机器学习笔记(三十二):集成学习、随机森林

凌云时刻 · 技术


导读:前面几个章节介绍了集成学习的原理。在集成学习中,如果使用决策树,通过取样的方式创建子模型,这些子模型就是一个个随机的决策树。我们管这种方式形象的称为随机森林。在Scikit Learn中,也为我们封装好了随机森林的类,它的原理和上一小节示例中通过BaggingClassifier和DecisionTreeClassifier构建的分类器基本是一样的。我们来看看如何使用。
作者 | 计缘
来源 | 凌云时刻(微信号:linuxpk)
Bagging

 子模型取样方式
子模型取样方式
子模型的取样方式有两种:
放回取样:每次取完训练子模型的部分样本数据后,再放回样本数据池里,训练下一个子模型使用同样的方式。这样的方式,训练不同的子模型会可能会用到小部分相同的样本数据。
不放回取样:每次取完训练子模型的部分样本数据后,这部分样本数据不再放回样本数据池里,训练下一个子模型使用同样的方式。这样的方式,训练不同的子模型的样本数据不会重复。
通常使用放回取样的方式更多,举个例子,假如有500个样本数据,训练子模型时使用50条数据,那么使用不放回取样只能训练出10个子模型。而如果使用放回取样的话,理论上可以训练出成千上万个子模型。在机器学习中,将取样称为Bagging。而在统计学中,放回取样称为Bootstrap。
下面我们用代码来看看如何使用取样的方式训练子模型:
|
OOB
使用放回取样方式虽然可以构建更多的子模型,但是它有一个问题,那就是在有限次的放回取样过程中,有一部分样本数据可能根本没有取到,按严格的数学计算,这个比例大概是37%。这个情况称为OOB(Out of Bag)换个思路思考,这37%根本没有被用到的样本数据恰好可以作为测试数据来用,所以在使用这种方式时,我们可以不用train_test_split对样本数据进行拆分,直接使用没有被用到的这37%的样本数据既可。来看看BaggingClassifier如何使用OOB:
|
可以看到准确率是有所提高的。
并发取样
按照Bagging的思路,因为不需要保证每次取样的唯一性,所以每次取样是可以并行处理的。我们可以使用n_jobs指定运行的CPU核数:
|
可以看到,训练时间缩短了150多毫秒。
在 机器学习笔记(四)—(六)kNN算法、超参数、数据归一化 中的网格搜索超参数一节介绍过n_jobs参数。
特征取样
我们之前讲的都是对样本数据条数进行随机取样,BaggingClassifier还可以对特征进行随机取样,这样更能增加子模型的差异性,称为Random Subspaces。另外还有既对样本条数取样,又针对特征随机取样的方式,称为Random Patches。
|
首先将max_samples设置为500,意在取消对样本数据条数随机取样,因为一共有500个样本数据,要创建500个子模型,如果每个子模型都使用500个样本数据,那相当于对样本条数取样是没有意义的。又因为我们的样本特征只有2个,所以max_features设置为1。
如果将max_samples设回100的话,那就是既对样本条数随机取样,又对特征随机取样:
|
随机森林
前面几个章节介绍了集成学习的原理。在集成学习中,如果使用决策树,通过取样的方式创建子模型,这些子模型就是一个个随机的决策树。我们管这种方式形象的称为随机森林。在Scikit Learn中,也为我们封装好了随机森林的类,它的原理和上一小节示例中通过BaggingClassifier和DecisionTreeClassifier构建的分类器基本是一样的。我们来看看如何使用:
|
fit之后,从返回结果里可以看到,RandomForestClassifier的参数综合了BaggingClassifier及DecisionTreeClassifier的参数。我们可以对不同的参数进行调优,训练出更好的模型。
Bagging
Boosting
我们之前介绍的集成学习中子模型之间是相互独立的,差异越大越好。那么集成学习中还有一种创建子模型的方式,就是每个子模型之间有关联,都在尝试增强整体的效果。这种方式称为Boosting方式。
Ada Boosting
在Boosting方式中,有一种方式称为Ada Boosting,我们用网络上的一幅解决回归问题的图来做以解释:
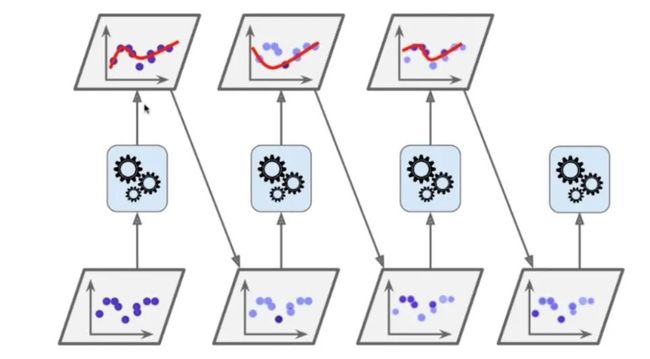
我们先来看第一个齿轮上下连接的图,下面的图是原始样本数据,每个样本点的权重值都是一样的,上面的图是第一个子模型预测出的结果,那势必会有没有被准确预测的样本点,将这些样本点的权重值加大。
第二列下图中展示的深色点就是权重值增大的样本点,浅色点是上一个子模型预测出的样本点。那么训练第二个子模型时会优先考虑权重大的样本点进行拟合,拟合出的结果如第二列上图所示。
然后再将第二个子模型没有预测出的样本点的权重值增大,如第三列下图所示,在训练第三个子模型时优先考虑第二个子模型没有预测出的样本点进行拟合。以此类推,这样就可以训练出很多子模型,不同于取样方式,Boosting方式的所有子模型使用全量的样本数据进行训练,不过样本数据有权重值的概念,而且后一个子模型是在完善上一个子模型的错误,从而所有子模型达到增强整体的作用。这就是Ada Boosting的原理。
下面来看看Scikit Learn为我们提供的AdaBoostClassifier如何使用:
|
Gradient Boosting
还有一种Boosting的方式称为Gradient Boosting。它的原理是我们训练第一个子模型M1,它肯定会有没有准确预测到的样本,我们称为错误E1。然后我们将E1这些样本点作为训练第二个子模型的样本数据,训练出第二个子模型M2,然后它必然还会产生错误E2。那么再将E2作为训练第三个子模型的样本数据,产生错误E3,以此类推,训练出多个子模型。最终预测的结果是M1+M2+M3+…的结果。
下面来看看Scikit Learn为我们提供的GradientBoostingClassifier如何使用:
|
Stacking
这一小节我们再来认识一个集成学习创建子模型的思路,Stacking。

