BeautifulSoup爬取豆瓣电影top250信息
豆瓣是一个社区网站,创立于2005年3月6日。该网站以书影音起家,提供关于书籍,电影,音乐等作品信息,其描述和评论都是由用户提供的,是Web2.0网站中具有特色的一个网站。
网址:https://movie.douban.com/top250?start=0&filter=
我将基于豆瓣电影top250讲解BeautifulSoup技术的爬虫,获取排名前250名的影片信息,包括(网站名称、豆瓣排名、中文名称、原名称、国家、上映时间、类型、评分、导演主演、评价人数、剧情简介链接、图片地址、影片标签)等。主要内容包括:分析网页DOM树结构,爬取豆瓣电影信息、分析链接跳转及爬取对应的信息。
1、分析网页结构及定位
1.1. 我们先导入相关的的包,获取网页并使用BeautifulSoup解析,代码如下:
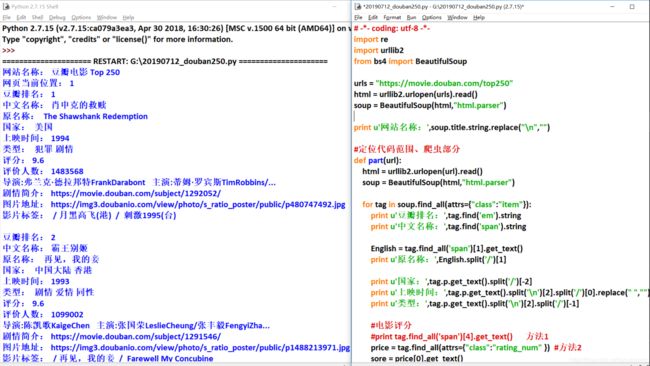
# -*- coding: utf-8 -*-
import urllib2
from bs4 import BeautifulSoup
url = "https://movie.douban.com/top250"
html = urllib2.urlopen(url).read()
soup = BeautifulSoup(html,"html.parser")
print u'网站名称:',soup.title.string.replace("\n","")
1.2.把鼠标指在肖申克的救赎模块,右击选择检查,进行详细信息定位
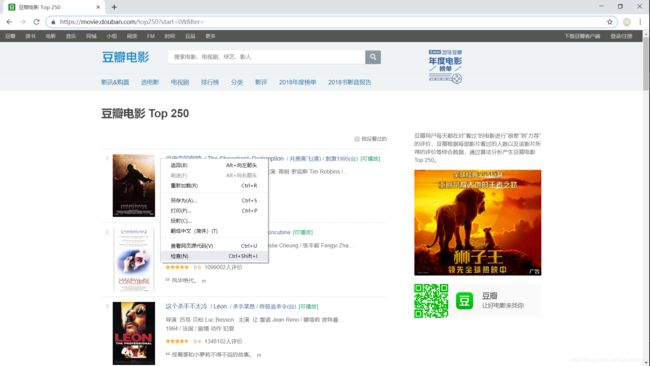
把网页看作一个大盒子,这些信息都是一个一个的小盒子装着的,每一个电影的所有信息都装在

只需要在class="item"中做迭代循环就可以获取到模块的所有信息,定位代码如下:
for tag in soup.find_all(attrs={"class":"item"}):
2、获取对应的信息
(1)豆瓣电影排名
电影排名被存在 标签中,而且是在第一个em标签,方便直接获取

获取第一个em标签内容代码如下:
>>> print u'豆瓣排名:',tag.find('em').string
豆瓣排名: 1
>>> print u'豆瓣排名:',tag.find('em').get_text()
豆瓣排名: 1
>>>
(2)获取电影中文名称
电影的中文名称和英文名称都在span标签中,但中文名称在第一个span标签

