JVM虚拟机实现机制
1.问题
1、JAVA文本文件如何被翻译成CLASS二进制文件?
2、如何理解CLASS文件的组成结构?
3、虚拟机如何加载使用类文件的生命周期?
4、虚拟机系列诊断工具如何使用?
5、虚拟机内存淘汰机制?
6、虚拟机指令集架构?
2.关键词
编译,魔数,常量池,字面量,数据表,堆栈,方法区,程序计数器,内存引用,内存溢出,垃圾回收器,新生区,永久区,指令集
3.全文概要
上一篇我们介绍了代码如何被翻译成机器级程序,然后逐条送到CPU执行。但是现代硬件的指令集架构千差万别,不同机器上运行相同代码往往会出现指令集兼容问题。虚拟机在这个层面上把各种细节封装好,提供通用的接口供上层应用调用。封装好指令集架构的同时提供各种内存淘汰机制。本文将从宏观及微观角度来介绍类文件结构、虚拟机加载类文件机制,类文件生命周期及字节码加载引擎,更加立体的加深对虚拟机工作的认识。
4.CLASS文件结构分析
从我们学习JAVA语言的第一天起,就执行过JAVA/JAVAC命令。JAVAC就是把我们写好的后缀为.java的文本文件编译成后缀为.class的字节码文件。上一章我们介绍代码本质的时候就了解到JAVA语言的语法元素。java文件我们可以通过文本编辑器打开,里面也是我们熟悉的java代码,符合了java语言的语法规范。但是对于class里面的内容,我们要陌生很多。上一章我们知道代码通过编译器翻译成机器指令,那class文件会不会也是java虚拟机翻译成的指令呢?
其实当java文件被编译成class文件后,就跟java语言没什么关系了。指令执行引擎是JVM虚拟机,其他编程语言,比如Scala,Python等都可以编译成class文件,然后放到JVM来执行。这么说来,我们更加有必要探究class文件的本质了。
4.1 CLASS文件示例
我们先从微观的角度来介绍class文件的结构。先写一个简单的java文本文件,然后编译成class文件,来观察class的结构组成。
先定义一个接口文件,Add.java文件如下:
package com.lzh.jvm;
public interface Add{
int add(int i,int j);
}再写一个接口的实现类AddImpl.java,这个基本包含我们日常经常使用的文件结构:
package com.lzh.jvm;
public class AddImpl implements Add{
public static final int TOP = 100;
private String point;
public int add(int i,int j){
return i + j;
}
}由于存在包名定义我们需要建好com/lzh/jvm的文件目录,然后在当前目录先后编译com/lzh/jvm/Add.java文件和com/lzh/jvm/AddImpl.java文件。得到了Add.class文件和AddImpl.class文件。
Add.java二进制文件:

Add.class二进制文件:

AddImpl.java二进制文件:

AddImpl.class二进制文件:
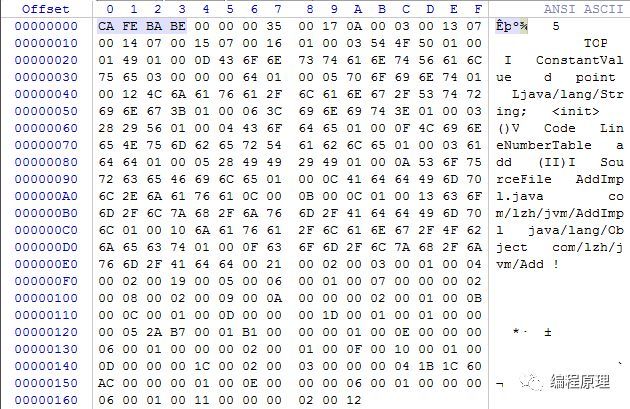
以上四个图是用WinHex二进制编辑工具打开的,左边是文件的二进制编码,右边是ASCII标准编码,所以只能表示英式键盘上的字符,出现中文的话则显示乱码。为了阅读方便,工具展示的是16进制的格式,两个16进制的编码表示一个字节空间(8位)。直观上我们可以看出来java文件占用的存储空间比class要少很多,这也符合我们上一章介绍的代码翻译过程。本质上计算机并不认识java文件里面的内容,java属于高级语言,里面的语法更为接近人类的语言,但是对于计算机来说全难以理解。所以需要把java文件的内容翻译成jvm认识的文件格式。高级语言高度抽象了语言元素,翻译为机器指令则要花费更多的“口舌”来指导计算机一步步执行代码语句。下一节我们来解释class文件的结构,从而理解jvm如何理解执行class的内容。
