深入理解计算机系统第二章第一节 信息存储
第二章 信息的表示和处理
现代计算机存储和处理的信息以二值信号表示。 这些微不足道的二进制数字, 或者称为位(bit), 形成了数字革命的基础。 大家熟悉并使用了 1000多年的十进制(以 10为基数)起源千印度, 在12世纪被阿拉伯数学家改进, 并在13世纪被意大利数学家Leonardo Pisano(大约公元1170-1250, 更为大家所熟知的名字是Fibonacci)带到西方。 对千有 10个手指的人类来说, 使用十进制表示法是很自然的事情, 但是当构造存储和处理信息的机器时, 二进制值工作得更好。 二值信号能够很容易地被表示、 存储和传输, 例如, 可以表示为穿孔卡片上有洞或无洞、 导线上的高电压或低电压, 或者顺时针或逆时针的磁场。 对 二值信号进行存储和执行计算的电子电路非常简单和可靠, 制造商能够在一个单独的硅片上集成数百万甚至数十亿个这样的电路。
孤立地讲, 单个的位不是非常有用。 然而, 当把位组合在一起, 再加上某种解释(interpretation) , 即赋予不同的可能位模式以含意, 我们就能够表示任何有限集合的元素。 比如, 使用一个二进制数字系统, 我们能够用位组来编码非负数。 通过使用标准的字符码,我们能够对文档中的字母和符号进行编码。 在本章中, 我们将讨论这两种编码, 以及负数表示和实数近似值的编码。
我们研究三种最重要的数字表示。 无符号(unsigned)编码基千传统的二进制表示法,表示大于或者等于零的数字。 补码(two’s-complement)编码是表示有符号整数的最常见的方式, 有符号整数就是可以为正或者为负的数字。 浮点数(floating-point)编码是表示实数的科学记数法的以 2为基数的版本。 计算机用这些不同的表示方法实现算术运算, 例如加法和乘法, 类似于对应的整数和实数运算。
计算机的表示法是用有限数量的位来对一个数字编码, 因此, 当结果太大以至不能表 示时, 某些运算就会溢出(overflow)。 溢出会导致某些令人吃惊的后果。 例如, 在今天的大多数计算机上(使用32位来表示数据类型int), 计算表达式200300400*500会得出结果-884 901 888。这违背了整数运算的特性,计算一组正数的乘积不应产生一个负的结果。
另一方面,整数的计算机满足人们所熟知的真正整数运算的许多性质。例如,利用乘法的结合律和交换律,计算下面任何一个C表达式,都会得出结果-884 901 888:
(500 * 400) * (300 * 200)
((500 * 400) * 300) * 200
((200 * 500) * 300) * 400
400 * (200 * (300 * 500))
计算机可能没有产生期望的结果, 但是至少它是一致的!
浮点运算有完全不同的数学属性。 虽然溢出会产生特殊的值+=, 但是一组正数的乘积总是正的。 由千表示的精度有限, 浮点运算是不可结合的。 例如, 在大多数机器上, c 表达式(3.14+1e20)-le20 求得的值会是o. 0, 而3.14+(le20-le20)求得的值会是3. 14。整数运算和浮点数运算会有不同的数学属性是因为它们处理数字表示有限性的方式不同 整数的表示虽然只能编码一个相对较小的数值范围, 但是这种表示是精确的;而浮点数虽然可以编码一个较大的数值范酣, 但是这种表示只是近似的。
通过研究数字的实际表示, 我们能够了解可以表示的值的范围和不同算术运算的属性。 为了使编写的程序能在全部数值范围内正确工作, 而且具有可以跨越不同机器、 操作系统和编译器组合的可移植性, 了解这种属性是非常重要的。 后面我们会讲到, 大量计算 机的安全涌洞都是由千计算机算术运算的微妙细节引发的。 在早期, 当人们碰巧触发了程 序漏洞, 只会给人们带来一些不便, 但是现在,有众多的黑客企图利用他们能找到的任何漏洞, 不经过授权就进入他人的系统。 这就要求程序员有更多的责任和义务, 去了解他们 的程序如何工作,以及如何被迫产生不良的行为。
计算机用几种不同的二进制表示形式来编码数值。 随着第3章进入机器级编程,你需 要熟悉这些表示方式。 在本章中,我们描述这些编码, 并且教你如何推出数字的表示。
通过直接操作数字的位级表示,我们得到了几种进行算术运算的方式。 理解这些技术对于理解编译器产生的机器级代码是很重要的,编译器会试图优化算术表达式求值的性能。
我们对这部分内容的处理是基千一组核心的数学原理的。 从编码的基本定义开始, 然后得出 些属性, 例如可表示的数字的范围、 它们的位级表示以及算术运算的属性。 我们相信从这样一个抽象的观点来分析这些内容, 对你来说是很重要的, 因为程序员需要对计 算机运算与更为人熟悉的整数和实数运算之间的关系有清晰的理解。
怎样阅读本章
本章我们研究在计算机上如何表示数宇和其他形式数据的基本属性, 以及计算机对 这些数据执行操作的属性。 这就要求我们深入研究数学语言,编写公式和方程式, 以及 展示重要属性的推导。
为了帮助你阅读, 这部分内容安排如下: 首先给出以数学形式表示的属性, 作为原 理。 然后,用例子和非形式化的讨论来解释这个原理。 我们建议你反复阅读原理描述和 它的示例与讨论,直到你对该属性的说明内容及其重要性有了牢固的直觉。 对于更加复杂的属性, 还会提供推导, 其结构看上去将会像一个数学证明。 虽然最终你应该尝试理 解这些推导, 但在第一次阅读时你可以跳过它们。
我们也鼓励你在阅读正文的过程中完成练习题, 这会促使你主动学习, 帮助你理论联 系实际。 有了这些例题和练习题作为背景知识, 再返回推导,你将发现理解起来会容易许 多。 同时, 请放心, 掌握好高中代数知识的人都具备理解这些内容所需要的数学技能。
C++编程语言建立在C语言基础之上, 它们使用完全相同的数字表示和运算。 本章 中关于C的所有内容对C++都有效。 另一方面,Java语言创造了一套新的数字表示和运算标准。 C标准的设计允许多种实现方式, 而Java标准在数据的格式和编码上是非常精确具体的。 本章中多处着重介绍了Java支持的表示和运算。
C编程语言的演变
前面提到过,C编程语言是贝尔实验室的Dennis Ritchie最早开发出来的, 目的是> 和Unix操作系统一起使用(Unix也是贝尔实验室开发的)。 在那个时候, 大多数系统程 序, 例如操作系统,为了访问不同数据类型的低级表示, 都必须大量地使用汇编代码。比如说, 像malloc库函数提供的内存分配功能,用当时的其他高级语言是无法编写的。 Brian Kernighan和Dennis Ritchie的著作的笫1版[60]记录了最初贝尔实验室的C 语言版本。 随着时间的推移, 经过多个标准化组织的努力,C语言也在不断地演变。1989年, 美国国家标准学会下的一个工作组推出了ANSIC标准, 对最初的贝尔实验室的C 语言做了重大修改。 ANSIC与贝尔实验室的C 有了很大的不同, 尤其是函数声明的方式。 Br ian Ker nigh an 和DennisR it chie在著作的第2版[61]中描述了ANSIC, 这本书至今仍被公认为关于C语言最好的参考手册之一。
国际标准化组织接替了对C语言进行标准化的任务, 在1990年推出了一个几乎和 ANSI C 一样的版本, 称为 “ISO C90”。 该组织在1999年又对C语言做了更新, 推出 “ISO C99”。 在这一版本中, 引入了一些新的数据类型, 对使用不符合英语语言字符的文本字符串提供了支持。 更新的版本201 1年得到批准, 称为 “ISO Cll”, 其中再次添加了更多的数据类型和特性。 最近增加的大多数内容都可以向后兼容, 这意味着根据早期标准(至少可以回溯到ISOC90)编写的程序按新标准编译时会有同样的行为。
GNU编译器套装(GNUCom piler Col lection, GCC )可以基于不同的命令行选项, 依照多个不同版本的C语言规则来编译程序prog.c,我们就使用命令行:
linux> gcc -std=c11 prog.c
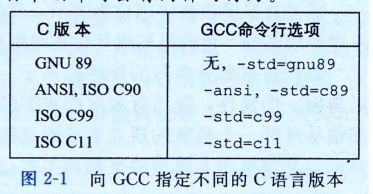
编译选项-ansi和-std=c89的用法是一样的——会`根据ANSI或者ISO C90标准来编译程序。 (C90有时也称为 “C89”, 这是因为它的标准化工作是从1989年 开始的。)编译选项-std=c99会让编译器按照ISOC99 的规则进行编译。
本书中, 没有指定任何编译选项时, 程序会按照基于ISOC90的C语言版本进行编译, 但是也包括一些C99、 Cll 的特性, 一些C++ 的特性, 还有一些是与GCC相关的特性。 GNU项目正在开发一个结合了ISOCll 和其他一些特性的版本, 可以通过命令行选项-std=gnull来指定。 (目前, 这个实现还未完成。)今后, 这个版本会成为默认的版本。
2.1 信息存储
大多数计算机使用8 位的块, 或者宇节(byte), 作为最小的可寻址的内存单位, 而不 是访问内存中单独的位。 机器级程序将内存视为一个非常大的字节数组, 称为虚拟内存 (virtual memo ry)。 内存的每个字节 都由一个唯一的数字来标识, 称为它的地址Caddress), 所有可能地址的集合就称为虚拟地址空间(virtual address spa ce)。 顾名思义, 这 个虚拟地址空间只是一个展现给机器级程序的概念性映像。 实际的实现(见第9章)是将动态随机访问存储器(DRAM)、闪存、 磁盘存储器、 特殊硬件和操作系统软件结合起来, 为 程序提供一个看上去统一的字节数组。
在接下来的几章中, 我们将讲述编译器和运行时系统是如何将存储器空间划分为更可 管理的单元, 来存放不同的程序对象( pro gr am object ), 即程序数据、 指令和控制信息。 可以用各种机制来分配和管理程序不同部分的存储。 这种管理完全是在虚拟地址空间里完 成的。 例如, C语言中一个指针的值(无论它指向一个整数、 一个结构或是某个其他程序 对象)都是某个存储块的第一个字节的虚拟地址。 C编译器还把每个指针和类型信息联系起来, 这样就可以根据指针值的类型, 生成不同的机器级代码来访问存储在指针所指向位置处的值。 尽管C编译器维护着这个类型信息, 但是它生成的实际机器级程序并不包含关于数 据类型的信息。 每个程序对象可以简单地视为一个字节块, 而程序本身就是一个字节序列。
C语言中指针的作用
指针是C语言的一个重要特性。它提供了引用数据结构(包括数组)的元素的机制。与变量类似,> 指针也有两个方面:值和类型。它的值表示某个对象的位置,而它的类型 表示那个位置上所存储对象的类型(比如整数或者浮点数)。
真正理解指针需要查看它们在机器级上的表示以及实现。这将是第3章的重点之 一,3.10. 1节将对其进行深入介绍。
2. 1. 1 十六进制表示法
一个字节由8位组成。在二进制表示法中,它的值域是00000000 2 ~ 111111112。如果看 成十进制整数,它的值域就是010~25510。两种符号表示法对于描述位模式来说都不是非常 方便。二进制表示法太冗长,而十进制表示法与位模式的互相转化很麻烦。替代的方法是, 以16为基数,或者叫做十六进制(hexadecimal)数,来表示位模式。十六进制(简写为 “hex”)使用数字’O’~ '9’以及字符 ‘A’~ 'F’来表示16个可能的值。图2-2展示了16个十 六进制数字对应的十进制值和二进制值。用十六进制书写,一个字节的值域为0016 ~FF16。
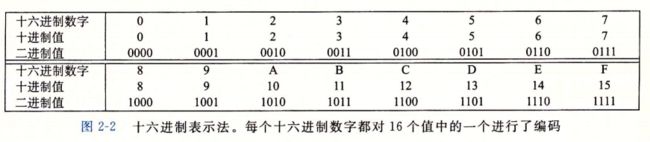
在C语言中,以Ox或 ox 开头的数字常量被认为是十六进制的值。字符’A’~ ‘F’ 既可以是大写,也可以是小写。例如,我们可以将数字FA1D37B1s写作OxFA1D37B, 或者 Oxfald37b, 甚至是大小写混合,比如,OxFa1D37b 。在本书中, 我们将使用C表示法来 表示十六进制值。
编写机器级程序的一个常见任务就是在位模式的十进制、 二进制和十六进制表示之间人工转换。二进制和十六进制之间的转换比较简单直接,因为可以一次执行一个十六进制 数字的转换。数字的转换可以参考如图2-2所示的表。一个简单的窍门是,记住十六进制 数字A 、C和F 相应的十进制值。而对千把十六进制值B、D 和E转换成十进制值,则可以通过计算它们与前三个值的相对关系来完成。
比如,假设给你一个数字 Oxl73A4C。可以通过展开每个十六进制数字,将它转换为 二进制格式,如下所示:

这样就得到了二进制表示000101110011101001001100 。
反过来,如果给定一个二进制数字1111001010110110110011, 可以通过首先把它分为 每4位一组来转换为十六进制。不过要注意,如果位总数不是4的倍数,最左边的一组可以少千4位,前面用0补足。然后将每个4位组转换为相应的十六进制数字:

练习题2.1 完成下面的数字转换 A. 将Ox39A7F8转换为二进制。 B. 将二进制 1100100101111011转换为十六进制。 C. 将OxDSE4C转换为二进制。 D. 将二进制 1001101110011110110101转换为十六进制。 当值x是2的非负整数n次幕时, 也就是x= Z", 我们可以很容易地将x写成十六进制形式, 只要记住x的二进制表示就是1后面跟n个0。十六进制数字 0代表4个二进制 0。 所以, 当n表示成曰一 句的形式, 其中Oi3, 我们可以把x写成开头的十六进制数字为l(i=O)、 2(i= 1)、 4(i =2)或者 8(i= 3), 后面跟随着)个十六进制的0。比如, x= 2048 = 211 , 我们有n= ll =3+4•2, 从而得到十六进制表示 Ox800。
练习题2. 2 填写下表中的空白项, 给出2的不同次幕的二进制和十六进制表示: 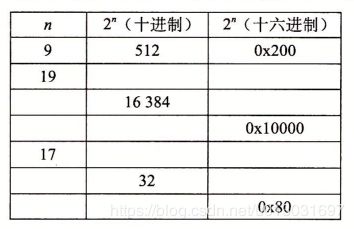 十进制和十六进制表示之间的转换需要使用乘法或者除法来处理一般情况。 将一个十进制数字 x 转换为十六进制 , 可以反复地用16除x, 得到一个商q和一个余数r, 也就是 x=q• 16+r。 然后, 我们用十六进制数字表示的r作为最低位数字, 并且通过对q 反复进行这个过程得到剩下的数字。 例如, 考虑十进制 314 156的转换:
十进制和十六进制表示之间的转换需要使用乘法或者除法来处理一般情况。 将一个十进制数字 x 转换为十六进制 , 可以反复地用16除x, 得到一个商q和一个余数r, 也就是 x=q• 16+r。 然后, 我们用十六进制数字表示的r作为最低位数字, 并且通过对q 反复进行这个过程得到剩下的数字。 例如, 考虑十进制 314 156的转换: 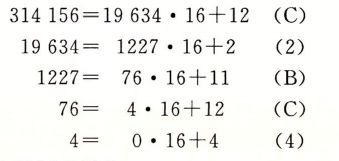 从这里, 我们能读出十六进制表示 为Ox4CB2C。 反过来, 将一个十六进制数字 转换为十进制数字, 我们可以用相应的16的幕乘以每个十六进制数字。 比如, 给定数字 Ox7AF, 我们计算它对应的十进制值为7•162 +10-16+15 = 7• 256+10• 16+15 = 1792+160+15 =1967。
从这里, 我们能读出十六进制表示 为Ox4CB2C。 反过来, 将一个十六进制数字 转换为十进制数字, 我们可以用相应的16的幕乘以每个十六进制数字。 比如, 给定数字 Ox7AF, 我们计算它对应的十进制值为7•162 +10-16+15 = 7• 256+10• 16+15 = 1792+160+15 =1967。
练习题2. 3 一个字节可以用两个十六进制数字来表示。 填写下表中缺失的项, 给出不同字节模式的十进制、 二进制和十六进制值: 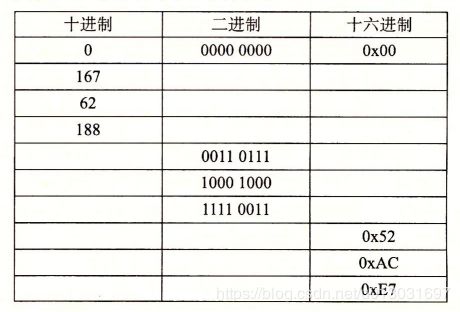
十进制和十六进制间的转换
较大数值的十进制和十六进制之间的转换, 最好是让计算机或者计算器来完成。 有大 量的工具可以完成这个工作。一个简单的方法就是利用任何标准的搜索引擎, 比如查询:
把Oxabcd转换为十进制数
或
把123用十六进制表示。
练习题2. 4 不将数字转换为十进制或者二进制, 试着解答下面的算术题,答案要用 十六进制表示。 提示: 只要将执行十进制加法和减法所使用的方法改成以16为基数。
A. Ox503c+Ox8=
B. Ox503c-Ox40=
C.Ox503c+64=
D.Ox50ea-Ox503c=
2.1.2 字数据大小
每台计算机都有一个字长(word size), 指明指针数据的标称 大小(nominal size)。 因为 虚拟地址是以这样的一个字来编码的, 所以字长决定的最重要的系统参数就是虚拟地址空 间的最大大小。也就是说,对于一个字长为w位的机器而言,虚拟地址的范围为O~2w- 1, 程序最多访问2w个字节。
最近这些年,出现了 大规模的从32位字长机器到64位字长机器的迁移。这种情况首先出 现在为大型科学和数据库应用设计的高端机器上,之后是台式机和笔记本电脑,最近则出现在 智能手机的处理器上。 32位字长限制虚拟地址空间为4千兆字节(写作4GB), 也就是说,刚刚超过4*9沪字节。扩展到64位字长使得虚拟地址空间为16EB, 大约是 1.84* 219。
大多数64位机器也可以运行为32位机器编译的程序, 这是一种向后兼容。 因此, 举例来说, 当程序prog.c用如下伪指令编译后linux> gee -m32 prog.e
该程序就可以在 32位或64位机器上正确运 行。 另一方面,若程序用下述伪指令编译linux> gee -m64 prog.e 那就只能在64位机器上运行。 因此, 我们将程序称为" 32位程序 ” 或"64位程序” 时, 区别在于该程序是如何编译的,而不是其运行的机器类型。计算机和编译器支持 多种不同方式编 码的数字格式,如不同长度的整数和浮点 数。 比如,许多机器都有处理单个字节的 指令,也有处理表示为2字节、 4字节或 者8字节整数的指令, 还有些指令支持表 示为4字节和8字节的浮点数。C语言支持整数和浮点数的 多种数据格式。 图2-3展示了为C语言各种数据类
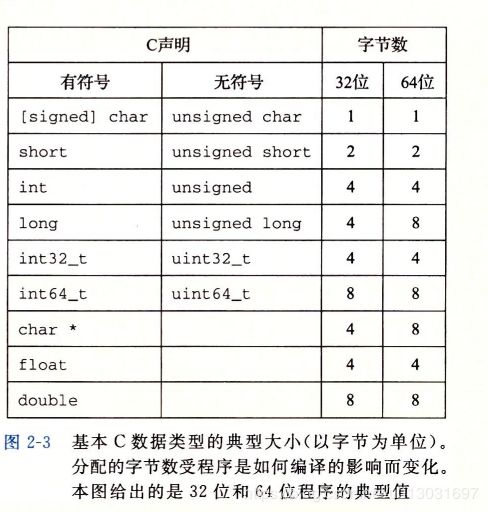
型分配的字节数。(我们在2.2节讨论C标准保证的字节数和典型的字节数之间的关系。)有些数据类型的确切字节数依赖于程序是如何被编译的。我们给出的是 32 位和 64 位程序 的典型值。整数或者为有符号的,即可以表示负数、零和正数;或者为无符号的,即只能表示非负数。C的数据类型char表示一个单独的字节。尽管“char”是由于它被用来存储文本串中的单个字符这一事实而得名,但它也能被用来储存整数值。数据类型short、int 和 long 可以提供各种数据大小。即使是为 64 位系统编译,数据类型 int 通常也只有 4个字节。数据类型long一般在 32 位程序中为 4字节,在 64 位程序中则为 8字节。
为了避免由于依赖典型为了避免由于依赖 大小和不同编译器设置带来的奇怪行为,ISO C99 引入了 一类数据类型,其数据大小是固定的,不随编译器和机器设置而变化。其中就有数据类型 int32 t 和 int64 七,它们分别为 4 个字节和 8 个字节。使用确定大小的整数类型是程序 员准确控制数据表示的最佳途径。
大部分数据类型都编码为有符号数值,除非有前缀关键字 unsigned 或对确定大小的数据类型使用了特定的无符号声明。数据类型 char 是一个例外。尽管大多数编译器和机器将它们视为有符号数,但C标准不保证这一点。相反,正如方括号指示的那样,程序员应该用有符号字符的声明来保证其为一个字节的有符号数值。不过,在很多情况下,程序 行为对数据类型 char 是有符号的还是无符号的并不敏感。
对关键字的顺序以及包括还是省略可选关键字来说,C语言允许存在多种形式。比如,下面所有的声明都是一个意思:

我们将始终使用图 2-3 给出的格式。
图 2-3 还展示了指针(例如一个被声明为类型为 "char * "的变量)使用程序的全字长。大多数机器还支持两种不同的浮点数格式:单精度(在 C中声明为 float) 和双精度(在 C中声明为 double)。这些格式分别使用 4 字节和 8字节。
声明指针 对于任何数据类型T,声明
T *p;表明p是一个指针变量,指向一个类型为T的对象。例如,char *p;
就将一个指针声明为指向一个char类型的对象。
程序员应该力图使他们的程序在不同的机器和编译器上可移植。可移植性的一个方面就是使程序对不同数据类型的确切大小不敏感。C语言标准对不同数据类型的数字范围设置了下界(这点在后面还将讲到),但是却没有上界。因为从1980 年左右到2010 年左右,32 位机器和 32 位程序是主流的组合,许多程序的编写都假设为图 2-3 中 32 位程序的字节分配。随着 64 位机器的日益普及,在将这些程序移植到新机器上时,许多隐藏的对字长的依赖性就会显现出来,成为错误。比如,许多程序员假设一个声明为 int类型的程序对象能被用来存储一个指针。这在大多数 32 位的机器上能正常工作,但是在一台 64 位的机器上却会导致问题。
2.1.3 寻址和字节顺序
于跨越多字节的程序对象, 我们必须建立两个规则: 这个对象的地址是什么, 以及在内存中如何排列这些字节。 在几乎所的机器上, 多字节对象都被存储为连续的字节序 列,对象的地址为所使用字节中最小的地址。 例如, 假设一个类型为int的变量x的地址 为 OxlOO, 也就是说, 地址表达式 &x 的值为 OxlOO。 那么, (假设数据类型 1让为 32 位表 示)x 的 4 个字节将被存储在内存的 OxlOO、 OxlOl、 Oxl02和Oxl03 位置。
排列表示一个对象的字节有两个通用的规则。 考虑一个w位的整数, 其位表示为[Xw-1,Xw-2,…, X1, X0], 其中 Xw 1是最高有效位, 而x。是最低有效位。 假设w是8的倍数, 这些位就能被分组成为字节, 其中最高有效字节包含位[x心气, Xw-2• …,立-sJ, 而最低有效 字节包含位[x1’ X5’ …, x。 J’ 其他字节包含中间的位。 某些机器选择在内存中按照从最低 有效字节到最高有效字节的顺序存储对象,而另一些机器则按照从最高有效字节到最低有效 字节的顺序存储。 前一种规则——最低有效字节在最前面的方式, 称为小端法(little endian)。后一种规则—-—最高有效字节在最前面的方式, 称为大端法(big endian)。
假设变量 x 的类型为m七, 位于地址 Ox100 处, 它的十六进制值为 Ox01234567。地 址范围 OxlOO~ Ox103 的字节顺序依赖千机器的类型:

注意, 在字 Ox01234567 中, 高位字节的十六进制值为 OxOl, 而低位字节值为 Ox67。
大多数Intel兼容机都只用小端模式。 另 一方面, IBM和Oracle(从其 2010 年收购Sun Microsystems开始)的大多数机器则是按大端模式操作。 注意我们说的是 “大多数”。 这些规则并没有严格按照企业界限来划分。 比如, IBM和Oracle制造的个人计算机使用 的是Intel兼容的处理器, 因此使用小端法。 许多比较新的微处理器是双端法(bi-endian), 也就是说可以把它们配置成作为大端或者小端的机器运行。 然而, 实际情况是: 一旦选择了特定操作系统,那么字节顺序也就固定下来。 比如, 用于许多移动电话的ARM 微处理 器, 其硬件可以按小端或大端两种模式操作, 但是这些芯片上最常见的两种操作系统一—
