- RocketMQ的架构及其工作流程详解
--流星。
微服务rocketmqjava
RocketMQ的架构及解析Producer1、消息发布的角色,支持分布式集群方式部署。2、Producer通过MQ的负载均衡模块选择相应的Broker集群队列进行消息投递,投递的过程支持快速失败并且低延迟。Consumer1、消息消费的角色,支持分布式集群方式部署。2、支持以push推,pull拉两种模式对消息进行消费。3、同时也支持集群方式和广播方式的消费,它提供实时消息订阅机制,可以满足大多
- RocketMQ 集群消费与广播消费
俏布斯
消息中间件RocketMQjava-rocketmqrocketmq
RocketMQ集群消费与广播消费消费组间广播消费:每个消费者分组只初始化唯一一个消费者,每个消费者可消费到消费者分组内所有的消息,各消费者分组都订阅相同的消息,以此实现单客户端级别的广播一对多推送效果。该方式一般可用于网关推送、配置推送等场景。消费组内共享消费(集群消费):,每个消费者分组下初始化了多个消费者,这些消费者共同分担消费者分组内的所有消息,实现消费者分组内流量的水平拆分和均衡负载。该
- 【RocketMQ 存储】ConsumeQueue 刷盘服务 FlushConsumeQueueService
月幻星影
RocketMQ源码分析rocketmqjavaConsumeQueue刷盘
文章目录1.前言2.为什么ConsumeQueue没有提交服务3.FlushConsumeQueueService刷盘服务3.1参数3.2run方法3.3doFlush方法刷盘3.4ConsumeQueue#flush刷盘3.5MappedFileQueue#flush4.小结本文章基于RocketMQ4.9.31.前言RocketMQ存储部分系列文章:【RocketMQ存储】-RocketMQ存
- Rabbit MQ 高频面试题【刷题系列】
Microi风闲
【面试宝典】ASP.NETCorerabbitmq面试
文章目录一、公司生产环境用的什么消息中间件?二、Kafka、ActiveMQ、RabbitMQ、RocketMQ有什么优缺点?三、解耦、异步、削峰是什么?四、消息队列有什么缺点?五、RabbitMQ一般用在什么场景?六、简单说RabbitMQ有哪些角色?七、RabbitMQ有几种工作模式?八、如何保证RabbitMQ消息的顺序性?九、消息怎么路由?十、如何保证消息不被重复消费?十一、如何确保消息接
- RocketMQ消费者重平衡机制
俏布斯
消息中间件RocketMQrocketmq
RocketMQ的消费者重平衡机制确保在消费者组内成员变化时,消息队列(MessageQueue)被合理分配。以下是详细的解析:重平衡机制概述触发条件:消费者启动或关闭。定时触发(默认20秒一次)。Topic的队列数量变化。消费者组内成员变化(通过心跳检测)。目标:在集群模式下,每个队列仅被一个消费者消费,确保负载均衡。流程:获取Topic的队列列表和当前消费者组成员。根据分配策略重新分配队列。释
- RabbitMQ复习
SJLoveIT
rabbitmq分布式
消息中间件的作用:(1)异步处理(2)应用解耦(3)流量削峰消息中间件的缺点:引入了新的东西,也就增加了新的故障点。比如消息中间件挂了,影响系统的可用性。两种框架:JMS和AMQP最大的区别是JMS是是javaapi,对跨平台的支持较差,但在纯java技术栈内首选。AMQP是跨平台的,序列化方式选json,不管你是java,php,C/C++,python,都能处理RabbitMQ实现的事AMQP