4.2 class文件结构说明
本节我们将以上图给的AddImpl.class为例子来介绍类的结构。从结构上来看,class文件只存放两种类型数据,分别为基础字段和表。
基础字段:用于描述数字,引用,数值或字符串的无符号数,类型为u1,u2,u4,u8表示占用字节数
表:只有一行的可变列数的表结构,每个字段可以是基础字段或其他表的索引
4.2.1 魔数
用于判断文件类型,通常我们以文件后缀来判别文件类型,但是如果修改后缀就会导致安全问题。class以4个字节的空间作为开端,来标明class的类型,CA FE BA BE表示class类型的文件。
4.2.2 版本数
魔数后面紧接着4个字节表示jdk版本号。
次版本号:前两个字段0x0000
主版本号:后两个字段0x0035,转换十进制为53,对应jdk1.9
4.2.3 常量池
常量池顾名思义是用于存放字符串常量,字符串常量包含:
字面量:字符串,常量
引用符合:类/接口全限定名,字段/方法名称和修饰符
我们知道class本质是一些表的集合,同样常量池也不例外,只不过存放在常量池位置的表有特定的类型,共有11种类型,如下表(图片引用《深入理解Java虚拟机 JVM高级特性与最佳实践 》):
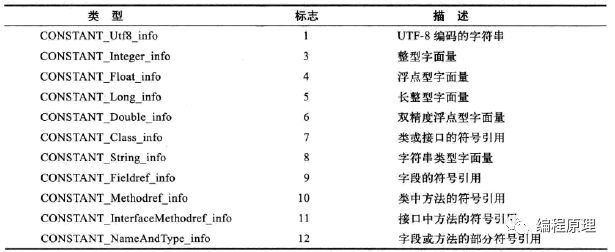
每个表的表结构说明如下:


这11种类型的表第一个字段统一为标志字段tag,占用u1一个字节,用于表示该表存放的数据类型。
首先进入常量池开始的两个字节(u2)表示的是常量池的长度,也就是表的个数。
我们可以看到例子中常量池个数为0x0017,转换为十进制为23,由于第0个表为保留索引,表示没引用到任何字符串,所以实际表的索引是从1开始计算,也就是1~23共22个表。
我们先观察AddImpl.class常量池,分析第1张表的表结构。查表可知紧接着表个数后面的u1位置为0A,转换为十进制为10,该表类型为CONSTANT_Methodref_info,观察表结构可知接下来的两个u2位置属于该表的字段,这两个字段都是表索引类型,0x0003表示引用第3个表,0x0013表示引用第19个表。
然后该表结束紧接着是第2张表第一个表,该表tag为07是CONSTANT_Class_info类型,第二个空间为u2的字段值为0x0014,引用第20个表。
接着分析第3张表,根据同样的方法,一直可以把常量池的表结构分析完。常量池的作用就是把源代码所有文本数据都集中在常量池这个区间位置内,里面各个表之间相互引用,统一管理文本数据。由于表之间的引用,最后文本数据都是存放在CONSTANT_Class_info表里面,而该表规定文本长度的字段length空间是u2类型,占用2个字节,空间2的16次方,65536/1024=64K,所以java的变量或方法名大小不能超过64K。
4.2.4 访问标志
修饰类或接口的限定标志
在常量池结束后紧接着2个字节的访问标志,共32个标志位。
4.2.5 类/父类/接口索引集合
类索引、父类索引与接口索引集合:指向常量池的CONSTANT_Class_info表,再由CONSTANT_Class_info表里面的index指向特定CONSTANT_Utf8_info表的bytes字段的字面量。
4.5.6 字段表集合
字段表集合:
字段表结构如下
数组用 [ 表示,字段表用来表示类里面所有变量(不包括方法里面的局部变量)
4.5.7 方法表集合
方法表集合:
方法表结构如下
4.5.8 属性表集合
属性表集合
方法体里面的内容编译为Code属性,code表结构如下
Code,Exceptions,LineNumberTable,LocalVariableTable,SourceFile,ConstantValue,InnerClasses,Deprecated,Synthetic
