第七章 NoSQL数据库技术(一)
NoSQL
NoSQL是Not Only SQL的缩写,意即“不仅仅是SQL”,即对关系型SQL数据库系统的补充。
一类非关系数据存储系统
通常不需要一个固定的表的模式
所有的NoSQL淡化了一个或更多的ACID属性
相比传统数据库叫它分布式数据库管理系统更贴切, 数据存储被简化, 重点被放在了分布式数据管理上
简单数据类型--键值
系统只需支持单记录级别的原子性
系统的扩展性
元数据和应用数据的分离
弱一致性,用最终一致性和时间一致性来满足用户对数据一致性的要求
适应数据增长,并且能灵活适应半结构化数据和稀疏数据集。
没有声明性查询语言, 没有预定义的模式,
存储方式灵活包括键-值对存储、列存储、文档存储、图形存储数据库等,
最终一致性,非结构化和不可预知的数据, 遵守CAP定理, 高性能,高可用性和可伸缩性
整体框架

NoSQL的存储类型
列存储数据库,将同一列的数据存储在一起,可以存储结构化和半结构化数据
键值存储数据库,存储的数据是有键(key)和值(value)两部分组成,通过key快速查询到其value,value的格式可以根据具体应用来确定
文档存储数据库,存储的内容是文档型的,可以用格式化文件(类似json、XML等)的格式存储
图存储数据库,数据以有向加权图方式进行存储
CAP理论
分布式数据库系统中的事务是一个分布式操作序列,被操作的数据分布在不同的结点上,分布式事务具有ACID特征
在分布式的环境下设计和部署系统时,有3个核心的需求:CAP对应一致性(Consistency),可用性(Availability)和分区容忍性(Partition Tolerance)
C:在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
A:在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
P:以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
一个分布式系统不可能同时很好的满足一致性、可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
CA - 单点集群,满足一致性,可用性的系统
CP - 满足一致性,分区容忍性的系统
AP - 满足可用性,分区容忍性的系统
一般情况下选择后两种中的其中一种,即满足分区容忍性,在CA之间选其一。
CAP是为了探索不同应用的一致性C与可用性A之间的平衡
在网络或其他原因,通过牺牲一定的一致性C来获得更好的性能与扩展性
在有分隔发生,选择可用性A,集中关注分隔的恢复,需要分隔前、中、后期的处理策略, 及合适的补偿处理机制
BASE
Basically Available --基本可用;系统能够基本运行,一直提供服务。
Soft-state --软状态/柔性事务。"Soft state" 可以理解为"无连接"的, 而 "Hard state" 是"面向连接"的;系统不要求一直保持强一致状态。
Eventual Consistency --最终一致性 系统在某个时刻达到最终一致性。
BASE定义为CAP中AP的衍生,在分布式环境下, BASE是数据的属性,BASE强调基本的可用性,按照功能划分数据库.
BASE的特点是弱一致性、可用性优先、采用乐观方法、适应变化并且简单快捷
一致性可以从客户端和服务器端两个角度来看
客户端关注的是多并发访问的更新过的数据如何获取的问题,对多进程并发进行访问时, 更新的数据在不同进程如何获得不同策略, 决定了不同的一致性。
服务器关注的是更新如何复制分布到整个系统, 以保证最终的一致性。 一致性因为有并发读写才出现问题, 一定要结合并发读写的场地应用要求。 如何要求一段时间后能够访问更新后的数据, 即为最终一致性。
分布式文件系统
分布式文件系统(Distributed File System:DFS )是指文件系统的物理存储资源不在本地节点上,通过计算机网络与节点相连。
DFS--单个访问点和一个逻辑结构,用户透明访问系统中的任何文件
DFS将统一网络中的不同计算机上的共享文件夹组织起来,形成一个单独的、逻辑的、层次式的共享文件系统。
列存储数据库
列式数据库把一列中的数据值串在一起存储起来,然后再存储下一列的数据,以此类推。
查询中的选择规则是通过列来定义的,列式存储数据库是自动索引化的;数据压缩比高,查询速度高
HBase数据模型
HBase 以表的形式表达和存储数据,表由行和列组成,列划分为若干个列族(row family)。
HBase表的逻辑视图是基于行键(rowkey)、列族(column family)、列限定符(column qualifier)和时间版本(version)
HBase没有数据类型,任何列值都被转换成字符串进行存储;
HBase表的每一行可以有不同的列;
相同RowKey的插入操作被认为是同一行的操作。即相同RowKey的二次写入操作,第二次可被可为是对该行某些列的更新操作;列由列族和列名连接而成,分隔符是冒号,如 d:Name (d列族名,Name列名)。
表的存储结构: 逻辑数据模型中空白cell在物理上是不存储的
假设关系型数据库Hblog有3个表格
文章表Article(id, title, content, tags, author_id)
作者表Author(id, name, nickname),
日志表blog(blog_ID, article_id, author_id,pub_time, ...)
用HBASE设计表结构为Hblog, 这里行键是ID, 列族有两个article和author,article列族中有3个列title, content, tags, author列族有2个列name, nickname。

HBase不支持条件查询和Order by等查询,只能按Row key(及其range)或全表扫描;
表创建时只需声明表名和至少一个列族名,每个Column Family为一个存储单元;
Column不用创建表时定义即可以动态新增,同一Column Family的Columns会群聚在一个存储单元上,并依Column key排序
HBAS数据的存储类型: TableName 是字符串;RowKey 和 ColumnName 是二进制值(Java 类型 byte[]);Timestamp 是一个 64 位整数(Java 类型 long);value 是一个字节数组(Java类型 byte[])。
HBASE的数据模型的定义的层次是:
Schema-->Table-->Column Family-->Rowkey-->TimeStamp-->Value
其中:
RowKey:是Byte array,是表中每条记录的“主键”,方便快速查找,Rowkey的设计非常重要。
Column Family:列族,拥有一个名称(string),包含一个或者多个相关列
Column:属于某一个columnfamily,familyName:columnName,每条记录可动态添加
Version Number:类型为Long,默认值是系统时间戳,可由用户自定义
Value(Cell):Byte array 。
HBASE的存储结构:
1、表中所有行都按照row key的字典序排列;
2、Table在行的方向上分割为多个Region;
3、Region按大小分割的,每个表开始只有一个region,随着数据增多,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region,之后会有越来越多的region;
4、Region是Hbase中分布式存储和负载均衡的最小单元,不同Region分布到不同RegionServer上
表Table: 面向列(族)的存储和权限控制,列(族)独立检索的稀疏存储。按行键的字典排序;Table在行的方向上分割多个Region。
区域Region(表的Regions):每个Region存储着Table的若干行,Region是分布式存储的最小单元。
Store(Region中以列族为单位的单元): 区域由一个或者多个Store组成,每个store保存一个列族。Strore由memStore和0至多个StoreFile
StoreFile:以HFile的格式存储在分布式文件系统(HDFS)上
Hbase的系统构架
Hbase是一个分布式的数据库,使用Zookeeper来管理集群。
在架构层面上分为Master和多个RegionServer。
在分布式的生产环境中,HBase 需要运行在 HDFS 之上,由 HDFS提供基础的存储设施,上层提供访问的数据的 API,对HBase 的数据进行管理,
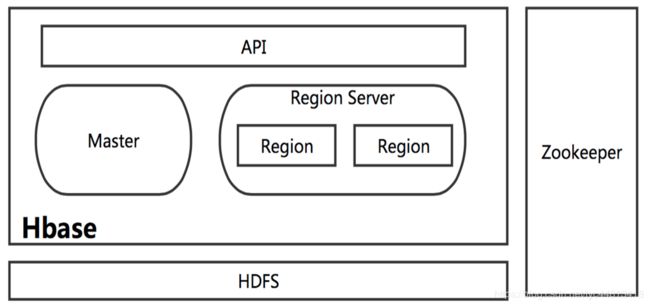
主服务器
管理区域服务器;
指派区域服务器对特定区域服务;
恢复失效的区域服务器,负载均衡和修复时区域服务器
监听ZooKeeper中的状态, 其管理职能包括创建、删除、修改表的定义等;
负责分配区域给区域服务器。
多个Master节点共存,只有一个Master是提供服务的,其他的Master节点处于待命的状态。当正在工作的Master节点失效时,其他的Master则会接管集群。
区域服务器
为区域的访问提供服务,直接为用户提供服务;
负责维护区域的合并与分割; 负责数据存持久化。
管理表格,实现读写操作。
客户端直接连接区域服务器,并通信获取HBase中的数据。
Zookeeper
协调者(Zookeeper),保证任何时候集群中只有一个master, 存储所有Region的寻址入口, 实时监控区域服务器的状态,将Region上线和下线的信息实时通知给Master, 存储Hbse的schema,有哪些table,table有哪些列族。
通过选举,集群中只有一个master处于运行状态。
Zookeeper负责Region和区域服务器的注册。解决分布式环境下数据管理问题:1.统一命名, 2.状态同步, 3.集群管理, 4.配置同步
Client
请求发起者, 通过API,包含访问Hbase的接口,维护着一些cache来加快对Hbase的访问,比如region的位置信息。
访问HBase的接口,并维护cache来加快对HBase的访问,比如region的位置信息. 使用HBase RPC机制与HMaster和区域服务器进行通信.
•Client与HMaster进行通信进行管理类操作.
Client与区域服务器进行数据读写类操作
Hbase组建图
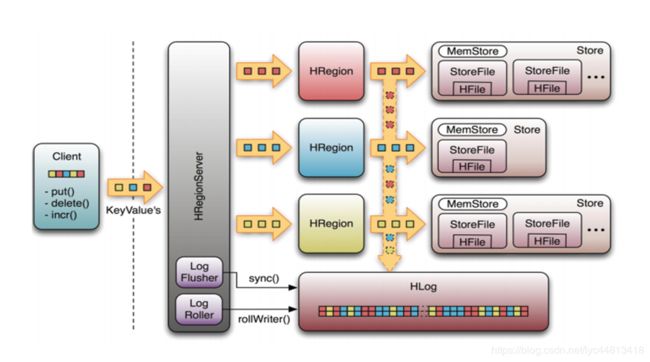
HLog(WAL log): WAL 意为先写日志后记录数据(Write ahead log),用做灾难恢复,Hlog记录数据的所有变更
WAL是HDFS上的一个文件,写操作都先将数据写入日志后,才会真正更新MemStore,最后写入HFile中。
区域服务器失效后,可以从日志文件中读取数据,重做所有的操作,来保证数据的一致性。
日志文件会定期删除旧的文件(已写到HFile中的Log可以删除)
HLog
每个区域服务器维护一个Hlog,而不是每个Region一个。
HLog是一个普通的Hadoop序列文件,它的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,包括table和region名字,sequence number和timestamp,
HLog Sequece File的Value是Hbase的键值对象,即对应HFile中的键值。
键值对数据库
KV:Key-Value(键值)存储模型是Nosql中最基本的数据存储模型, KV类似于哈希表,在键和值之间建立映射关系,键值模型极大的简化了关系数据模型,具有高效灵活的特点。
键值数据库一致性表现在针对单个键的操作包括“获取”、“设置”、或者“删除”, 保证“一致性”, 也可以用“最终一致性模型”实现一致性。
其数据类型:
1 数据结构:键值模型(Key-Value模型),每行记录由主键和值两个部分组成,值可以是各种类型的数据
2 数据操作: Get( key )、Set( key, value )、Delete( key )等
3 数据完整性: 针对单个键的操作才区别“一致性”。
Redis数据库
Redis 是Remote Dictionary Server的缩写,开源的KV数据库
Redis是KV类型的内存数据库
Redis通过Key-Value的单值不同类型来区分, 支持的数据类型:字符串类型(String)、哈希表类型(Hash)、链表类型(List)、集合类型(Set)、有序集合类型(ordered set, zset)
Redis的缺点是数据库容量受到物理内存的限制
Redis可保存多种数据结构,单个值的最大限制是1GB
用List来做FIFO双向链表可实现轻量级的高性能消息队列服务
用Set可做高性能的tag系统等
对存入的KV设置expire时间,通过异步的方式将数据写入磁盘,具有快速和数据持久化的特征
Redis将键值存储在主存中,快速读写
Redis支持主从复制。数据读在slave完成,数据写入在 master 完成
Redis使用RAM作为内存式存储,用虚拟内存来保存数据
Redis支持创建发布和订阅通道
Redis将内存中的数据定期保存到文件系统中,用于故障恢复
Redis有丰富的SDK支持。所有 Redis 的操作都是原子
Redis的每个数据库中的所有数据都是Key-Value对,底层的都是二进制字节数组的格式存放。客户端取的时候需要自己来转换