- 常见的消息中间件以及应用场景
纠结哥_Shrek
rabbitmqrocketmq
消息中间件(MessageOrientedMiddleware,简称MOM)是支持消息传递的中间件,主要用于在分布式系统中实现不同应用之间的消息通信。常见的消息中间件有以下几种,每种都有不同的应用场景:1.RabbitMQ类型:基于AMQP协议的消息中间件。应用场景:任务调度:适用于需要任务分发和异步处理的场景,比如后台处理任务、日志处理等。微服务通信:用于解耦微服务之间的通信,保证服务间的高可用
- JAVA中ES根据条件查询计数操作
爪哇天下
javaelasticsearchjvm
NativeSearchQueryBuilderqueryBuilder=newNativeSearchQueryBuilder();//获取查询条件BoolQueryBuilderboolQueryBuilder=QueryBuilders.boolQuery();boolQueryBuilder.must(QueryBuilders.termQuery("key1",value1));bool
- RabbitMQ 集群部署详解
LlinCK
RabbitMQ队列rabbitmq消息队列运维大数据
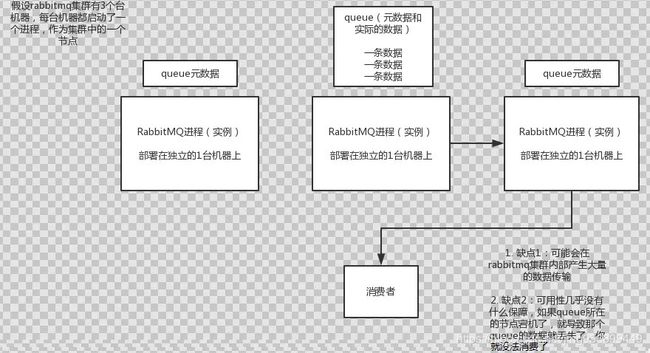
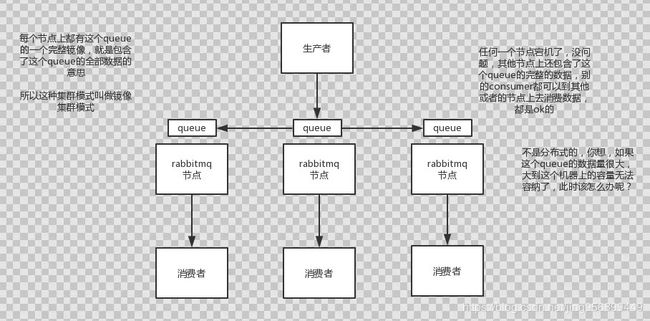
一、RabbitMQ两种集群部署方式1.1普通集群模式queue创建之后,如果没有其它policy,消息实体只存在于其中一个节点,A、B两个Rabbitmq节点仅有相同的元数据,即队列结构,但队列的数据仅保存有一份,即创建该队列的rabbitmq节点(A节点),当消息进入A节点的Queue中后,consumer从B节点拉取时,RabbitMQ会临时在A、B间进行消息传输,把A中的消息实体取出并经过
- RabbitMQ系列(二)基本概念之Publisher
yyueshen
RabbitMQ#RabbitMQ概念rabbitmq分布式
在RabbitMQ中,Publisher(发布者)是负责向RabbitMQ服务器发送消息的客户端角色,通常被称为“生产者”。以下是其核心功能与工作机制的详细解析:一、核心定义与作用消息发送者Publisher将消息发送到RabbitMQ的Exchange(交换机),而非直接发送到队列。Exchange根据消息的RoutingKey(路由键)和绑定规则将消息路由到对应的队列(Queue)。解耦生产与
- RabbitMQ介绍以及基本使用
web13765607643
面试学习路线阿里巴巴rabbitmqqtruby
文章目录一、什么是消息队列?二、消息队列的作用(优点)1、解耦2、流量削峰3、异步4、顺序性三、RabbitMQ基本结构四、RabbitMQ队列模式1、简单队列模式2、工作队列模式3、发布/订阅模式4、路由模式5、主题模式6、RPC模式7、发布者确认模式五、RabbitMQ相关属性描述总结一、什么是消息队列?消息队列是一种用于在分布式系统中进行通信的技术。它是一种存储和转发消息的中间件,可以用于将
- RabbitMQ 学习路线与知识总结
千里码!
