Java 8 已经发布一段时间了,许多开发者已经开始使用 Java 8。本文也将讨论最新发布在 JDK 中的并发功能更新。事实上,JDK 中已经有多处java.util.concurrent 改动,但本文重点将是 Fork-Join 框架的改进。我们将讨论一点 Fork-Join,然后实现一个简单的基准测试以比较 FJ 在 Java 7 和Java 8 中的性能。

你可能对Fork/Join在意的地方
ForkJoin 是一个通常用于并行计算递归任务的框架。它最早被引入Java 7 中,从那时起它就能很好地完成目标任务。原因在于,许多大型任务本质上都可以递归表示。
以最有名的 MapReduce 编程为例:对一篇文章中不同词的出现次数进行统计。很显然,可以将文档分为很多部分,逐项地记录字数,最后再合并成结果。诚然,ForkJoin其实是 MapReduce 基本法则的一种实现,区别在于,所有的 worker 都是同一个虚拟机中的线程,而不是一组机器。
ForkJoin 框架的核心部分是 ForkJoinPool ,它是一个 ExecutorService, 能够接收异步任务,返回Future对象,因此可用于跟踪执行中的计算状态。
使 ForkJoinPool 不同于其他 ExecutorServices 的是,在当下并不执行任务的工作线程会检查其伙伴的工作状态,并向他们借取任务。这种技术称为 work-stealing 。那么,work-stealing 有什么妙用呢?
work-stealing 是一种分散式的工作量管理方法,无需将工作单元分配给所有可用的工作线程,而是每个线程自己管理其任务队列。关键在于高效地管理这些队列。
关于让每个工作进程处理自己的队列,有两个主要问题:
- 外部提交的任务去哪里了?
- 我们怎样组织 work-stealing 以有效访问队列
本质上来说,在执行大型任务时,外部提交任务和由工作线程创建的任务之间区别不大。他们都有类似的执行要求并提供结果。然而,运作方式是不同的。最主要的区别在于由工作进程创建的任务可以被窃取。这意味着即便被放进了一个工作进程的任务队列中,他们仍可能被其他工作进程执行。
ForkJoin 框架处理它的方法很简单,每个工作线程都有2个任务队列,一个用于外部任务,另一个用于实现窃取工作进程的运作。当外部提交任务时,会将任务添加至随机的工作队列中。当一个任务被分为更小的任务时,工作线程将他们添加到自己的任务队列中,并希望其他工作线程来帮忙。
窃取任务的想法基于以下事实:工作线程在它任务队列末尾添加任务。在正常的执行过程中,每个工作线程试着去从任务队列的队首拿任务,当其个人队列的任务为空时,这一操作就会失败,转而窃取别的工作线程的任务队列末尾的任务。这有效避免了多数任务队列的互锁问题,提高了性能。
另一个使 ForkJoin 池工作更快的诀窍是当一个工作线程窃取任务时,它留下了它在哪里取得任务的线索,这样原始的工作线程可以找到它并且帮助该工作线程,因此父任务的的工作进展会更快。
总而言之,这是一套极其复杂的系统,需要大量的背景知识使其顺利运行。并且,系统的属性和性能与具体实现的方式关系很大。因此笔者怀疑,若不进行重大的重构,系统会彻底改变。
Java 7 中 ForkJoin 有什么问题?