上图也是网络上的一幅图,我们先看中间那层,Subset1和Subset2是将原始样本数据分成两部分后的数据,我们先使用Subset1训练出三个子模型,这三个子模型会产生错误,既没有预测到的样本数据。然后将这三个子模型的三个错误结果和Subset2组成新的样本数据,训练出第四个子模型。整体的预测结果以第四个子模型的结果为准。这就是Stacking的基本原理,通过Stacking方式可以构建出比较复杂的子模型关系网:
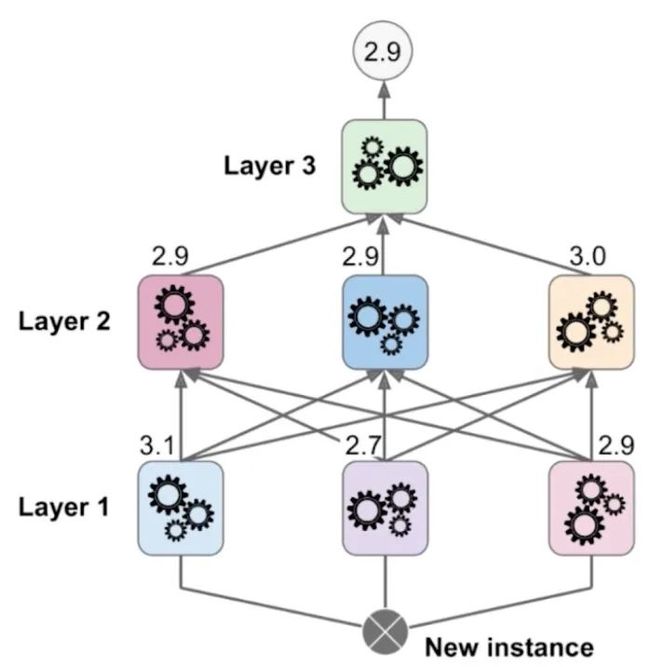
上图有三层,一共7个子模型,就需要将原始样本数据分成三份,第一份作为训练第一层三个子模型的样本数据,第二份作为训练第二层子模型的样本数据其中一部分,以此类推。
不过在Scikit Learn中没有提供任何Stacking的类供我们使用,Stacking的原理已经有神经网络的雏形了,里面涉及到的调参环节非常多,大家有兴趣可以自己尝试实现Stacking算法。
END

往期精彩文章回顾

机器学习笔记(三十一):集成学习
机器学习笔记(三十):基尼系数、CART
机器学习笔记(二十九):决策树、信息熵
机器学习笔记(二十八):高斯核函数
机器学习笔记(二十七):核函数(Kernel Function)
机器学习笔记(二十六):支撑向量机(SVM)(2)
机器学习笔记(二十五):支撑向量机(SVM)
机器学习笔记(二十四):召回率、混淆矩阵
机器学习笔记(二十三):算法精准率、召回率
机器学习笔记(二十二):逻辑回归中使用模型正则化

长按扫描二维码关注凌云时刻
每日收获前沿技术与科技洞见