后端技术消息队列javarabbitmq学习分布式
以下是RabbitMQ学习路线与知识总结,结合Mermaid生成的脑图,帮助你系统掌握核心概念和实战技巧。编程相关书籍分享:https://blog.csdn.net/weixin_47763579/article/details/145855793DeepSeek使用技巧pdf资料分享:https://blog.csdn.net/weixin_47763579/article/details/1
- RabbitMQ系列(六)基本概念之Routing Key
yyueshen
RabbitMQ#RabbitMQ概念rabbitmq分布式
在RabbitMQ中,RoutingKey(路由键)是用于将消息从交换机(Exchange)路由到指定队列(Queue)的关键参数。其核心作用是通过特定规则匹配绑定关系,确保消息被正确分发。以下是其核心机制与用法的详细说明:一、核心定义与作用消息路由的核心标识生产者发送消息时需指定RoutingKey,交换机根据此值和队列绑定的BindingKey决定消息流向。类比:类似快递单上的“地址”,决定包
- RabbitMQ系列(七)基本概念之Channel
yyueshen
RabbitMQ#RabbitMQ概念rabbitmq分布式
RabbitMQ中的Channel(信道)是客户端与RabbitMQ服务器通信的虚拟会话通道,其核心作用在于优化资源利用并提升消息处理效率。以下是其核心机制与功能的详细解析:一、Channel的核心定义虚拟通信链路Channel是建立在TCP连接(Connection)上的轻量级虚拟连接,允许在单个TCP连接上复用多个独立的信道(Channel)。为了确保其私有性和线程安全性,每个Channel拥
- 为什么要用MQ?
阿杰帅三代
MQMQ
为什么要用MQ?mq是先进先出的数据结构。1.应用解耦项目A要给项目B发送数据,按照传统的做法是通过RPC远程调用,RPC远程调用耦合度非常高。如果使用消息队列,A系统把消息发给mq,B系统只需要订阅,这样就大大的实现了解耦。系统的耦合性越高,容错性就越低。以电商应用为例,用户创建订单后,如果耦合调用库存系统、物流系统、支付系统,任何--个子系统出了故障或者因为升级等原因暂时不可用,都会造成下单操
- RabbitMQ报错:Shutdown Signal channel error; protocol method
web15085096641
面试学习路线阿里巴巴rabbitmq分布式
报错信息:ShutdownSignal:channelerror;protocolmethod:#method(reply-code=406,reply-text=PRECONDITION_FAILED-unknowndeliverytag1,class-id=60,method-id=80)原因默认情况下RabbitMQ是自动ACK(确认签收)机制,就意味着MQ会在消息发送完毕后,自动帮我们去A
- 【六祎 - Note】消息队列的演变,架构图;备忘录; IBM MQ,RabbitMQ,Kafka,Pulsar
鞠崽23333
消息中间件rabbitmqkafka分布式
IBMMQ于1993年推出。它最初称为MQSeries,2002年更名为WebSphereMQ。2014年更名为IBMMQ。IBMMQ是一款非常成功的产品,广泛应用于金融领域。其收入在2020年仍达到10亿美元。RabbitMQ架构与IBMMQ不同,更类似于Kafka的概念。生产者向指定交换类型的交换发布消息。它可以是直接、主题或扇出。然后,交换中心根据不同的消息属性和交换类型将消息路由到队列中。
- 消息队列之 RabbitMQ基本流程
搬砖养女人
数据库架构javaspringtomcatsql
介绍关于消息队列,从前年开始断断续续看了些资料,想写很久了,但一直没腾出空,近来分别碰到几个朋友聊这块的技术选型,是时候把这块的知识整理记录一下了。市面上的消息队列产品有很多,比如老牌的ActiveMQ、RabbitMQ,目前我看最火的Kafka,还有ZeroMQ,去年底阿里巴巴捐赠给Apache的RocketMQ,连redis这样的NoSQL数据库也支持MQ功能。总之这块知名的产品就有十几种,就
- RabbitMQ系列(四)基本概念之Exchange
yyueshen
RabbitMQ#RabbitMQ概念rabbitmq分布式
在RabbitMQ中,Exchange(交换机)是消息路由的核心组件,负责根据规则将生产者发送的消息分发到对应的队列(Queue)中。以下是其核心功能与分类的详细说明:一、Exchange的核心作用消息路由枢纽生产者将消息发送到Exchange,而非直接发送到队列。Exchange根据绑定规则(BindingKey)和路由键(RoutingKey)把消息应转发到对应的队列。类比:类似于邮局系统,E
- 分布式事物在RocketMQ中的应用
冰糖心书房
2025Java面试系列消息中间件分布式rocketmq
RocketMQ4.3版本之后提供了对分布式事务消息的支持,它采用了一种类似于两阶段提交(2PC)的机制,但又有所不同,可以实现最终一致性的分布式事务。RocketMQ的事务消息主要用于解决生产者发送消息和本地事务的原子性问题。应用场景:典型的场景是电商中的下单流程:用户下单,订单服务需要创建订单。同时,需要发送一个消息到库存服务,通知其扣减库存。如果订单创建成功,但消息发送失败,或者消息发送成功
- Spring Boot 整合 RabbitMQ 详解
码农爱java
【RabbitMQ】java-rabbitmqspringbootrabbitmq消息中间件MQ实战
前言:在消息中间件领域中RabbitMQ也是一种非常常见的消息中间件了,本篇简单分享一下SpringBoot项目集成RabbitMQ的过程。RabbitMQ系列文章传送门RabbitMQ的介绍及核心概念讲解@RabbitListener注解详解SpringBoot集成RabbitMQ可以分为三大步,如下:在proerties或者yml文件中添加RabbitMQ配置。项目pom.xml文件中引入sp
- RabbitMQ进阶:深入了解RabbitMQ的重试机制
VksgShapes
rabbitmq分布式
在分布式系统中,消息队列是一种常见的用于解耦和异步通信的工具。RabbitMQ作为一个流行的开源消息队列中间件,提供了可靠的消息传递机制。在实际应用中,消息的传递可能会面临各种问题,例如网络故障、处理失败等。为了应对这些问题,RabbitMQ提供了强大的重试机制,允许消息在处理失败后自动进行重试。本文将介绍RabbitMQ的重试机制,并通过示例代码演示如何使用该机制。RabbitMQ的重试机制Ra
- 阿里架构师推荐的消息中间件万字文档:RocketMQ+RabbitMQ+KafKa
xiaohao718
kafkajava-rabbitmqrabbitmq
RocketMQRocketMQ是阿里开源的消息中间件,目前也已经孵化为Apache顶级项目,它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。RocketMQ思路起源于Kafka,它对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景市面上真正适合学习的RocketMQ资料太少,有的书或资料虽然
- 消息队列概要讲解(下)
Good Note
消息队列golang服务器数据库开发语言MQ消息队列面试
大家好,这里是编程Cookbook,关注公众号「编程Cookbook」,获取更多面试资料。本文概要介绍消息队列的核心原理和实现,以及常见问题及其解决方案等。本文不会过多的扩展详细的消息队列系统,如RocketMQ、RabbitMQ、Kafka等,这些会在后续系列文章中详细介绍。文章目录消息队列的传递模式概念介绍1.推模式(Push)2.拉模式(Pull)3.推拉模式对比4.实际应用中的选择5.混合
- 消息队列(RocketMQ+Kafka)
八千里路云和月laiker
算法rocketmqkafka分布式
基础什么是消息队列:具备生产者,消费者,消息队列的场景应用场景:异步(电商订单的创建、支付、发货流程)解耦削峰填谷(淘宝的双十一)需解决的问题:消息重复(唯一ID,幂等)消息丢失(ack确认机制,死信队列)消息堆积(增加消费者,增加消费能力,增加集群分担)高可用(集群,主从,多副本)高性能(集群,分区,多机部署,负载均衡)RocketMQ整体架构视频:小白debug的视频面试题:CSDN上找的一篇
- 美畅物联丨为什么在物联网应用中,通常更倾向于使用 MQTT 而不是 HTTP?
畅联云平台
物联网http网络协议
最近,我们的后台收到了许多用户的私信咨询,其中一个问题便是:在物联网(IoT)应用中,为何通常更倾向于使用MQTT而非HTTP呢?今天我们就来探讨一下这个话题。前面在介绍MOTT协议的时候我们就已经提到过,MQTT属于一种轻量级的消息传输协议,其协议头相当简洁。正常情况下,MQTT的固定头部仅有2个字节,用来标识消息类型、QoS(服务质量)等级等基本信息。在某些特定的消息类型里,也许会存在可变头部
- 第十一章:服务器信道管理模块
转调
仿Rabbit消息队列c++消息队列
目录第一节:模块介绍第二节:通信协议第三节:信道模块实现3-1.类型别名定义3-2.Channel类3-3.ChannelManager类下期预告:该模块在mqserver目录下实现。第一节:模块介绍服务器信道的作用是处理来自于客户端的各种请求,然后返回一个响应,那么客户端都有哪些请求呢?比如:交换机的声明与创建、队列的声明与创建、绑定与解绑等。请求的种类如此多,信道要怎么识别这些请求,执行对应的
- RabbitMQ系列(零)概要
yyueshen
RabbitMQrabbitmq分布式消息队列
一、消息队列总览1.什么是消息队列?消息队列(MessageQueue)是一种异步通信机制,允许分布式系统中的服务通过生产-消费模型传递数据。其核心价值在于:解耦性:生产者与消费者无需同时在线或直接交互削峰填谷:应对流量突发场景,避免系统过载(如秒杀系统请求缓冲)可靠性:通过持久化、重试机制保障消息不丢失2.典型应用场景场景实现原理案例服务异步化耗时操作异步执行(如日志记录)用户注册后异步发送通知
- RabbitMQ工作模式
霸都阿甘
RabbitMQrabbitmqjava分布式
一、工作模式介绍RabbbitMQ提供了6种工作模式:简单模式、workqueues、Publish/Subscribe发布与订阅模式、Routing路由模式、Topics主题模式、RPC远程调用模式(不太符合MQ)1.1简单模式P:生产者,也就是要发送消息的程序C:消费者,消息的接收者,会一直等待消息到来Queue:消息队列,图中红色部分。类似一个邮箱,可以缓存消息;生产者向其中投递消息,消费者
- [RabbitMQ] RabbitMQ 工作模式介绍
luojbin
#RabbitMQ消息队列rabbitmq
RabbitMQ是现在很常用的一个消息服务中间件,通过不同类型的交换机(Exchange)和不同的路由键(RoutingKey),可以实现不同分发策略,灵活地将消息分发到不同的队列中去.生产者(Producer)先将消息发送到交换机,交换机根据事先设置好的分发策略,将消息分发到不同的队列中,消费者从指定队列中获取消息.生产者需要关注交换机(名称和类型),路由键,而消费者只需要关注队列.在Rabbi
- Java实现的简单双向Map,支持重复Value
superlxw1234
java双向map
关键字:Java双向Map、DualHashBidiMap
有个需求,需要根据即时修改Map结构中的Value值,比如,将Map中所有value=V1的记录改成value=V2,key保持不变。
数据量比较大,遍历Map性能太差,这就需要根据Value先找到Key,然后去修改。
即:既要根据Key找Value,又要根据Value
- PL/SQL触发器基础及例子
百合不是茶
oracle数据库触发器PL/SQL编程
触发器的简介;
触发器的定义就是说某个条件成立的时候,触发器里面所定义的语句就会被自动的执行。因此触发器不需要人为的去调用,也不能调用。触发器和过程函数类似 过程函数必须要调用,
一个表中最多只能有12个触发器类型的,触发器和过程函数相似 触发器不需要调用直接执行,
触发时间:指明触发器何时执行,该值可取:
before:表示在数据库动作之前触发
- [时空与探索]穿越时空的一些问题
comsci
问题
我们还没有进行过任何数学形式上的证明,仅仅是一个猜想.....
这个猜想就是; 任何有质量的物体(哪怕只有一微克)都不可能穿越时空,该物体强行穿越时空的时候,物体的质量会与时空粒子产生反应,物体会变成暗物质,也就是说,任何物体穿越时空会变成暗物质..(暗物质就我的理
- easy ui datagrid上移下移一行
商人shang
js上移下移easyuidatagrid
/**
* 向上移动一行
*
* @param dg
* @param row
*/
function moveupRow(dg, row) {
var datagrid = $(dg);
var index = datagrid.datagrid("getRowIndex", row);
if (isFirstRow(dg, row)) {
- Java反射
oloz
反射
本人菜鸟,今天恰好有时间,写写博客,总结复习一下java反射方面的知识,欢迎大家探讨交流学习指教
首先看看java中的Class
package demo;
public class ClassTest {
/*先了解java中的Class*/
public static void main(String[] args) {
//任何一个类都
- springMVC 使用JSR-303 Validation验证
杨白白
springmvc
JSR-303是一个数据验证的规范,但是spring并没有对其进行实现,Hibernate Validator是实现了这一规范的,通过此这个实现来讲SpringMVC对JSR-303的支持。
JSR-303的校验是基于注解的,首先要把这些注解标记在需要验证的实体类的属性上或是其对应的get方法上。
登录需要验证类
public class Login {
@NotEmpty
- log4j
香水浓
log4j
log4j.rootCategory=DEBUG, STDOUT, DAILYFILE, HTML, DATABASE
#log4j.rootCategory=DEBUG, STDOUT, DAILYFILE, ROLLINGFILE, HTML
#console
log4j.appender.STDOUT=org.apache.log4j.ConsoleAppender
log4
- 使用ajax和history.pushState无刷新改变页面URL
agevs
jquery框架Ajaxhtml5chrome
表现
如果你使用chrome或者firefox等浏览器访问本博客、github.com、plus.google.com等网站时,细心的你会发现页面之间的点击是通过ajax异步请求的,同时页面的URL发生了了改变。并且能够很好的支持浏览器前进和后退。
是什么有这么强大的功能呢?
