爬虫实战 爬取豆瓣top250电影(BeautifulSoup) 2020最新 详细讲解分析思路
目标
#2020.5.20
#目标:爬取前豆瓣top250的电影名称,评分,主演,上映日期,简介
#问题:第189个电影没主演···
#此次爬虫练习主要用于练习BeautifulSoup
(如果需要看正则表达式,可以看之前猫眼top100电影爬取)
网页分析
本次爬取的网站url为https://movie.douban.com/top250。
打开网页之后,我们发现它是一个分页的展示,250部电影被分成10页,每页25部。
然后观察他们每页的url。比如第2页和第4页:
https://movie.douban.com/top250?start=25&filter=
https://movie.douban.com/top250?start=75&filter=
发现规律,其中start参数便是不同分页的关键,第2页是125,而第4页是325(从0开始计数,filter是个无用参数)。
所以我们便以https://movie.douban.com/top250?start=为基础的url。
从0开始到9,每次*25和上面的基础url拼接便得到了10个分页的url。
下一步就是从每个分页上抓取25部电影的url。
我们选中第一部电影的标题,发现其url的位置如下图所示。

具体的特征结构就是如下:
<div id=content
<ol class='grid_view'
<li
<div class='hd'
<a href= 我们要的url
<li
...
先找到id为content的div,再找到下面的ol,然后找到下面的每个li,将其中的第一个a中href属性值提取,便是我们要的25部电影的url了。代码如下:
ol = soup.select('div#content ol')
lis = ol[0].find_all('li')
for li in lis:
a = li.find('a')
yield a['href']
接下来是进入每部电影的页面,爬取其中的电影名称,评分,主演,上映日期,简介。我们一个个看。
第一步是抓取名称
如下图所示,名称位置如此:

可以看到名称的位置特点为:
<h1
<span 名称
所以我们通过h1标签来访问其第一个子标签,便可以得到。代码如下:
spans = soup.select('h1 span')
movie_name = spans[0].get_text()
下一步是获取分数。
分数的位置如下图所示:

其位置特征为:
<div id = interest_sectl
<strong 分数
所以通过id为interest_sectl来访问其子孙节点strong即可。
代码为:
div_sectl = soup.find('div',id='interest_sectl')
strong = div_sectl.find('strong')
movie_score = strong.get_text()
下面是来抓取演员信息。
同样其位置如下:

它的结构特征如下:
<span class = actor
<span class = attrs
<span 主演
同样,一层层去寻找即可。这里遇到一个问题,就是第189部电影《二十二》它没主演,这就有点尴尬了,所以这里给它整一个try-catch,防止错误停止
代码如下:
try:
span_attrs = soup.select('span[class="actor"]
span[class="attrs"]')[0]
movie_actors = span_attrs.get_text()
except:
movie_actors = ''
然后是抓取上映日期,这里的位置如下图
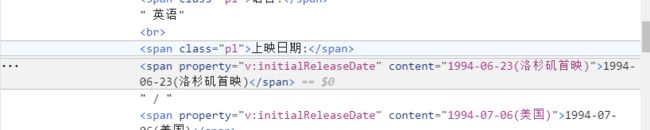
因为span过多,而且class都相同,不太好定位。
但是找到一个规律
![]()
其结构特征如下:
<span class= pl 上映日期(字符串)
<span 日期
上映日期前面都会有“上映日期”,所以便先定位该字符串,再定位字符串的父节点,之后再找其下一兄弟节点便ok了。
写出代码如下:
string_previous = soup.find(string='上映日期:')
span_previous = string_previous.parent
movie_date = span_previous.next_sibling.next_sibling.get_text()
最后是爬取电影简介了,和上面一样,这步比较简单。

直接放代码了
movie_introduction = soup.find('div',id='link-report',class_='indent').get_text().strip()
至此,整个分析过程就结束了,关键的代码也写完了,下面就上完整的代码吧。
完整代码
#2020.5.20
#author:pmy
#目标:爬取前豆瓣top250的电影名称,评分,主演,上映日期,简介
#问题:第189个电影没主演···所以需要一个try-catch
#此次爬虫练习主要用于练习BeautifulSoup
import requests
from bs4 import BeautifulSoup
import time
import json
base_url='https://movie.douban.com/top250?start='
#test_url='https://movie.douban.com/subject/1292720/'#用于测试
headers = {
'Host': 'movie.douban.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
#获取当前单个url的html
def get_response(url):
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
except requests.ConnectionError as e:
print('Error', e.args)
#获取当前页面的所有子链接 25个
def get_url(page):
url = base_url+str(page)
html = get_response(url)
soup = BeautifulSoup(html,'html.parser')
ol = soup.select('div#content ol')
lis = ol[0].find_all('li')
for li in lis:
a = li.find('a')
yield a['href']
###########分析
# div id=content
# ol class='grid_view'
# li
# div class='hd'
# a href=
# li
# ...
#获取一部电影信息
def get_data(url):
html = get_response(url)
soup = BeautifulSoup(html,'html.parser')
#名称
spans = soup.select('h1 span')
movie_name = spans[0].get_text()
#得分
div_sectl = soup.find('div',id='interest_sectl')
strong = div_sectl.find('strong')
movie_score = strong.get_text()
#演员
try:
span_attrs = soup.select('span[class="actor"] span[class="attrs"]')[0]
movie_actors = span_attrs.get_text()
except:
movie_actors = ''
#上映日期
string_previous = soup.find(string='上映日期:')
span_previous = string_previous.parent
movie_date = span_previous.next_sibling.next_sibling.get_text()
#简介
movie_introduction = soup.find('div',id='link-report',class_='indent').get_text().strip()
return {
'movie_name':movie_name,
'movie_actors':movie_actors,
'movie_score':movie_score,
'movie_date':movie_date,
'movie_introduction':movie_introduction
}
###################分析
# h1
# span 名称
# div id = interest_sectl
# strong 分数
# span class = actor
# span class = attrs
# span 主演
# span class= pl 上映日期(字符串)
# span 日期
#存储到txt文件中
def save_data(data,count):
filename = 'result'+str(count)+'.txt'
with open(filename, 'a', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False) + '\n')
f.close()
if __name__ == '__main__':
for i in range(10):
page = i*25
#获取每个页面的25个链接
urls = get_url(page)
for url in urls:
#对每部电影抓取信息并存储
save_data(get_data(url),i)
time.sleep(1)
print('第'+str(i)+'页完成')
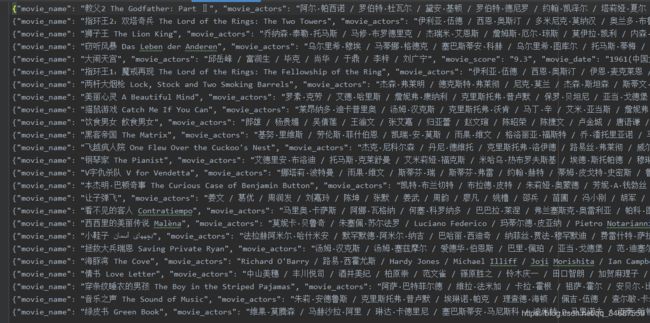
抓取结果
一共存储到10个txt文件
每个文件的结果如图: