algorithm Ⅱ (NSGA-Ⅱ),一个多目标优化算法
- 高效再结合:相比较之前的方法,本文在使用突变(mutation)的同时还使用了互换(crossover),来向着多目标进行网络结合
- 贝叶斯学习:使用贝叶斯优化算法(BOA)来完全利用搜索历史存档中有希望的解决方案,以及网络结构层之间的相互关联
Related Work
县有关的 NAS 方法可以大体被分为两种:进化算法(evolutionary algorithm) 和 增强学习(reinforcement learning) 。
- 进化算法将网络结构设计看做组合优化问题,考虑多重目标得到的方案作为一个种群(population),在这个种群上做小的突变和迁移,得到最优化的方案
- 增强学习将网络构建看做一个决策问题,训练一个代理(agent)以特定的顺序最优化地选择网络
Reinforcement Learning
Q-learning -> MetaQNN ( ϵ \epsilon ϵ-贪心 Q-learning方法) -> BlockQNN (设计计算 block,通过重复 block 提高精度)
一种策略梯度方法试图近似一些不可区分的回馈函数来训练要求参数梯度的模型。训练一个递归神经网络控制器来构建网络,原始的方法使用控制器一次生成整个网络。这个方法超越了前人的方法——设计一个卷积核pooling的 block 进行重复来构建网络(NASNet)。
NSGA-Net 区别于 RL 方法在于使用了不止一个选择评价方式,即使用对于任务的准确性(而不是估计准确性)以及计算复杂度。NSGA-Net 不仅搜索 block,而且搜索 block 之间的组合。
Evolutionary Algorithms
neuroevolution of augmenting topologies (NEAT) algorithm
AmoebaNet,概率的引入使得简单的进化算法的大规模应用成为可能,这个方法比 RL 和随机搜索有更快的收敛速度。
从理念上来讲,NSGA-Net更接近 Genetic CNN 算法,使用二值编码表示卷积 block 之间的链接。在 NSGA-Net 中,通过以下两种方式增加了原有的编码和遗传操作:
- 对于残差链接增加额外的位
- 使用成对的互换(crossover)
此外,本文还引入了基于多目标的选择框架。相较于 Genetic CNN,本文还使用了贝叶斯网络来完全利用历史的种群知识
进化式多目标优化(EMO)方法——NSGA-Ⅱ 在本文中广泛使用。提出者只使用此方法在超参数和小的结构集合中搜索。网络态射(morphism)使得网络在保持功能等价性的前提下被扩展和加深,这对于结构搜索来讲,使得网络结构发生微小扰动之后的参数共享变得简单。
态射(morphism) 是两个数学结构之间保持结构的一种过程抽象。
最常见的这种过程的例子是在某种意义上保持结构的函数或映射。例如,在集合论中,态射就是函数;在群论中,它们是群同态;而在拓扑学中,它们是连续函数;在泛代数(universal algebra)的范围,态射通常就是同态。
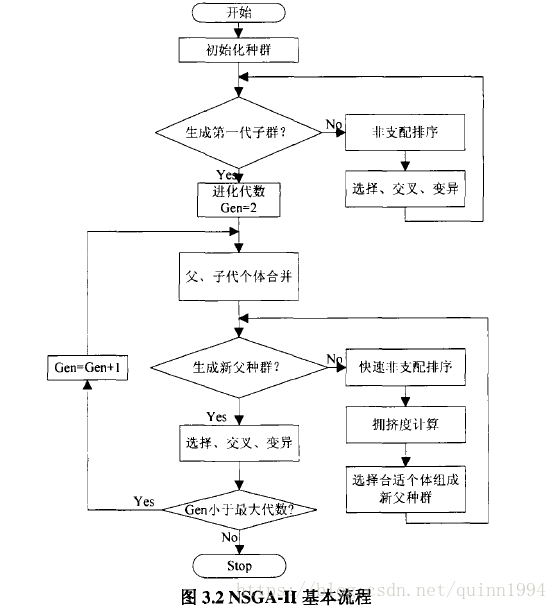
NSGA-Ⅱ算法
讲解及图片来源:遗传算法关于多目标优化python(详解)
其他方法
- 渐进式扩张网络,从简单的 cell 开始,并且只训练通过 RNN meta-model 得到的编码空间中预测结果中最好的 K 个网络
- 将上述方法扩展到多目标,基于网络的帕累托最优性(Pareto-optimality)比较网络
- 使用 meta-modeling 方法生成模型,这样的模型可能是临时的,并不分析渐进式搜索如何影响权衡边界
- 使用上坡算法和网络态射,在有限的资源上快速优化网络
- 结合 RL 和 EA 的思想,考虑大量网络的突变和联赛选择(tournament selection),并设置递归网络作为控制器,对这些网络施加突变效果
- 扩展式的随机搜索优化,针对易于分割应用
- 基于高斯过程的网络结构优化方法,通过贝叶斯优化的角度来观察