HTML5里引用了新的API,history.pushState和history.replaceState,就是通过
- centos中文乱码
AILIKES
centosOSssh
一、CentOS系统访问 g.cn ,发现中文乱码。
于是用以前的方式:yum -y install fonts-chinese
CentOS系统安装后,还是不能显示中文字体。我使用 gedit 编辑源码,其中文注释也为乱码。
后来,终于找到以下方法可以解决,需要两个中文支持的包:
fonts-chinese-3.02-12.
- 触发器
baalwolf
触发器
触发器(trigger):监视某种情况,并触发某种操作。
触发器创建语法四要素:1.监视地点(table) 2.监视事件(insert/update/delete) 3.触发时间(after/before) 4.触发事件(insert/update/delete)
语法:
create trigger triggerName
after/before
- JS正则表达式的i m g
bijian1013
JavaScript正则表达式
g:表示全局(global)模式,即模式将被应用于所有字符串,而非在发现第一个匹配项时立即停止。 i:表示不区分大小写(case-insensitive)模式,即在确定匹配项时忽略模式与字符串的大小写。 m:表示
- HTML5模式和Hashbang模式
bijian1013
JavaScriptAngularJSHashbang模式HTML5模式
我们可以用$locationProvider来配置$location服务(可以采用注入的方式,就像AngularJS中其他所有东西一样)。这里provider的两个参数很有意思,介绍如下。
html5Mode
一个布尔值,标识$location服务是否运行在HTML5模式下。
ha
- [Maven学习笔记六]Maven生命周期
bit1129
maven
从mvn test的输出开始说起
当我们在user-core中执行mvn test时,执行的输出如下:
/software/devsoftware/jdk1.7.0_55/bin/java -Dmaven.home=/software/devsoftware/apache-maven-3.2.1 -Dclassworlds.conf=/software/devs
- 【Hadoop七】基于Yarn的Hadoop Map Reduce容错
bit1129
hadoop
运行于Yarn的Map Reduce作业,可能发生失败的点包括
Task Failure
Application Master Failure
Node Manager Failure
Resource Manager Failure
1. Task Failure
任务执行过程中产生的异常和JVM的意外终止会汇报给Application Master。僵死的任务也会被A
- 记一次数据推送的异常解决端口解决
ronin47
记一次数据推送的异常解决
需求:从db获取数据然后推送到B
程序开发完成,上jboss,刚开始报了很多错,逐一解决,可最后显示连接不到数据库。机房的同事说可以ping 通。
自已画了个图,逐一排除,把linux 防火墙 和 setenforce 设置最低。
service iptables stop
- 巧用视错觉-UI更有趣
brotherlamp
UIui视频ui教程ui自学ui资料
我们每个人在生活中都曾感受过视错觉(optical illusion)的魅力。
视错觉现象是双眼跟我们开的一个玩笑,而我们往往还心甘情愿地接受我们看到的假象。其实不止如此,视觉错现象的背后还有一个重要的科学原理——格式塔原理。
格式塔原理解释了人们如何以视觉方式感觉物体,以及图像的结构,视角,大小等要素是如何影响我们的视觉的。
在下面这篇文章中,我们首先会简单介绍一下格式塔原理中的基本概念,
- 线段树-poj1177-N个矩形求边长(离散化+扫描线)
bylijinnan
数据结构算法线段树
package com.ljn.base;
import java.util.Arrays;
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
/**
* POJ 1177 (线段树+离散化+扫描线),题目链接为http://poj.org/problem?id=1177
- HTTP协议详解
chicony
http协议
引言
- Scala设计模式
chenchao051
设计模式scala
Scala设计模式
我的话: 在国外网站上看到一篇文章,里面详细描述了很多设计模式,并且用Java及Scala两种语言描述,清晰的让我们看到各种常规的设计模式,在Scala中是如何在语言特性层面直接支持的。基于文章很nice,我利用今天的空闲时间将其翻译,希望大家能一起学习,讨论。翻译
- 安装mysql
daizj
mysql安装
安装mysql
(1)删除linux上已经安装的mysql相关库信息。rpm -e xxxxxxx --nodeps (强制删除)
执行命令rpm -qa |grep mysql 检查是否删除干净