Android(来自Google)和IOSC来自Apple)-却只能运行于小端模式。
令人吃惊的是, 在哪种字节顺序是合适的这个问题上, 人们表现得非常情绪化。 实际上, 术语 "little endian(小端)” 和 "big endian(大端)” 出自Jonathan Swift 的《格利佛游记》(Gulliver’s Travels)一书, 其中交战的两个派别无法就应该从哪一端(小端还是大端)打开一个半熟的鸡蛋达成一致。 就像鸡蛋的问题一样, 选择何种字节顺序没有技术上的理 由, 因此争论沦为关于社会政治论题的争论。 只要选择了一种规则并且始终如一地坚持,对千哪种字节排序的选择都是任意的。
“端的起源” 以下是Jonathan Swift在 1726 年关于大小端之争历史的描述: "……我下面要告诉你的是, Lilliput 和
Blefuscu 这两大强国在过去 36 个月里一直 在苦战。 战争开始是由于以下的原因:我们大家都认为, 吃鸡蛋前,
原始的方法是打破鸡蛋较大的一端,可是当今皇帝的祖父小时候吃鸡蛋, 一次按古法打鸡蛋时碰巧将一个 手指弄破了, 因此他的父亲, 当时的皇帝,
就下了一道敕令, 命令全体臣民吃鸡蛋时打破鸡蛋较小的一端, 违令者重罚。 老百姓们对这项命令极为反感。 历史告诉我们,
由此曾发生过六次叛乱, 其中一个皇帝送了命, 另一个丢了王位。 这些叛乱大多都是由 Blefuscu 的国王大臣们煽动起来的。
叛乱平息后, 流亡的人总是逃到那个帝国去寻救避难。 据估计, 先后几次有 11 000 人情愿受死也不肯去打破鸡蛋较小的一端。
关于这一争端,曾出版过几百本大部著作, 不过大端派的书一直是受禁的,
法律也规定该派的任何人不得做官。”(此段译文摘自网上蒋剑锋译的《格利佛游记》第一卷第4章。) 在他那个时代, Swift
是在讽刺英国(Lilliput) 和法国 (Blefuscu) 之间持续的冲突。 Danny Cohen, 一位网络协议的早期开创者,
第一次使用这两个术语来指代字节顺序 [24], 后来这个术语被广泛接纳了。
对于大多数应用程序员来说, 其机器所使用的字节顺序是完全不可见的。 无论为哪种类型的机器所编译的程序都会得到同样的结果。 不过有时候, 字节顺序会成为问题。 首先 是在不同类型的机器之间通过网络传送二进制数据时, 一个常见的问题是当小端法机器产 生的数据被发送到大端法机器或者反过来时, 接收程序会发现, 字里的字节成了反序的。为了避免这类问题, 网络应用程序的代码编写必须遵守已建立的关千字节顺序的规则, 以 确保发送方机器将它的内部表示转换成网络标准, 而接收方机器则将网络标准转换为它的 内部表示。 我们将在第11章中看到这种转换的例子。
第二种情况是, 当阅读表示整数数据的字节序列时字节顺序也很重要。 这通常发生在 检查机器级程序时。 作为一个示例, 从某个文件中摘出了下面这行代码, 该文件给出了一 个针对 Intel x86-64 处理器的机器级代码的文本表示:
4004d3: 01 05 43 Ob 20 00 add %eax,Ox200b43(%rip)
这一行是由反汇编器(disassembler) 生成的, 反汇编器是一种确定可执行程序文件所表示 的指令序列的工具。 我们将在第3章中学习有关这些工具的更多知识, 以及怎样解释像这 样的行。 而现在, 我们只是注意这行表述的意思是:十六进制字节串 01 05 43 Ob 20 00 是 一条指令的字节级表示, 这条指令是把一个字长的数据加到一个值上, 该值的存储地址由 Ox200b43 加上当前程序计数器的值得到, 当前程序计数器的值即为下一条将要执行指令 的地址。 如果取出这个序列的最后 4 个字节:43 Ob 20 00, 并且按照相反的顺序写出, 我 们得到 00 20 Ob 43。 去掉开头的o, 得到值 Ox200b43, 这就是右边的数值。 当阅读像此 类小端法机器生成的机器级程序表示时, 经常会将字节按照相反的顺序显示。 书写字节序 列的自然方式是最低位字节在左边, 而最高位字节在右边, 这正好和通常书写数字时最高 有效位在左边, 最低有效位在右边的方式相反。
字节顺序变得重要的第三种情况是当编写规避正常的类型系统的程序时。 在C语言 中, 可以通过使用强制类型转换(cast) 或联合(union)来允许以一种数据类型引用一个对 象, 而这种数据类型与创建这个对象时定义的数据类型不同。 大多数应用编程都强烈不推荐这种编码技巧, 但是它们对系统级编程来说是非常有用, 甚至是必需的。