Redis键值是二进制安全的,用任何二进制序列作为key值。空字符串也是有效key值
1.String
redis最基本的类型,string类型是二进制安全的,string可以包含任何数据。
String是最常用的一种数据类型,可应用于普通的key/ value 存储,具有定时持久化、操作日志及 Replication等功能。
字符串操作包括set、get、decr、incr、mget等, 获取字符串长度、append、设置和获取字符串的某一段内容、设置及获取字符串的某一位(bit)、批量设置一系列字符串的内容等。
2.List
List列表即数组是简单的字符串列表,按照插入顺序排序,lpush、rpush、lpop、rpop、lrange等。l和 r表示左和右。
用来实现twitter的关注列表、粉丝列表等、最新消息排行等功能。
实现为一个双向链表,支持反向查找和遍历,使用时要考虑部分额外的内存开销,发送缓冲队列等也都是用的这个数据结构。
链表
双端:链表节点都有prev和next指针,获取一个节点前置和后置的算法复杂度都为O(1)。
无环:list的第一个节点(头节点)的prev和最后一个节点(尾节点)的next都指向NULL。
带表头指针和表尾指针:通过list的head和tail两个指针,链表的头和尾进行操作。
带链表长度计数器:可以通过len成员来获取链表的节点的个数,复杂度O(1)。
多态:链表使用void *指针来保存value,并且可以通过dup,free,match来操控节点的value值,因此,该链表可以保存任意类型的值。
3.Hash
Hash(哈希)是一个键值对集合,一个 string 类型的 field 和 value 的映射表。常用命令:hget、hset、hgetall等。
实例:用户信息包含:ID为key,value包含姓名、年龄、生日、专业等信息,如果用普通的key/value结构来存储:
第一种:将用户ID作为查找key,其他信息封装成一个对象以序列化的方式存储。
第二种:把用户信息对象中所有成员都存成单个key-value对,用用户ID+对应属性的名称作为唯一标识来标示对应属性值。
4.Set
Redis中的集合是string类型一个无序的、去重的集合, 元素是字符串类型。
对外提供的功能是一个列表,set是自动排重的,用set存储一个列表数据且数据不重复
set 的内部实现是一个 value永远为null的HashMap,通过计算hash的方式来快速排重的
存储(sadd)、删除(srem)、读取(smembers)、元素是否存在(sismember)、差集运算(sdiff)、交集运算(sinter)、并集运算(sunion)、获取元素数量(scard)、随机获得元素(srandmember)、存储差集(sdiffstore)、交集(sinterstore)和并集(sunionstore)等。
5.Sorted set/zset
有序集合的操作类似Set集合,有序的、去重的、元素是字符串类型、不允许重复的成员,每一个元素都关联着一个浮点数分值(Score),按照分值从小到大的顺序排列集合中的元素。
成员唯一的,但分数(score)可重复。
常用命令:zadd、zrange、zrem、zcard等
通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。
内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序
HashMap里放的是成员到score的映射,
跳跃表里存放的是所有的成员,排序依据是HashMap里存的score
Redis实现原则
数据库的操作、集群的设置简单, Redis内部维护一个db数组,每个db都是一个数据库,默认16个数据库。用select命令来切换数据库。 存储效率(memory efficiency)的考虑,可压缩数据、减少内存碎片、高速缓存和外存的数据交换算法等问题; 快速响应时间(fast response time)与高吞吐量(high throughput)的折中方案; 单线程(single-threaded): 简化数据结构和算法的实现,通过异步IO和pipelining等机制来实现高速的并发访问。