(2)执行命令 rpm -i MySQL-server-5.5.31-2.el
- HTTP状态码大全
dcj3sjt126com
http状态码
完整的 HTTP 1.1规范说明书来自于RFC 2616,你可以在http://www.talentdigger.cn/home/link.php?url=d3d3LnJmYy1lZGl0b3Iub3JnLw%3D%3D在线查阅。HTTP 1.1的状态码被标记为新特性,因为许多浏览器只支持 HTTP 1.0。你应只把状态码发送给支持 HTTP 1.1的客户端,支持协议版本可以通过调用request
- asihttprequest上传图片
dcj3sjt126com
ASIHTTPRequest
NSURL *url =@"yourURL";
ASIFormDataRequest*currentRequest =[ASIFormDataRequest requestWithURL:url];
[currentRequest setPostFormat:ASIMultipartFormDataPostFormat];[currentRequest se
- C语言中,关键字static的作用
e200702084
C++cC#
在C语言中,关键字static有三个明显的作用:
1)在函数体,局部的static变量。生存期为程序的整个生命周期,(它存活多长时间);作用域却在函数体内(它在什么地方能被访问(空间))。
一个被声明为静态的变量在这一函数被调用过程中维持其值不变。因为它分配在静态存储区,函数调用结束后并不释放单元,但是在其它的作用域的无法访问。当再次调用这个函数时,这个局部的静态变量还存活,而且用在它的访
- win7/8使用curl
geeksun
win7
1. WIN7/8下要使用curl,需要下载curl-7.20.0-win64-ssl-sspi.zip和Win64OpenSSL_Light-1_0_2d.exe。 下载地址:
http://curl.haxx.se/download.html 请选择不带SSL的版本,否则还需要安装SSL的支持包 2. 可以给Windows增加c
- Creating a Shared Repository; Users Sharing The Repository
hongtoushizi
git
转载自:
http://www.gitguys.com/topics/creating-a-shared-repository-users-sharing-the-repository/ Commands discussed in this section:
git init –bare
git clone
git remote
git pull
git p
- Java实现字符串反转的8种或9种方法
Josh_Persistence
异或反转递归反转二分交换反转java字符串反转栈反转
注:对于第7种使用异或的方式来实现字符串的反转,如果不太看得明白的,可以参照另一篇博客:
http://josh-persistence.iteye.com/blog/2205768
/**
*
*/
package com.wsheng.aggregator.algorithm.string;
import java.util.Stack;
/**
- 代码实现任意容量倒水问题
home198979
PHP算法倒水
形象化设计模式实战 HELLO!架构 redis命令源码解析
倒水问题:有两个杯子,一个A升,一个B升,水有无限多,现要求利用这两杯子装C
- Druid datasource
zhb8015
druid
推荐大家使用数据库连接池 DruidDataSource. http://code.alibabatech.com/wiki/display/Druid/DruidDataSource DruidDataSource经过阿里巴巴数百个应用一年多生产环境运行验证,稳定可靠。 它最重要的特点是:监控、扩展和性能。 下载和Maven配置看这里: http
- 两种启动监听器ApplicationListener和ServletContextListener
spjich
javaspring框架
引言:有时候需要在项目初始化的时候进行一系列工作,比如初始化一个线程池,初始化配置文件,初始化缓存等等,这时候就需要用到启动监听器,下面分别介绍一下两种常用的项目启动监听器
ServletContextListener
特点: 依赖于sevlet容器,需要配置web.xml
使用方法:
public class StartListener implements
- JavaScript Rounding Methods of the Math object
何不笑
JavaScriptMath
The next group of methods has to do with rounding decimal values into integers. Three methods — Math.ceil(), Math.floor(), and Math.round() — handle rounding in differen