class文件就像是一个产品的模具,把模具制造出来的过程就是把class加载到jvm内存的过程,然后jvm再照着class模具的样子印出对象来。重点在于模具的设计,其实模具被生产出来也是需要它本身有一套模具。这就是class严格的结构规范,class文件结构规范给出了各个方面的要求,只有按照这个要求造出来的模具才是可用的,才可以被用来制造产品,不然连产品线都上不去,就如同jvm判断class不符合规范而拒绝加载。
5.类文件生命周期
类加载时机
类初始化的时机,大部分为被动初始化,用不到的时候都不会初始化。
类加载过程
加载:全限定名检索二进制字节流(不止class文件)->读取至方法区->在堆上生成class对应的对象
验证:文件格式验证(符合class文件规范)->元数据验证(语义分析)->字节码验证(方法体校验)->符号引用验证。可以用-Xverify:none来跳过类加载验证
准备:类变量分配内存设置初值,并未进行赋值操作
解析:针对类接口,字段,方法的符合引用进行解析匹配。类解析,接口解析,字段解析,类方法解析,接口方法解析,
初始化:执行类构造器
()方法,按源码顺序执行所有static的语句。没有静态变量或者static语句的类将不会有()。
类加载器
启动类加载器,扩展类加载器,应用程序类加载器
类加载器采用双亲委派机制来读取类文件,破坏双亲委派模型如:OSGI服务由自定义类加载器机制实现。每个OSGI模块(Bundle)都有自己的加载器
6.虚拟机诊断工具
虚拟机性能监控与故障处理工具,给一个系统定位问题的时候,知识,经验是基础,数据是依据,工具就是处理数据的手段。
JDK的命令行工具
虚拟机进程状况工具:jps -lvm
虚拟机统计信息监视工具:jstat -gc pid interval count
java配置信息工具:jinfo -flag pid
java内存映像工具:jmap -dump:format=b,file=java.bin pid
生成堆转储文件虚拟机堆转储快照分析工具:jhat file 分析堆转储文件,通过浏览器访问分析文件
java堆栈跟踪工具:jstack [ option ] vmid
用于生成虚拟机当前时刻的线程快照threaddump或者Javacore
JDK的可视化工具
jconsole
jvisualvm
7.虚拟机内存淘汰机制
本节从宏观的角度讲解JVM内存结构、内存分配运行策略,垃圾回收机制。
7.1虚拟机内存分布
java内存区域与内存溢出
jvm内存区域:方法区,虚拟机栈,本地方法栈,堆,程序计数器;
程序计数器:字节码行号指示器,每个线程需要一个程序计数器
虚拟机栈:方法执行时创建栈帧(存储局部变量,操作栈,动态链接,方法出口)编译时期就能确定占用空间大小,线程请求的栈深度超过jvm运行深度时抛StackOverflowError,当jvm栈无法申请到空闲内存时抛OutOfMemoryError,通过-Xss,-Xsx来配置初始内存
本地方法栈:执行本地方法,如操作系统api接口
堆:存放对象的空间,通过-Xmx,-Xms配置堆大小,当堆无法申请到内存时抛OutOfMemoryError
方法区:存储类数据,常量,常量池,静态变量,通过MaxPermSize参数配置
对象访问:初始化一个对象,其引用存放于栈帧,对象存放于堆内存,对象包含属性信息和该对象父类、接口等类型数据(该类型数据存储在方法区空间,对象拥有类型数据的地址)
7.2内存回收算法
内存回收概述:
虚拟机栈、本地栈和程序计数器在编译完毕后已经可以确定所需内存空间,程序执行完毕后也会自动释放所有内存空间,所以不需要进行动态回收优化。
jvm内存调优主要针对堆和方法区两大区域的内存。
引用:强Strong,软sfot,弱weak,虚phantom,强引用不会回收,软引用在内存达到溢出边界时回收,弱引用在每次回收周期时回收,虚引用专门被标记为回收对象。