以上,作者对多种方法进行了简要介绍。综合来看,作者的思路来源有以下几个方面
- RL 方法,评价方式的拓展,此前很少有考虑多目标优化的,即使有效果也不理想
- NASNet,模块化的思考方式是对问题的简化,但作者加入了衡量模块间结合方式的因素
- Genetic CNN,二值的encoding方法,并且针对一些特殊的部分调整的encoding(残差和crossover)
- 贝叶斯网络,这一点应该是借鉴自RL但和EA显著不同
- NSGA-Ⅱ,这个算法的使用似乎和网络态射有关,能够更加有效地完成模型调整时的参数迁移问题
方法
NSGA-Net 一个基于遗传算法的架构搜索方法,可以自动生成一个 DNN 架构的集合,在图像分类任务上逼近一个性能和复杂性的帕累托最优。
帕雷托最优的状态就是不可能再有更多的帕雷托改善的状态;换句话说,不可能在不使任何其他人不受损的情况下再改善某些人的境况。即 trade-off 影响下的最优模式。
整体的网络结构为:

编码(Encoding)
和其他生物启发的搜索算法一样,遗传算法不直接在表型上进行操作。
- 将DNN结构看做表现型(phenotype)
- 将映射到相应结构的表征作为基因型(genotype)
- 将表现型和基因型之间的接口称作编码(encoding)
NSGA-Net 中将每一个计算块称作 phase,使用 Genetic CNN 中提出的方法,在其基础上增加了一位表示跳过链接。本文将这个操作称为 Operation Encoding x o \mathbf{x_{o}} xo。
Operation Encoding x o \mathbf{x_{o}} xo
本文中并不使用重复单一模块的方式构建网络,网络中的操作被编码表示为 x o = ( x o ( 1 ) , x o ( 2 ) , . . . , x o ( n p ) ) \mathbf{x_{o}=\big(x_{o}^{(1)},x_{o}^{(2)},...,x_{o}^{(n_{p})}\big)} xo=(xo(1),xo(2),...,xo(np)) ,其中 n p n_{p} np 表示 phase 的数量,每一个 x o ( i ) \mathbf{x_{o}^{(i)}} xo(i) 对一个有向无环图进行编码,这个图中包含 n o n_{o} no 个节点,每个节点使用一个二值串描述一个 phase 中的操作。即,一个节点就是一个基本的运算单元:卷积,池化,BN 或者顺序操作 。
这样的编码方式为网络结构提供了一种紧凑的编码,并且对于表示现有的手工设计的网络来讲足够的灵活。

编码方式:由有向无环图的拓扑排序性质,将节点进行排序,按照排序先后分别进行编码,节点 n n n 使用 n − 1 n-1 n−1 位表示,每一位表示该节点与前 n − 1 n-1 n−1 个节点是否连接(1/0);最后一位表示整个 block 是否包含跳过链接
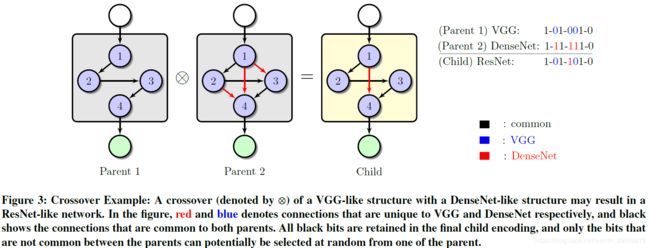
这张图展示的是遗传算法的交叉机制,即通过两个 parent 结构得到 child 结构——保留相同的部分,不同的部分随机选择 parent 一方的连接方式。
Search Space
通过余弦定义的空间分辨率降低方式,整个搜索空间的基因型由操作编码表示:
Ω x = Ω x o = n p × 2 n o ( n o − 1 ) / 2 + 1 \Omega_{\mathbf{x}}=\Omega_{\mathbf{x_{o}}}=n_{p}\times{2^{n_{o}(n_{o}-1)/2+1}} Ωx=Ωxo=np×2no(no−1)/2+1
即:每个 block 可能数量的和
处于计算复杂性的考虑,本文限制每个节点中的顺序操作是一致的,比如R-N-A。因此,节点和节点之间都是相同的,即每个节点都可以互换,这样就使得 编码不再具有一一映射的性质,而是一个多对一的映射(编码->结构) 。因为多对一映射的性质,消除映射到统一结构的编码(文中描述为相同表现型的不同基因型)变得比较关键。文中作者设计了一个 去重算法 (文章附录)。
每个 phase 的节点最大数量为 n o n_{o} no
搜索步骤 Search Procedure
NSGA-Net 是一个迭代的步骤,利用种群使得初始的解决方案逐渐变得更好。在每次迭代中,从种群中选择 parents 产生相同数量的后代,每一个种群成员都要计算下一次迭代的 survival 和 reproduction。初始的种群被随机产生或者使用先验知识。然后采用 exploration 和 exploitation 两步完成。
探索 Exploration
这步的目标是发现多种不同的节点连接方式来形成 phase。通过遗传操作——交叉和变异——来实现。
交叉 Crossover
基于种群的搜索方法中,潜在的并行在种群成员高效的共享 构造单元(building-block) 的过程中(通过 crossover)可以被利用。在 NAS 的背景下,phase 或者 phase 中的子结构可以被看做是构造单元。
本文设计了一个同质的交叉算子,将两个选中的种群成员作为 parents,通过对来自 parents 的构造单元的继承和结合来产生后代。其关键点在于:
- 通过在编码向量中继承父母相同的位来保持父母共享的构造单元
- 相对地保持父母和后代之间相同的计算复杂度,通过限制后代二值串中的1的数量实现,要求1的数量介于父母的数量之间
变异 Mutation
-
目的:增强种群的多样性(能够包含更多的网络结构);增强跳出局部最优值的能力
-
方法:使用 位反转的变异算子,这在二值编码的遗传算法中经常使用。由于编码的特点,一位的反转就有能力得到一个完全不同的表现型结构,因此 限制一次变异操作中能够反转的位数目最多为一。这样一来,一次最多有一个 phase 结构发生变异
应用 Exploitation
-
目标:应用和强化一些模式,这些模式是在前一个步骤中发现的,在历史中成功的结构中普遍存在的。
-
思路来源:受 贝叶斯优化算法(BOA) 的启发。贝叶斯优化算法是被设计用于有内在关联的变量之间进行优化的算法。
-
方法:在NAS的背景下,关联关系体现在 block 和穿越不同 phase 的 path。这步使用过去评价过的所有网络的信息来指导搜索的最后一步。
-
示例:我们有一个三阶段的网络, x o ( 1 ) , x o ( 2 ) , \mathbf{x_{o}^{(1)},x_{o}^{(2)},} xo(1),xo(2), and x o ( 3 ) \mathbf{x_{o}^{(3)}} xo(3),希望知道三个阶段的关系。为了达到这个目的,构建了贝叶斯网络(BN)将三个变量关联起来,针对, x o ( 1 ) \mathbf{x_{o}^{(1)}} xo(1) 出现在第一位, x o ( 2 ) \mathbf{x_{o}^{(2)}} xo(2) 出现在 x o ( 1 ) \mathbf{x_{o}^{(1)}} xo(1) 之后,以及 x o ( 3 ) \mathbf{x_{o}^{(3)}} xo(3)出现在 x o ( 2 ) \mathbf{x_{o}^{(2)}} xo(2) 之后的可能性分别建模,即使用种群的历史对 p ( x o ( 1 ) ) , p ( x o ( 2 ) ∣ x o ( 1 ) ) , p ( x o ( 3 ) ∣ x o ( 2 ) ) p\big(\mathbf{x_{o}^{(1)}}\big),p\big(\mathbf{x_{o}^{(2)}}|\mathbf{x_{o}^{(1)}}\big),p\big(\mathbf{x_{o}^{(3)}}|\mathbf{x_{o}^{(2)}}\big) p(xo(1)),p(xo(2)∣xo(1)),p(xo(3)∣xo(2)) 进行估计,在应用过程中进行更新。新的后代从这个 BN 中抽样得到。

问题:上图就是对这个例子的说明,贝叶斯网络是一种概率关系的表示方法,我理解为一种求特定概率的分析工具。既然这样的一个概率分布是描述三个阶段关系的,那么是怎样和后代选取相互联系起来的?
