本文始发于个人公众号:TechFlow,原创不易,求个关注
今天是机器学习专题第28篇文章,我们来聊聊SVD算法。
SVD的英文全称是Singular Value Decomposition,翻译过来是奇异值分解。这其实是一种线性代数算法,用来对矩阵进行拆分。拆分之后可以提取出关键信息,从而降低原数据的规模。因此广泛利用在各个领域当中,例如信号处理、金融领域、统计领域。在机器学习当中也有很多领域用到了这个算法,比如推荐系统、搜索引擎以及数据压缩等等。
SVD简介
我们假设原始数据集矩阵D是一个mxn的矩阵,那么利用SVD算法,我们可以将它分解成三个部分:
这三个矩阵当中U是一个m x n的矩阵,是一个m x n的对角矩阵,除了对角元素全为0,对角元素为该矩阵的奇异值。V是一个n x n的矩阵。U和V都是酉矩阵,即满足。也就是它乘上它的转置等于单位对角矩阵。
我们可以看下下图,从直观上感知一下这三个矩阵。
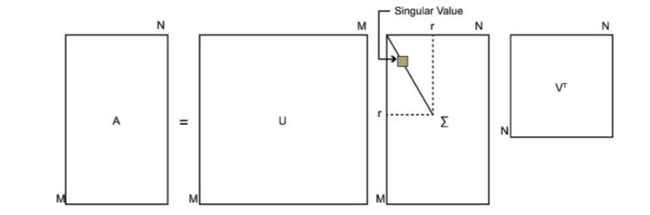
下面我们来简单推导一下SVD的求解过程,看起来很复杂,概念也不少,但是真正求解起来却并不难。会需要用到矩阵特征值分解的相关概念,如果不熟悉的同学可以先看下线性代数专题相关内容做个回顾:
线性代数精华——矩阵的特征值与特征向量
首先,如果我们计算可以得到一个n x n的方阵。对于方阵我们可以对它进行特征分解,假设得到特征值是,特征向量是,代入特征值的性质可以得到:
这样的特征值和特征向量一共会有n个,我们把它所有的特征向量组合在一起,可以得到一个n x n的矩阵V。它也就是我们SVD分解结果之后的V,所以有些书上会把它叫做右奇异向量。
同理,我们计算可以得到一个m x m的方阵,我们同样可以对他进行特征值分解,得到一个特征矩阵U。U应该是一个m x m的矩阵,也就是SVD公式中的U,我们可以将它称为A的左奇异向量。
U和V都有了,我们只剩下还没求出来了。由于它是一个对角矩阵,除了对角元素全为0,所以我们只需要求出它当中的每一个对角元素,也就是奇异值就可以了,我们假设奇异值是,我们对SVD的式子进行变形:
这个推导当中利用了V是酉矩阵的性质,所以我们乘上了V将它消除,就推导得到了奇异值的公式,矩阵也就不难求了。
整个推导的过程不难,但是有一个问题没解决,为什么的特征矩阵就是SVD中的U矩阵了,原理是什么?这一步是怎么推导来的?说实话我也不知道天才数学家们这一步是怎么推导得到的,我实在脑补不出来当时经过了怎样的思考才得到了这个结果,但是想要证明它是正确的倒不难。
这里也同样利用了酉矩阵的性质,还有对角矩阵乘法的性质。我们可以看出来,U的确是特征向量组成的矩阵,同样也可以证明V。其实如果眼尖一点还可以发现特征值矩阵等于奇异值矩阵的平方,所以
所以,我们求解矩阵可以不用很麻烦地通过矩阵去计算,而是可以通过的特征值取平方根来求了。
SVD的用途
我们推导了这么多公式,那么这个SVD算法究竟有什么用呢?
看来看去好像看不出什么用途,因为我们把一个矩阵变成了三个,这三个矩阵的规模也并没有降低,反而增加了。但是如果去研究一下分解出来的奇异值,会发现奇异值降低的特别快。只要10%甚至是1%的奇异值就占据了全部奇异值之和的99%以上的比例。
换句话说,我们并不需要完整的SVD分解结果,而是只需要筛选出其中很少的k个奇异值,和对应的左右奇异向量就可以近似描述原矩阵了。
我们看下下图,相当于我们从分解出来的矩阵当中筛选一小部分来代替整体,并且保留和整体近似的信息。
我们把式子写出来:
这里的k远小于n,所以我们可以大大降低SVD分解之后得到的矩阵参数的数量。

也就是说,我们通过SVD分解,将一个m x n的大矩阵,分解成了三个小得多的小矩阵。并且通过这三个小矩阵,我们可以还原出原矩阵大部分的信息。不知道大家有没有想到什么?是了,这个和我们之前介绍的PCA算法如出一辙。不仅思路相似,就连计算的过程也重合度非常高,实际上PCA算法的求解方法之一就是通过SVD矩阵分解。
SVD与PCA
我们来简单看看SVD和PCA之间的关联。
首先复习一下PCA算法,我们首先计算出原始数据的协方差矩阵X,再对进行矩阵分解,找到最大的K个特征值。然后用这K个特征值对应的特征向量组成的矩阵来对原始数据做矩阵变换。
在这个过程当中,我们需要计算,当X的规模很大的时候,这个计算开销也是很大的。注意到我们在计算SVD中V矩阵的时候,也用到了矩阵的特征值分解。然而关键是一些计算SVD的算法可以不先求出协方差矩阵也能得到V,就绕开了这个开销很大的步骤。
所以目前流行的PCA几乎都是以SVD为底层机制实现的,比如sklearn库中的PCA工具就是用的SVD。
代码实现
关于SVD算法我们并不需要自己实现,因为numpy当中封装了现成的SVD分解方法。
我们直接调用np.linalg.svd接口即能完成矩阵的分解:
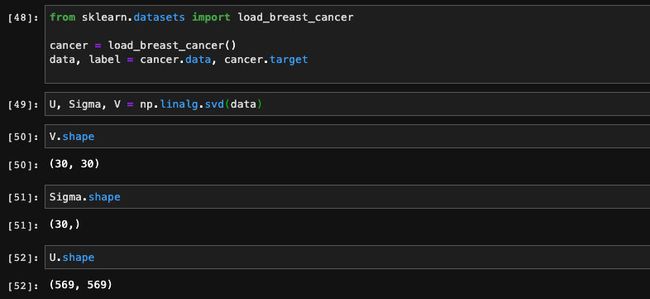
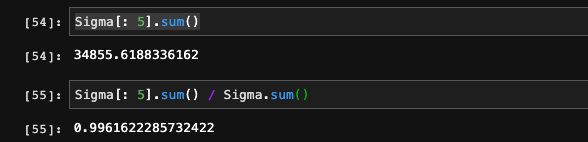
这里的Sigma返回的是一个向量,代替了对角矩阵,节省了存储开销。我们可以通过找出最小的K,使得K个奇异值占据整体奇异值95%以上的和。这里可以看到,我们选出了5个奇异值就占据所有奇异值和的99%以上:
总结
我们今天和大家分享了SVD算法的原理,以及一种常规的计算方法。SVD和PCA一样底层都是基于矩阵的线性操作完成的,通过SVD的性质,我们可以对原数据进行压缩和转化。基于这一点,衍生出了许多的算法和应用场景,其中最经典的要属推荐系统中的协同过滤了。由于篇幅限制,我们将会在下一篇文章当中和大家分享这一点,实际了解一下SVD的应用,加深一下理解。
由于SVD可以实现并行化计算,使得在实际当中它更受欢迎。但SVD也不是万能的,它一个很大的缺点就是和PCA一样解释性很差,我们无法得知某些值或者是某些现象的原因。关于这一点,我们也会在下一篇文章当中加以体现。
今天的文章到这里就结束了,如果喜欢本文的话,请来一波素质三连,给我一点支持吧(关注、转发、点赞)。
本文使用 mdnice 排版