Redis复制功能
Redis复制主要包括RDB复制和AOF复制,RDB快照方式,AOF通过将发送到服务器的写操作命令记录下来,形成AOF文件。 在RDB复制中,每次执行特定的命令(SAVE或BGSAVE)时创建一个新的RDB文件时,过期的键不保存到新创建的RDB文件中。载入时,过期键就不载入。 当使用AOF,过期键删除之后,程序会向AOF文件追加一条删除命令
Redis的存储管理
Redis是一个内存数据库,内存中的数据划分:
1)数据:数据库中的数据占用的内存会统计在used_memory
2)进程运行的内存:代码、常量池等等要占用内存,子进程运行
3)缓冲内存
4)内存碎片
Redis数据库的系统结构—集群
分布式数据处理: 提供在多个Redis间节点间共享数据的程序集。 Redis 集群的数据分片,引入了 哈希槽的概念。 集群有16384个哈希槽 (hash slot),每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽
集群结构
Redis cluster集群中的每个节点都是平等的关系,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接。 数据存在一个 master 节点,master 和其对应的salve 之间进行数据同步。当读取数据到对应的 master 。Master挂掉,启动一个对应的 salve 节点,充当 master 。 客户端与redis节点直连,连接集群中任何一个可用节点即可。redis-cluster把所有的物理节点映射到[0-16383]槽上,cluster 负责维护node<->slot<->value。
主从复制
在从节点配置文件加上从服务器的IP地址和端口号。通过主服务器持久化的rdb文件实现的。主服务器先导出内存快照文件,然后将rdb文件传给从服务器,从服务器根据rdb文件重建内存表。 Redis 支持简易的主从复制(master-slave replication)功能, 让从服务器成为主服务器的精确复制品。
1)从服务器,连接到主服务器, 发送SYNC
2)主服务器接受SYNC,fork一个子进程,把内存数据保存为文件,发送给从服务器
3)主服务器子进程做数据快照时,父进程继续接收client端写数据,新据放待发送缓存队列中
4)从服务器接收内存快照,清空内存数据,重建内存表数据结构
5)主服务器发送缓存队列中保存的子进程快照期间改变的数据给从服务器,保存数据一致性
6)主服务器后续接收的数据,都会通过步骤1建立的连接,把数据发送到从服务器
持久化机制
redis内存数据库, 将内存中的数据周期性的写入磁盘或者把操作追加到记录文件中---redis的持久化。 redis支持两种方式的持久化: RDB方式和AOF方式 RDB方式是将内存中的数据的快照以二进制的方式写入名字为 dump.rdb的文件中。 AOF方式,AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集。
Redis数据库的API
redis-cli进入shell,可以用命令Config, key 可以获取配置信息或键值的情况。 对string类型的操作可以用set, get, incr lists列表是链表,LPUSH、RPUSH、LRANGE等, 集合set一种无序的集合,sadd、删除已有元素、取交集、sunion、取差集等。 sorted sets有序集合中的每个元素都关联一个序号(score),zsets,操作有zrange、zadd、zrevrange、zrangebyscore等等; 哈希hashes,hashes存的是字符串和字符串值之间的映射,比如一个用户要存储其全名、姓氏、年龄等等,就很适合使用哈希。