ThreadLocal基本操作
构造函数
ThreadLocal的构造函数签名是这样的:
/**
* Creates a thread local variable.
* @see #withInitial(java.util.function.Supplier)
*/
public ThreadLocal() {
}
内部啥也没做。
initialValue函数
initialValue函数用来设置ThreadLocal的初始值,函数签名如下:
protected T initialValue() {
return null;
}
该函数在调用get函数的时候会第一次调用,但是如果一开始就调用了set函数,则该函数不会被调用。通常该函数只会被调用一次,除非手动调用了remove函数之后又调用get函数,这种情况下,get函数中还是会调用initialValue函数。该函数是protected类型的,很显然是建议在子类重载该函数的,所以通常该函数都会以匿名内部类的形式被重载,以指定初始值,比如:
package com.winwill.test;
/**
* @author qifuguang
* @date 15/9/2 00:05
*/
public class TestThreadLocal {
private static final ThreadLocal<Integer> value = new ThreadLocal<Integer>() {
@Override
protected Integer initialValue() {
return Integer.valueOf(1);
}
};
}
get函数
该函数用来获取与当前线程关联的ThreadLocal的值,函数签名如下:
如果当前线程没有该ThreadLocal的值,则调用initialValue函数获取初始值返回。
set函数
set函数用来设置当前线程的该ThreadLocal的值,函数签名如下:
设置当前线程的ThreadLocal的值为value。
remove函数
remove函数用来将当前线程的ThreadLocal绑定的值删除,函数签名如下:
在某些情况下需要手动调用该函数,防止内存泄露。
代码演示
学习了最基本的操作之后,我们用一段代码来演示ThreadLocal的用法,该例子实现下面这个场景:
有5个线程,这5个线程都有一个值value,初始值为0,线程运行时用一个循环往value值相加数字。
代码实现:
package com.winwill.test;
/**
* @author qifuguang
* @date 15/9/2 00:05
*/
public class TestThreadLocal {
private static final ThreadLocal value = new ThreadLocal() {
@Override
protected Integer initialValue() {
return 0;
}
};
public static void main(String[] args) {
for (int i = 0; i < 5; i++) {
new Thread(new MyThread(i)).start();
}
}
static class MyThread implements Runnable {
private int index;
public MyThread(int index) {
this.index = index;
}
public void run() {
System.out.println("线程" + index + "的初始value:" + value.get());
for (int i = 0; i < 10; i++) {
value.set(value.get() + i);
}
System.out.println("线程" + index + "的累加value:" + value.get());
}
}
}
执行结果为:
线程0的初始value:0
线程3的初始value:0
线程2的初始value:0
线程2的累加value:45
线程1的初始value:0
线程3的累加value:45
线程0的累加value:45
线程1的累加value:45
线程4的初始value:0
线程4的累加value:45
可以看到,各个线程的value值是相互独立的,本线程的累加操作不会影响到其他线程的值,真正达到了线程内部隔离的效果。
如何实现的
看了基本介绍,也看了最简单的效果演示之后,我们更应该好好研究下ThreadLocal内部的实现原理。如果给你设计,你会怎么设计?相信大部分人会有这样的想法:
每个ThreadLocal类创建一个Map,然后用线程的ID作为Map的key,实例对象作为Map的value,这样就能达到各个线程的值隔离的效果。
没错,这是最简单的设计方案,JDK最早期的ThreadLocal就是这样设计的。JDK1.3(不确定是否是1.3)之后ThreadLocal的设计换了一种方式。
我们先看看JDK8的ThreadLocal的get方法的源码:
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
其中getMap的源码:
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
setInitialValue函数的源码:
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
createMap函数的源码:
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
简单解析一下,get方法的流程是这样的:
- 首先获取当前线程
- 根据当前线程获取一个Map
- 如果获取的Map不为空,则在Map中以ThreadLocal的引用作为key来在Map中获取对应的value e,否则转到5
- 如果e不为null,则返回e.value,否则转到5
- Map为空或者e为空,则通过initialValue函数获取初始值value,然后用ThreadLocal的引用和value作为firstKey和firstValue创建一个新的Map
然后需要注意的是Thread类中包含一个成员变量:
ThreadLocal.ThreadLocalMap threadLocals = null;
所以,可以总结一下ThreadLocal的设计思路:
每个Thread维护一个ThreadLocalMap映射表,这个映射表的key是ThreadLocal实例本身,value是真正需要存储的Object。
这个方案刚好与我们开始说的简单的设计方案相反。查阅了一下资料,这样设计的主要有以下几点优势:
- 这样设计之后每个Map的Entry数量变小了:之前是Thread的数量,现在是ThreadLocal的数量,能提高性能,据说性能的提升不是一点两点(没有亲测)
- 当Thread销毁之后对应的ThreadLocalMap也就随之销毁了,能减少内存使用量。
再深入一点
先交代一个事实:ThreadLocalMap是使用ThreadLocal的弱引用作为Key的:
static class ThreadLocalMap {
/**
* The entries in this hash map extend WeakReference, using
* its main ref field as the key (which is always a
* ThreadLocal object). Note that null keys (i.e. entry.get()
* == null) mean that the key is no longer referenced, so the
* entry can be expunged from table. Such entries are referred to
* as "stale entries" in the code that follows.
*/
static class Entry extends WeakReference> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal k, Object v) {
super(k);
value = v;
}
}
...
...
}
下图是本文介绍到的一些对象之间的引用关系图,实线表示强引用,虚线表示弱引用:
<img src="https://pic2.zhimg.com/50/9671b789e1da4f760483456c03e4f4b6_hd.jpg" data-rawwidth="1710" data-rawheight="1074" class="origin_image zh-lightbox-thumb" width="1710" data-original="https://pic2.zhimg.com/9671b789e1da4f760483456c03e4f4b6_r.jpg">
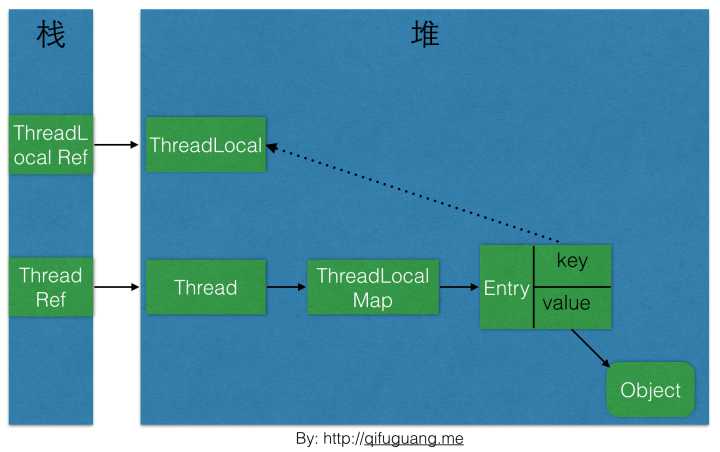
然后网上就传言,ThreadLocal会引发内存泄露,他们的理由是这样的:
如上图,ThreadLocalMap使用ThreadLocal的弱引用作为key,如果一个ThreadLocal没有外部强引用引用他,那么系统gc的时候,这个ThreadLocal势必会被回收,这样一来,ThreadLocalMap中就会出现key为null的Entry,就没有办法访问这些key为null的Entry的value,如果当前线程再迟迟不结束的话,这些key为null的Entry的value就会一直存在一条强引用链:
ThreadLocal Ref -> Thread -> ThreaLocalMap -> Entry -> value
永远无法回收,造成内存泄露。
我们来看看到底会不会出现这种情况。 其实,在JDK的ThreadLocalMap的设计中已经考虑到这种情况,也加上了一些防护措施,下面是ThreadLocalMap的getEntry方法的源码:
private Entry getEntry(ThreadLocal key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
getEntryAfterMiss函数的源码:
private Entry getEntryAfterMiss(ThreadLocal key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
while (e != null) {
ThreadLocal k = e.get();
if (k == key)
return e;
if (k == null)
expungeStaleEntry(i);
else
i = nextIndex(i, len);
e = tab[i];
}
return null;
}
expungeStaleEntry函数的源码:
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// expunge entry at staleSlot
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
// Rehash until we encounter null
Entry e;
int i;
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal k = e.get();
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
// Unlike Knuth 6.4 Algorithm R, we must scan until
// null because multiple entries could have been stale.
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}
整理一下ThreadLocalMap的getEntry函数的流程:
- 首先从ThreadLocal的直接索引位置(通过ThreadLocal.threadLocalHashCode & (len-1)运算得到)获取Entry e,如果e不为null并且key相同则返回e;
- 如果e为null或者key不一致则向下一个位置查询,如果下一个位置的key和当前需要查询的key相等,则返回对应的Entry,否则,如果key值为null,则擦除该位置的Entry,否则继续向下一个位置查询
在这个过程中遇到的key为null的Entry都会被擦除,那么Entry内的value也就没有强引用链,自然会被回收。仔细研究代码可以发现,set操作也有类似的思想,将key为null的这些Entry都删除,防止内存泄露。 但是光这样还是不够的,上面的设计思路依赖一个前提条件:要调用ThreadLocalMap的genEntry函数或者set函数。这当然是不可能任何情况都成立的,所以很多情况下需要使用者手动调用ThreadLocal的remove函数,手动删除不再需要的ThreadLocal,防止内存泄露。所以JDK建议将ThreadLocal变量定义成private static的,这样的话ThreadLocal的生命周期就更长,由于一直存在ThreadLocal的强引用,所以ThreadLocal也就不会被回收,也就能保证任何时候都能根据ThreadLocal的弱引用访问到Entry的value值,然后remove它,防止内存泄露。