在 Java 7 中引入 ForkJoin 框架之后,它运行良好。然而它并没有停止进步。在 Java 8 的并发性更新中, ForkJoin 得到改善。从这次的 Java 增强方案中,我们可以了解改善的内容。
增加了 ForkJoinPools 的功能并提高其性能,使其应用在用户希望的日益广泛的应用中,且效率更高。新特性包括对最适于 IO-bound 使用的 completion-based 设计的支持等。
另一个消息来源当然是与改进作者的对话,例如,Doug Lea 早前曾提到的更新有:
当大量的用户提交大量任务时,吞吐量能大幅度提高。其原理是将外部提交者与工作线程相似地对待——均使用随机任务队列和窃取任务。当所有任务都为异步,且被提交至 pool 而不是 forked 时,能极大地提高吞吐量。
然而找出究竟什么被改变了、哪些场景被影响了并不简单。因此,让我们换一种方式解决。笔者会创建一个基准测试程序以模仿简单的 ForkJoin 计算,并测量 ForkJoin 处理任务与单个线程依次完成任务各自所需时间,希望这种方法能帮我们找出改善的具体内容。
Java 8 和 Java 7 性能的比较
笔者创建了一个基准测试程序以探索 Java 7 和 Java 8 之间的区别是否真的明显。如果你想查看源码,或者亲自尝试,这里是其 Github repo 。
由于Oracle工程师的努力,OpenJDK现在已经包含 Java Microbenchmark Harness (JMH)项目,该项目专用于创建基准测试程序,且不容易出现常见的微基准测试问题与错误。
JMH 还附带了 Maven 原型项目。因此,将一切设置好其实很简单。
org.openjdk.jmh
mh-core
0.4.1
在写本文时,JMH core 的最新版本是 0.4.1 ,包括了 @Param 注释,可用一系列的参数化输入运行基准测试程序。这减轻了手动重复执行相同基准测试的痛苦,并简化了获取结果的流程。
现在,每个基准测试迭代会获得自己的 ForkJoinPool 实例,这也减少了常用 ForkJoinPool 实例化在 Java 8 与其之前版本中的区别。
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@Warmup(iterations = 5, time = 3, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 20, time = 3, timeUnit = TimeUnit.SECONDS)
@Fork(1)
@State(Scope.Benchmark)
public class FJPBenchmark {
@Param({ "200", "400", "800", "1600"})
public int N;
public List tasks;
public ForkJoinPool pool = new ForkJoinPool();
@Setup
public void init() {
Random r = new Random();
r.setSeed(0x32106234567L);
tasks = new ArrayList(N * 3);
for (int i = 0; i < N; i++) {
tasks.add(new Sin(r.nextDouble()));
tasks.add(new Cos(r.nextDouble()));
tasks.add(new Tan(r.nextDouble()));
}
}
@GenerateMicroBenchmark
public double forkJoinTasks() {
for (RecursiveTask task : tasks) {
pool.submit(task);
}
double sum = 0;
Collections.reverse(tasks);
for (RecursiveTask task : tasks) {
sum += task.join();
}
return sum;
}
@GenerateMicroBenchmark
public double computeDirectly() {
double sum = 0;
for (RecursiveTask task : tasks) {
sum += ((DummyComputableThing) task).dummyCompute();
}
return sum;
}
}
Sin 、Cos 和 Tan 是 RecursiveTask 的实例,实际上 Sin 和 Cos 并不递归,但会分别计算 Math.sin(input) 和 Math.cos(input) 的值 。Tan 的任务实际上会递归为一组 Sin 和 Cos ,并返回两者的除法结果。
JMH 处理项目的代码并从标有 @GenerateMicroBenchmark 注释的方法处生成基准测试程序。你在该类上方看到的其他注释指定了基准测试的选项:迭代次数,计入最终结果的迭代次数,是否 fork 另一个 JVM 进程用于基准测试以及测量哪些值。测量值可以是代码的吞吐量,或这些方法在一段时间内的执行次数。
@Param 指定运行基准测试程序时几个输入的大小。总而言之,JMH非常简单,创建基准测试程序不需要手动处理迭代、定时或整理结果。
用 Java 7 和 8 运行该基准测试得到以下结果。笔者分别使用的是1.7.0_40 and 1.8.0.版本。
shelajev@shrimp ~/repo/blogposts/fork-join-blocking-perf » java -version
java version "1.7.0_40"