实验 Experiments
性能评价 Performance Metrics
使用两个目标来指导网络搜索:分类错误率 和 计算复杂性。
对于计算复杂性,作者比较了“活跃节点的数量,节点之间活跃链接的数量,参数量,前向传播时间和浮点运算的数量”,发现浮点运算数量(FLOPs)是最能够代表计算复杂性的。
为了衡量多目标下的综合效果,作者使用了 hypervolume (HV) performance metric,即相较于一系列体现最低标准的方案,在帕累托平面的面积。最大化 HV 就能使得方案达到帕累托边界。
问题:多目标的评价方式具体是如何衡量和计算的?
实现细节 Implement Details
Dataset
使用 CIFAR-10 数据集,将原始的训练集分成训练和验证(80%-20%),测试集只用于搜索结论获取模型的测试准确性。
NSGA-Net hyper-parameters
-
n p = 3 , n o = 6 n_{p}=3, n_{o}=6 np=3,no=6,分辨率降低和此前的实验设置保持一致——stride 2 的最大值池化被放置在第一和第二个 phase 后面,最后一个 phase 接平均池化
-
初始种群通过均匀随机抽样得到,交叉概率为0.9,变异概率为0.02,种群大小为40,探索阶段共生成20次,应用阶段的生成10次,因此总共有1200个网络被搜索到。
从这个计算方法来看,种群数量中不包括 parents,即每次生成 40 个新的网络。
问题:这里的 40 应该不是种群数量,应该是生产量,种群数量应该结合死亡量进行计算(前文提到 reproduction 和 survival)。
Network training during searching
搜索阶段,限制每个节点的 channel 为 16,通过标准的 SGD 优化方法和 余弦退火学习率规划(SGDR) 来训练生成的结构。初始的学习率是 0.025,作者训练了 25 个 epoch。在 1080Ti 上用时约 9min
结构验证 Architecture Validation
作者将选出来的模型训练了 600 epoch,使用 bs = 96。同时,使用了 cutout 和 scheduled path dropout。除此之外,为了进一步改进训练过程,在 2/3 深度处,即第二次分辨率降低的位置上,增加了一个辅助的头分类器(head classifier)。这个分类器的 loss 使用了 0.4 的权重因子,其他超参数设置不变。
作者引入了 NASNet-A cell,AmoebaNet-A cell 和 DARTS cell 作为对比。
结果分析 Results Analysis
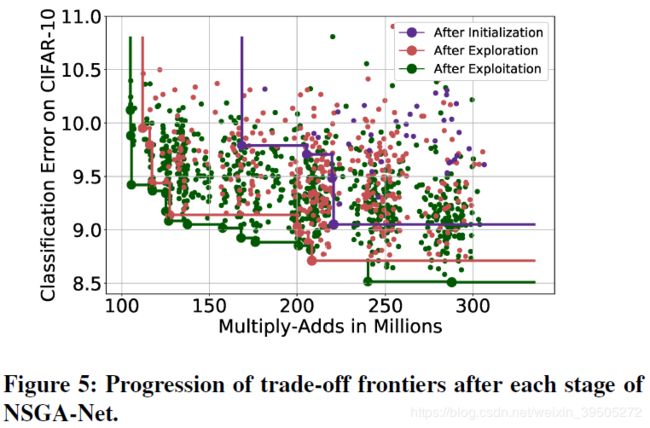
上图展示的是多目标优化的结果,其中不同的颜色表示不同的优化阶段结果,可以看到随着优化阶段的进行,整个种群的表现都是有所提升的。

上图展示了随着生成的进行,两个参数的变化情况,HV 的上升情况表明网络搜索到了大量的 trade-off 架构,而survival 下降表明很难找到比 parents 更好的后代。
作者说可以使用阈值限制后代存活率,用这个终止当前流程和在探索-应用之间切换的准则。
对比实验中,作者选择了错误率最低的和其他网络进行比较,这个网络的结构在 Figure2 中,增加了每个节点的 channel 数量,并且在整个 CIFAR-10 的训练集上进行训练。对比结果见下表,这里作者之和其他多目标的方法进行了对比。作者未能提供 HV 对比的结果。

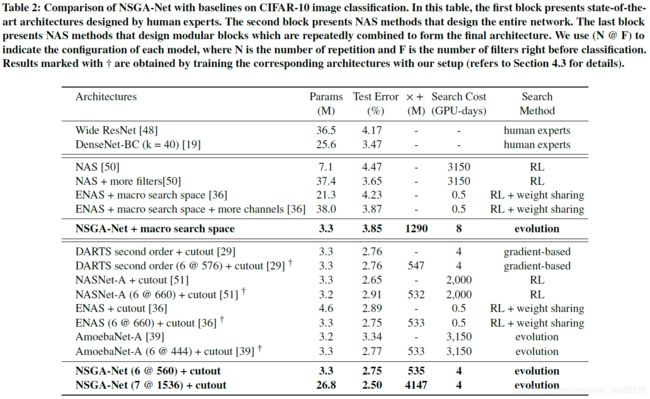
上表展示了更多错误率对比结果,可以看到针对 RL 和 evolution 的方法,本文的方案都有明显的提升。但并没有超过基于梯度的方法,仅仅在错误率上有较小的提升。
问题:作者在开头提到了单一 block 重复构建的方式具有很多弊端,可是这里对于 test error,为什么 repeat 的方式比作者设计的方式效果更好?、
难道说作者设计的方式只在多目标是 work 的,只是更有利于控制计算复杂性?