内存分配与回收策略
对象优先在Eden区分配:
新生对象回收策略Minor GC(频繁)
老年代对象回收策略Full GC/Major GC(慢)
大对象直接进入老年代:
超过3m的对象直接进入老年区 -XX:PretenureSizeThreshold=3145728(3M)长期存货对象进入老年区:
Survivor区中的对象经历一次Minor GC年龄增加一岁,超过15岁进入老年区
-XX:MaxTenuringThreshold=15动态对象年龄判定:设置Survivor区对象占用一半空间以上的对象进入老年区
垃圾收集算法
标记-清除、复制、标记-整理、分代收集(新生用复制,老年用标记-整理)
8.3内存收集器
serial收集器:单线程,主要用于client模式
ParNew收集器:多线程版的serial,主要用于server模式
Parallel Scavenge收集器:线程可控吞吐量(用户代码时间/用户代码时间+垃圾收集时间),自动调节吞吐量,用户新生代内存区
Serial Old收集器:老年版本serial
Parallel Old收集器:老年版本Parallel Scavenge
CMS(Concurrent Mark Sweep)收集器:停顿时间短,并发收集
G1收集器:分块标记整理,不产生碎片
8.虚拟机指令集架构(执行引擎)
8.1虚拟机字节码执行引擎
运行时栈帧结构
每个方法调用开始到执行完成的过程,对应这一个栈帧在虚拟机栈里面从入栈到出栈的过程。
栈帧包含:局部变量表,操作数栈,动态连接,方法返回
方法调用
方法调用不等于方法执行,而且确定调用方法的版本。方法调用字节码指令:invokestatic,invokespecial,invokevirtual,invokeinterface
静态分派:静态类型,实际类型,编译器重载时通过参数的静态类型来确定方法的版本。(选方法)
动态分派:invokevirtual指令把类方法符号引用解析到不同直接引用上,来确定栈顶的实际对象(选对象)
单分派:静态多分派,相同指令有多个方法版本。
多分派:动态单分派,方法接受者只能确定唯一一个。
基于栈的字节码解释
解释执行:
基于栈指令集与基于寄存器的指令集:
基于本地解释器执行过程
类加载 执行子系统案例
tomcat类加载,OSGI热插拔,字节码生成技术,动态代理,Retrotranslator
9.虚拟机实现机制进化过程
程序编译与代码优化
早期编译(编译期)
javac编译器:解析与符号表填充,注解处理,生成字节码
java语法糖:语法糖有助于代码开发,但是编译后就会解开糖衣,还原到基础语法的class二进制文件
重载要求方法具备不同的特征签名(不包括返回值),但是class文件中,只要描述不是完全一致的方法就可以共存,如:
public String foo(List arg){
final int var = 0;
return "";
}
public int foo(List arg){
int var = 0;
return 0;
} 晚期编译(运行期)
HotSpot虚拟机内的即时编译
解析模式 -Xint
编译模式 -Xcomp
混合模式 Mixed mode
分层编译:解释执行 -> C1(Client Compiler)编译 -> C2编译(Server Compiler)
触发条件:基于采样的热点探测,基于计数器的热点探测
10.总结
由于JVM涉及内容较深且广,篇幅有限无法深入分析细节。本文从微观方面分析了作为原材料的CLASS文件的结构,又从宏观方面阐述了JVM是如何消化每一个进入的CLASS。JVM自定义了一套逻辑上的指令集,这也呼应了之前我们介绍的计算机如何运行一文,现代计算机性能有了长足的发展,但是本质上还是完备的诺依曼体系架构。随着量子计算的突飞猛进,相信未来的计算模型也会有革命性的突破。