图2-4展示了一段 C 代码, 它使用强制类型转换来访问和打印不同程序对象的字节表示。 我们用 typedef 将数据类型 byte_pointer 定义为一个指向类型为“unsigned char“的对象的指针。 这样 个字节指针引用 个字节序列, 其中每个字节都被认为是一个非负整数。 第 个例程show_bytes的输入是 个字节序列的地址, 它用 个字节指针以及一个字节数来指示。 该字节数指定为数据类型size_t, 表示数据结构大小的首选数据类型。 show—by七es打印出每个以十六进制表示的字节。 C格式化指令 “%.2x” 表明整数必须用至少两个数字的十六进制格式输出。

过程show_int、 show_float和show_poin七er展示了如何使用程序show_by七es来分别输出类型为 int、 flo扛和void* 的C程序对象的字节表示。 可以观察到它们仅仅传递给show_bytes一个指向它们参数x的指针&x, 且这个指针被强制类型转换为"unsigned ch ar * "。 这种强制类型转换告诉编译器, 程序应该把这个指针看成指向一个字节序列,而不是指向一个原始数据类型的对象。然后,这个指针会被看成是对象使用的最低字节地址。
这些过程使用C语言的运算符sizeof来确定对象使用的字节数。一般来说,表达式sizeof (T)返回存储一个类型为T的对象所需要的字节数。 使用sizeof而不是一个固定的值, 是向编写在不同机器类型上可移植的代码迈进了 步。
在几种不同的机器上运行如图2-5所示的代码, 得到如图2-6所示的结果。 我们使用了以下几种机器:
Linux 32: 运行Linux的IntelIA32处理器。
Windows: 运行Windows的IntelIA32处理器。
Sun: 运行Solaris的SunMicrosystems SP ARC处理器。(这些机器现在由Oracle生产。) Linux 64: 运行Linux的Intelx86-64处理器。
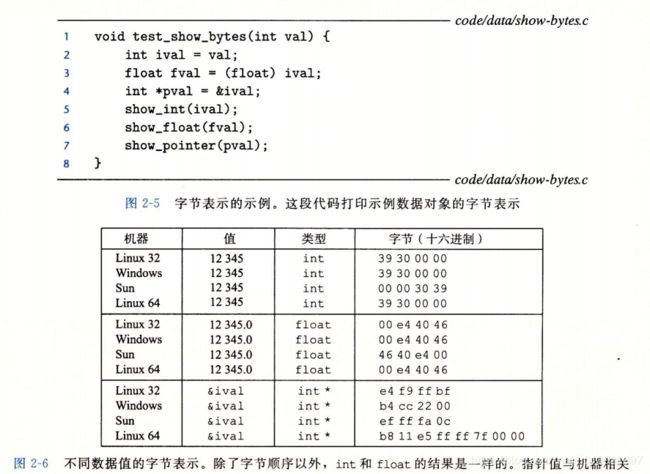
参数12345的十六进制表示为Ox00003039。对千1让类型的数据,除了字节顺序以 外,我们在所有机器上都得到相同的结果。特别地,我们可以看到在Linux32、Windows 和Linux64上,最低有效字节值Ox39最先输出,这说明它们是小端法机器;而在Sun上最后输出,这说明Sun是大端法机器。同样地,float数据的字节,除了字节顺序以外, 也都是相同的。另一方面,指针值却是完全不同的。不同的机器/操作系统配置使用不同 的存储分配规则。一个值得注意的特性是Linux32、Windows和Sun的机器使用4字节 地址,而Linux64使用8字节地址。
使用 typedef 来命名数据类型
C 语言中的typedef声明提供了一种给数据类型命名的方式。这能够极大地改善代码的可读性,因为深度嵌套的类型声明很难读懂。
typedef的语法与声明变量的语法十分相像,除了它使用的是类型名,而不是变量 名。因此,图 2-4 中 byte_pointer 的声明和将一个变量声明为类型 "unsigned char * "有相同的形式。
例如,声明:
typedef int •int_pointer;
int_pointer ip;
将类型 “int主ointer” 定义为一个指向 int的指针,并且声明了一个这种类型的 变量 ip。我们还可以将这个变量直接声明为:int ip;
使用printf格式化输出
printf函数(还有它的同类fprintf和s printf)提供了一种打印信息的方式,这 种方式对格式化细节有相当大的控制能力。笫一个参数是格式串 (format string), 而其余的参数都是要打印的值。在格式串里,每个以"%"开始的字符序列都表示如何格式 化下一个参数。典型的示例包括:’%d’是输出一个十进制整数,’%f’是扴出一个浮点 数,而 ` %已是扴出一个宇符,其编码由参数给出。
指定确定大小数据类型的格式,如int 32_t, 要更复杂一些,相关内容参见2.2. 3 节的旁注。
可以观察到,尽管浮点型和整型数据都是对数值12345编码,但是它们有截然不同的 字节模式:整型为Ox00003039, 而浮点数为Ox4640E400。一般而言,这两种格式使用不 同的编码方法。如果我们将这些十六进制模式扩展为二进制形式,并且适当地将它们移位,就会发现一个有13个相匹配的位的序列,用一串星号标识出来:
这并不是巧合。当我们研究浮点数格式时,还将再回到这个例子。
指针和数组
在函数showbytes( 图2-4)中,我们看到指针和数组之间紧密的联系,这将在3.8节中详细描述。这个函数有一个类型为byte _pointer(被定义为一个指向unsignedchar 的指针 )的参数start,但是我们在第8行上看到数组引用start[i)。在 C 语言中,我们能够用数组表示法来引用指针,同时我们也能用指针表示法来引用数组元素。在这个例子 中·, 引用start[i)表示我们想要读取以start 指向的位置为起始的第i个位置处的字节。
指针的创建严间接引用
在图2-4的第13、17和21行,我们看到对 C和 C++中两种独有操作的使用。C的 ”取地址” 运算符&创建一个指针。在这三行中,表达式&x创建了一个指向保存变量x的 位置的指针。这个指针的类型取决于x的类型,因此这三个指针的类型分别为int入 float 和void。(数据类型void*是一种特殊类型的指针,没有相关联的类型信息。)
强制类型转换运算符可以将一种数据类型转换为另一种。因此,强制类型转换(byte_pointer )&x表明无论指针&x以前是什么类型,它现在就是一个指向数据类型为unsignedchar 的指针。这里给出的这些强制类型转换不会改变真实的指针,它们 只是告诉编译器以新的数据类型来看待被指向的数据。
生成一 张ASCII表
可以通过执行命令man ascii来得到一张 ASCII 宇符码的表。

练习题2. 5 思考下面对show_bytes的三次调用:
int val= Ox87654321;
byte_pointer valp = (byte_pointer) &val;
show_bytes(valp, 1); I* A. I
show_bytes(valp, 2); I B. I
show_bytes(valp, 3); I C. *I
指出在小端法机器和大端法机器上, 每次调用的输出值 。
A. 小端法: 大端法:B. 小端法: 大端法:C. 小端法: 大端法:
练习题2.6 使用show_int和show_float, 我们确定整数3510593的十六进制表示为Ox00359141, 而浮点数 3510593. 0的十六进制表示为Ox4A564504。
A. 写出这两个十六进制值的二进制表示。
B. 移动这两个二进制串的相对位置, 使得它们相匹配的位数最多。 有多少位相匹配呢?
C. 串中的什么部分不相匹配?
2.1.4 表示字符串
C 语言中字符串被编码为一个以null(其值为0)字符结尾的字符数组。 每个字符都由某个标准编码来表示, 最常见的是ASCII 字符码。 因此, 如果我们以参数 “12345” 和6 (包括终止符)来运行例程show_bytes, 我们得到结果 31 32 33 34 35 00。 请注意, 十进 制数字x 的ASCII 码正好是Ox3x, 而终止字节的十六进制表示为OxOO。 在使用 ASCII 码作为字符码的任何系统上都将得到相同的结果, 与字节顺序和字大小规则无关。 因而, 文本数据比二进制数据具有更强的平台独立性。
练习题2. 7 下面对show—bytes的调用将输出什么结果?
const char *S = “abcdef”;
show_bytes((byte_pointer) s, strlen(s));
注意字母 ‘a’ ~‘z’ 的 ASCII 码为Ox6l~Ox7A。
文字编码的Unicode标准
ASCII宇符集适合于编码英语文档, 但是在表达一些特殊宇符方面并没有太多办法,例如法语的“C”,它完全不适合编码希腊语、 俄语和中文等语言的文档。 这些年, 提出了很多方法来对不同语言的文字进行编码Unicode联合会(UnicodeConsortium)修订了最全 。面且广泛接受的文字编码标准。 当前的Unicode标准(7.0版)的字库包括将近100 000 个字 符, 支持广泛的语言种类, 包括古埃及和巴比伦的语言。 为了保持信用, Unicode技术委员会否决了为Klingon(即电视连续剧《星际迷航》中的虚构文明)编写语言标准的提议。
基本编码, 称为Unicode的 “统一字符集“,使用32位来表示宇符。 这好像要求文 本串中每个字符要占用4个宇节 不过, 可以有一些替代编码, 常见的宇符只需要1个或2个字节, 而不太常用的字符需要多一些的字节数。 特别地, UTF-8 表示将每个字符 编码为一个字节序列, 这样标准 ASCII 字符还是使用和它们在 ASCII 中一样的单宇节 编码, 这也就意味着所有的 ASCII 字节序列用 ASCII 码表示和用UTF-8 表示是一样的。Java编程语言使用Unicode来表示字符串。 对于C语言也有支持Unicode的程序库。