macro search space 上搜索到的网络结构见 Figure2,NASNet micro search space 搜索到的网络结构为

可迁移性 Transferability
作者通过将搜索到的模型用于 CIFAR-100 数据集来验证结构的可迁移性,结果如下
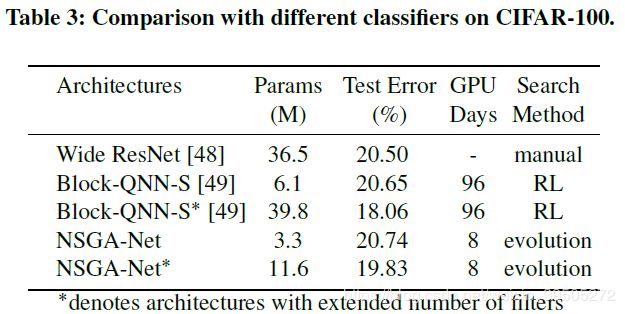
这里作者对比的点主要在于参数的减少,准确率并没有明显提升。
切割分析 Ablation Studies
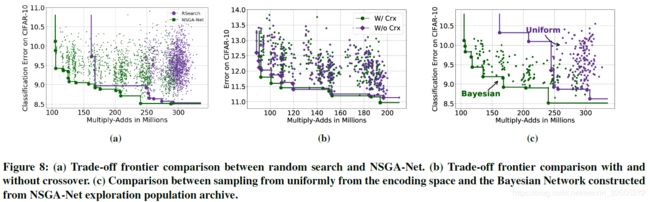
作者首先对比了均匀随机搜索结果,证明了搜索方案的有效性。图b 展示了有无 Crossover Operator 操作的效果。图c 展示了 Bayesian Network (BN) based Offspring Creation 的效果,对比试验在应用阶段采用均匀随机选取。
可以看出来 Crossover 的效果实际上并不大,而对比a c两图,先使用遗传算法在随机选取的结果似乎还不如直接随机选择,但第一阶段的遗传算法应该是有效的(其实作者也并未做这样的对比,但至少有先例是这样做的)。这可能是因为图c样本点较少,训练不完全的原因,或者是后期的随机生成破坏了遗传算法的有效性。
讨论
- 通过减少高分辨率背景下的运算来降低运算复杂度(如 Figure2,靠近输入的 phase 中的 node 少)
- 单一 block 重复多次的构建方式中,复杂度的控制只能通过 block 的重复次数来控制
结论 Conclusion
NSGA-Net 具有以下优势
- 可以有效地控制复杂度并进行权衡
- 基于种群的算法比目标之间线性加权组合的优化方式更加有效
- 更有效地探索阶段和应用阶段的设计,使用 crossover 框架并通过 BOA 利用了整个搜索历史
- 能够一次性输出一个网络集合,能够适应多种目标场景
整体来看:
- 作者在使用遗传算法的基础上,引入了 交叉 机制,但我认为从结果上来说不能作为一个强有力的优化点
- 作者立足于多目标的 NAS ,希望能够尽力权衡 复杂性 和 准确度,这在之前的工作来说是有的,作者在这方面的对比不够完全(一份强调 trade-off 的工作就应该证明自己在限制下结果更优,而对比中更多的关注点在准确率而非 trade-off 本身)
- 对于多目标如何综合影响网络搜索过程讲述的不是很详细
- 贝叶斯推理部分的引入应该是比较关键的一点,作者描述这个可以考虑到全局的搜索历史
- 还有一个关键点在于作者打破了重复 block 的限制,同时增加了整个 block 跳过链接结构的考虑。(这一点关键在于node之间共享参数的解决)问题是在对比中作者又使用了重复 block 的方式而且结果更优(?)。但无论如何,采用 block 应该只是降低训练复杂性的一种折中方式,创造更大的搜索空间应该是能够带来更好地结果的。