获取第一个span标签内容代码如下:
>>> print u'中文名称:',tag.find('span').string
中文名称: 肖申克的救赎
>>> print u'中文名称:',tag.find('span').get_text()
中文名称: 肖申克的救赎
>>>
(2)获取电影原名称
- 通过第二个span标签找到它
- 通过split(’/’)[1]去掉“/”
>>> English = tag.find_all('span')[1].get_text()
>>> print u'原名称:',English
原名称: / Intouchables
>>>
>>> print u'原名称:',English.split('/')[1]
原名称: Intouchables
>>>
(3)获取国家
- 通过p标签查找所有内容
- 通过split(’/’)分割,“-”表示向后进行分割
>>> print u'国家:',tag.p.get_text()
国家:
导演: 奥利维·那卡什 Olivier Nakache / 艾力克·托兰达 Eric Toledano 主...
2011 / 法国 / 剧情 喜剧
>>> print u'国家:',tag.p.get_text().split('/')[-2]
国家: 法国
>>>
(4)上映时间
- 定点p标签内容
- 用split(’\n’)进行换行符定位截取
- 通过split(’/’)截取出时间
- 使用replace(" “,”")替换掉多余的空格
>>> print u'p标签内容:',tag.p.get_text()
p标签内容:
导演: 奥利维·那卡什 Olivier Nakache / 艾力克·托兰达 Eric Toledano 主...
2011 / 法国 / 剧情 喜剧
>>> print u'换行符定位:',tag.p.get_text().split('\n')[2]
换行符定位: 2011 / 法国 / 剧情 喜剧
>>> print u'截取出时间:',tag.p.get_text().split('\n')[2].split('/')[0]
截取出时间: 2011
>>> print u'时间去掉空格:',tag.p.get_text().split('\n')[2].split('/')[0].replace(" ","")
时间去掉空格: 2011
>>>
(5)获取类型
在p标签中通过换行符(’\n’)和“/”进行截取,方法同上,代码片段如下:
>>> print u'类型:',tag.p.get_text().split('\n')[2].split('/')[-1]
类型: 剧情 喜剧
>>>
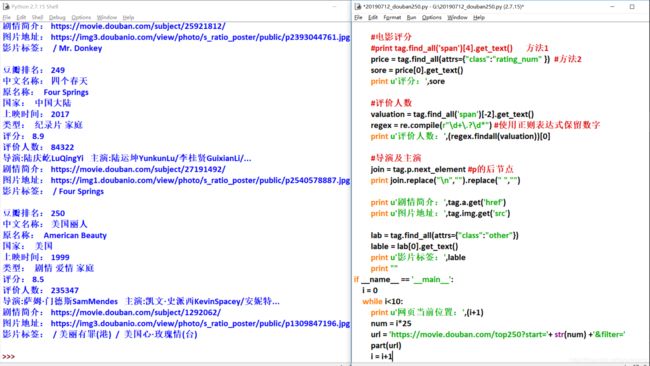
(6)获取电影评分
方法一: 直接获取第五个span标签的内容,代码片段如下:
>>> print u'评分:',tag.find_all('span')[4].get_text()
评分: 9.2
>>>
方法二: 节点定位法,建议多使用它
>>> price = tag.find_all(attrs={"class":"rating_num" })
>>> sore = price[0].get_text()
>>> print u'评分:',sore
评分: 9.2
>>>
(7)获取评论人数
- 通过span标签倒序截取出内容
- 使用正则表达式re.compile(r"\d+.?\d*")保留数字
>>> valuation = tag.find_all('span')[-2].get_text()
>>> print valuation
557877人评价
>>> regex = re.compile(r"\d+\.?\d*")#使用正则表达式保留数字
>>> print (regex.findall(valuation))
[u'557877']
>>> print u'评价人数:',(regex.findall(valuation))[0]
评价人数: 557877
>>>
(8)获取导演及主演
- 获取p标签的后节点的内容
- 替换掉换行符和空格符
>>> print tag.p.next_element #p的后节点内容
导演: 奥利维·那卡什 Olivier Nakache / 艾力克·托兰达 Eric Toledano 主...
>>> print tag.p.next_element.replace("\n","").replace(" ","")
导演:奥利维·那卡什OlivierNakache/艾力克·托兰达EricToledano 主...
>>>
(9)获取剧情简介链接
通过a标签的 href 直接找到
>>> print u'剧情简介:',tag.a.get('href')
剧情简介: https://movie.douban.com/subject/6786002/
>>>
(10)图片地址链接
通过 img 标签的 src 直接找到
>>> print u'图片地址:',tag.img.get('src')
图片地址: https://img3.doubanio.com/view/photo/s_ratio_poster/public/p1454261925.jpg
>>>
(11)获取电影标签
- 获取HTML节点定位
/ / 闪亮人生(港) / 逆转人生(台) - 提取文本
>>> lab = tag.find_all(attrs={"class":"other"})
>>> print lab[0]
<span class="other"> / 闪亮人生(港) / 逆转人生(台)</span>
>>> lable = lab[0].get_text()
>>> print u'影片标签:',lable
影片标签: / 闪亮人生(港) / 逆转人生(台)
>>>
3、实现链接跳转分析爬取
传参函数结构
def part(url):
if __name__ == '__main__':
url = "http://www.ayouleyang.cn/"
part(url)
实现新链接生成及传参代码如下:
# -*- coding: utf-8 -*-
import re
import urllib2
from bs4 import BeautifulSoup
#定位代码范围、爬虫部分
def part(url):
#print需要输出的内容
#主函数,生成链接传参
if __name__ == '__main__':
i = 0
while i<10:
print u'网页当前位置:',(i+1)
num = i*25
url = 'https://movie.douban.com/top250?start='+ str(num) +'&filter='
part(url)
i = i+1
4、完整的爬取代码和运行结果如下
# -*- coding: utf-8 -*-
import re
import urllib2
from bs4 import BeautifulSoup
urls = "https://movie.douban.com/top250"
html = urllib2.urlopen(urls).read()
soup = BeautifulSoup(html,"html.parser")
print u'网站名称:',soup.title.string.replace("\n","")
#定位代码范围、爬虫部分
def part(url):
html = urllib2.urlopen(url).read()
soup = BeautifulSoup(html,"html.parser")
for tag in soup.find_all(attrs={"class":"item"}):
print u'豆瓣排名:',tag.find('em').string
print u'中文名称:',tag.find('span').string
English = tag.find_all('span')[1].get_text()
print u'原名称:',English.split('/')[1]
print u'国家:',tag.p.get_text().split('/')[-2]
print u'上映时间:',tag.p.get_text().split('\n')[2].split('/')[0].replace(" ","")
print u'类型:',tag.p.get_text().split('\n')[2].split('/')[-1]
#电影评分
#print tag.find_all('span')[4].get_text() 方法1
price = tag.find_all(attrs={"class":"rating_num" }) #方法2
sore = price[0].get_text()
print u'评分:',sore
#评价人数
valuation = tag.find_all('span')[-2].get_text()
regex = re.compile(r"\d+\.?\d*") #使用正则表达式保留数字
print u'评价人数:',(regex.findall(valuation))[0]
#导演及主演
join = tag.p.next_element #p的后节点
print join.replace("\n","").replace(" ","")
print u'剧情简介:',tag.a.get('href')
print u'图片地址:',tag.img.get('src')
lab = tag.find_all(attrs={"class":"other"})
lable = lab[0].get_text()
print u'影片标签:',lable
print ""
if __name__ == '__main__':
i = 0
while i<10:
print u'网页当前位置:',(i+1)
num = i*25
url = 'https://movie.douban.com/top250?start='+ str(num) +'&filter='
part(url)
i = i+1