Java(TM) SE Runtime Environment (build 1.7.0_40-b43)
Java HotSpot(TM) 64-Bit Server VM (build 24.0-b56, mixed mode)
Benchmark (N) Mode Samples Mean Mean error Units
o.s.FJPB.computeDirectly 200 thrpt 20 27.890 0.306 ops/ms
o.s.FJPB.computeDirectly 400 thrpt 20 14.046 0.072 ops/ms
o.s.FJPB.computeDirectly 800 thrpt 20 6.982 0.043 ops/ms
o.s.FJPB.computeDirectly 1600 thrpt 20 3.481 0.122 ops/ms
o.s.FJPB.forkJoinTasks 200 thrpt 20 11.530 0.121 ops/ms
o.s.FJPB.forkJoinTasks 400 thrpt 20 5.936 0.126 ops/ms
o.s.FJPB.forkJoinTasks 800 thrpt 20 2.931 0.027 ops/ms
o.s.FJPB.forkJoinTasks 1600 thrpt 20 1.466 0.012 ops/ms
shelajev@shrimp ~/repo/blogposts/fork-join-blocking-perf » java -version
java version "1.8.0"
Java(TM) SE Runtime Environment (build 1.8.0-b132)
Java HotSpot(TM) 64-Bit Server VM (build 25.0-b70, mixed mode)
Benchmark (N) Mode Samples Mean Mean error Units
o.s.FJPB.computeDirectly 200 thrpt 20 27.680 2.050 ops/ms
o.s.FJPB.computeDirectly 400 thrpt 20 13.690 0.994 ops/ms
o.s.FJPB.computeDirectly 800 thrpt 20 6.783 0.548 ops/ms
o.s.FJPB.computeDirectly 1600 thrpt 20 3.364 0.304 ops/ms
o.s.FJPB.forkJoinTasks 200 thrpt 20 15.868 0.291 ops/ms
o.s.FJPB.forkJoinTasks 400 thrpt 20 8.060 0.222 ops/ms
o.s.FJPB.forkJoinTasks 800 thrpt 20 4.006 0.024 ops/ms
o.s.FJPB.forkJoinTasks 1600 thrpt 20 1.968 0.043 ops/ms
为了便于查看结果,下面以图表形式进行展示。
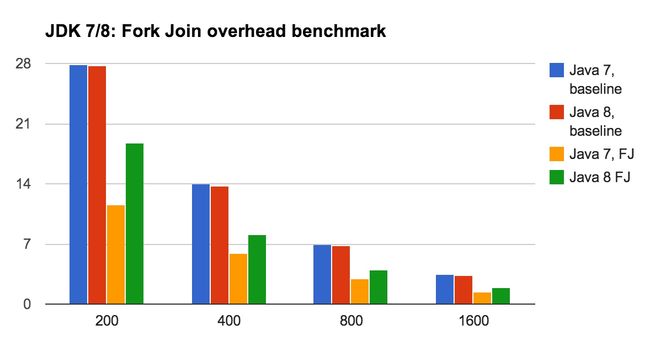
我们可以看到 JDK 7 与 8 间的基线结果(直接用同一线程运行程序的吞吐量)差异并不大。然而,若加入管理递归任务的时间,使用 ForkJoin 来执行,则 Java 8 的速度更快。这个简单的基准测试表明,在最新版的 Java 中,管理 ForkJoin 任务的效率有了 35% 左右的性能提高。
基线和 FJ 计算之间的结果差异是因为我们刻意创建的递归任务非常单薄。该任务实质上只是调用一个优化后的数学类。因此,直接进行数学运算会快得多。一个更强壮的任务必将改变这一情况,但是它们会减轻 ForkJoin 管理的开销,而这是我们起初就想测量的目标。不过,一般而言,执行递归任务比多次执行同个方法调用要高效得多。
同时,Java 7 和 Java 8 的基线测试结果也有略微的不同。这个差异是可以忽视的,但很可能不是因为 Java 7 和 8 中数学类的实现差异造成的。而是一个测量假象,JMH 努力抵消却还是无法避免。

免责声明:当然,这些结果是模拟所得的,你应该持保留态度。然而,除了讨论 Java 性能,笔者也想展示 JMH 创建基准测试程序是如何简单,且能避免一些常见基准测试问题,比如没有提前预热 JVM 。如果基准测试本身存在缺陷,热身也无济于事,但是肯定还是有所裨益。因此,如果你看到以上代码中的逻辑缺陷,请一定告诉笔者。
总结:
首先,ForkJoinPool, ForkJoinPool.WorkQueue 和ForkJoinTask 类的源码并不容易阅读,它包含许非安全原理,因此你可能没法在15分钟完全理解ForkJoin 框架。

然而,这些类的文档丰富,并且包含许多内部注释。它也可能学习挖掘JDK最有趣的地方。
另一个相关的发现是 ForkJoinPool 在 Java8 中的性能更好,至少在一些用例中是这样的。虽然笔者不能精确地描述这背后的原因,但如果我在代码中用到 ForkJoin ,我一定会升级 Java 版本。
原文地址:http://zeroturnaround.com/rebellabs/is-java-8-the-fastest-jvm-ever-performance-benchmarking-of-fork-join/ 本文作者:Oleg Shelajev 系 OneAPM 工程师编译整理。
OneAPM 为您提供端到端的 Java 应用性能解决方案,我们支持所有常见的 Java 框架及应用服务器,助您快速发现系统瓶颈,定位异常根本原因。分钟级部署,即刻体验,Java 监控从来没有如此简单。想阅读更多技术文章,请访问 OneAPM 官方技术博客。
本文转自 OneAPM 官方博客