课程笔记:Parallel Programming in Java(第二周)
Parallel Programming in Java(第二周)
Parallel Programming in Java 是 Coursera 的上的一门课程,一共有四周课程内容,讲述Java中的并行程序设计。这里是第二周课程的内容笔记。主要内容为 Functional Parallelism,即 函数式并行
Functional Parallelism
Functional parallelism 理解的重点在于 Future Tasks 和 Future objects(或称 promise objects)。
- Future tasks:一个包含返回值的计算任务,其他任务可以通过调用来要求计算或者直接访问(当这个返回值已经计算时)这个返回值
- Future objects:指为future tasks提供访问方式的对象
future task可以理解为是一种描述计算图的方式,通过 future 表示当前任务计算完成之后的结果,供后面的步骤调用,因此在建模时就能够很自然的描述出全部计算图的依赖关系,在依据函数相互的调用关系就能完成并行建模。在 future 模型中有两个关键的问题:
- Assignment:即对于一个 future task,他接受一个输入并产生唯一的输出,两者在计算开始之后都不能修改
- Blocking read:为了使得 future 模型体现依赖关系,在前一个步骤没有进行完毕的时候要对当前模型进行阻塞,等待前序步骤完成之后再继续执行,这能够避免数据竞争的问题。
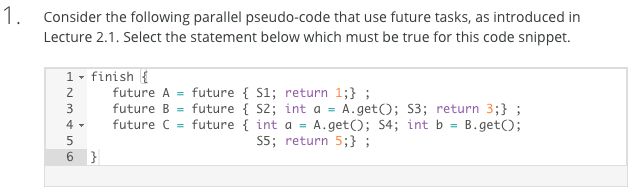
上图是来自课程Quiz的一道题目,更好地展示 future 的分析作用,其中可以看出
- S2 对 S1 没有依赖关系
- S3 需要在 S1 执行完后执行
- S4 不依赖 B 中的任务,但要等到 S1 执行完毕
- S2 需要等到 S1-S3 都执行完毕才能执行
- future 内部要保持顺序执行关系
通过以上分析,我认为从 future 块到计算图的还原最好采用逆向分析的方式,即应用递归程序的思想(实际上框架似乎也是这么分析的)
使用 Fork/Join 框架进行编程
框架的使用方法和之前的方式较为类似,关键点还是在于实现 compute() 函数进行计算,并使用 join() 函数完成阻塞操作,主要有以下需要特别注意的点:
- future task 需要继承 RecursiveTask 类而不是 RecursiveAction 类
- 使用方法与之前类似,但是
compute()函数是有返回值的,不能是void类型 - join 会发生阻塞并等待同步,同时会提供返回值
Memoization
相当于给计算结果建立 Cache,例如:对于 y 1 = G ( x 1 ) y_{1}=G(x_{1}) y1=G(x1) ,当计算完毕之后,不仅仅赋值给 y 1 y_{1} y1 。会同时记录下这个结果来自于 f u t u r e { G , x } future\{G,x\} future{G,x} ,因此在下次调用这个结果时,就可以通过直接查表获取到结果从而避免计算。
Memoization 是动态规划算法的设计来源,即通过使用存储来换取运算时间上的优化。
因为依旧是使用 future 模型进行建模,因此这里还是要求实现一个 get() 操作来获取计算出来的结果的值。
Java Streams
这是 Java 8 中加入的新特性,主要针对一个 for 循环,可以通过调用 parallel stream 实现并行化得循环计算。
students.stream().forEach(s \rightarrow→ System.out.println(s));
students.stream()
.filter(s -> s.getStatus() == Student.ACTIVE)
.mapToInt(a -> a.getAge())
.average();
计算得关键点有两个,即 filter 用来过滤集合中符合条件得元素,map 用来调用集合中每个元素的计算值。使用 stream 的的方式就可以方便的建立并行化的计算了
tudents.parallelStream()
// or
Stream.of(students).parallel()
Determinism
functional determinism:指函数在相同的输入下会有相同输出的性质
structural determinism:指程序中对于相同的输入会产生相同计算图的性质
程序中的不确定的性通常是由于数据竞争导致的
data race freedom = functional determinism + structural determinism
-
有数据竞争出现的程序并不一定是非确定的程序
-
没有数据竞争也不一定能保证确定性
-
使用课程中介绍的模型,在不发生数据竞争的前提下就可以保证是确定性程序
benign non-determinism:指程序中虽然不能保证确定性,但是非确定的结果对于程序的正确性来说是可以接受的
使用 Stream 实例
simple example
/**
* Sequentially computes the number of students who have failed the course
* who are also older than 20 years old. A failing grade is anything below a
* 65. A student has only failed the course if they have a failing grade and
* they are not currently active.
*
* @param studentArray Student data for the class.
* @return Number of failed grades from students older than 20 years old.
*/
public int countNumberOfFailedStudentsOlderThan20Imperative(
final Student[] studentArray) {
int count = 0;
for (Student s : studentArray) {
if (!s.checkIsCurrent() && s.getAge() > 20 && s.getGrade() < 65) {
count++;
}
}
return count;
}
/**
* TODO compute the number of students who have failed the course who are
* also older than 20 years old. A failing grade is anything below a 65. A
* student has only failed the course if they have a failing grade and they
* are not currently active. This should mirror the functionality of
* countNumberOfFailedStudentsOlderThan20Imperative. This method should not
* use any loops.
*
* @param studentArray Student data for the class.
* @return Number of failed grades from students older than 20 years old.
*/
public int countNumberOfFailedStudentsOlderThan20ParallelStream(
final Student[] studentArray) {
return (int)Stream.of(studentArray).parallel()
.filter(s -> !s.checkIsCurrent()
&& s.getGrade() < 65 && s.getAge() > 20)
.count();
}
some more complex
/**
* Sequentially computes the most common first name out of all students that
* are no longer active in the class using loops.
*
* @param studentArray Student data for the class.
* @return Most common first name of inactive students
*/
public String mostCommonFirstNameOfInactiveStudentsImperative(
final Student[] studentArray) {
List<Student> inactiveStudents = new ArrayList<Student>();
for (Student s : studentArray) {
if (!s.checkIsCurrent()) {
inactiveStudents.add(s);
}
}
Map<String, Integer> nameCounts = new HashMap<String, Integer>();
for (Student s : inactiveStudents) {
if (nameCounts.containsKey(s.getFirstName())) {
nameCounts.put(s.getFirstName(),
new Integer(nameCounts.get(s.getFirstName()) + 1));
} else {
nameCounts.put(s.getFirstName(), 1);
}
}
String mostCommon = null;
int mostCommonCount = -1;
for (Map.Entry<String, Integer> entry : nameCounts.entrySet()) {
if (mostCommon == null || entry.getValue() > mostCommonCount) {
mostCommon = entry.getKey();
mostCommonCount = entry.getValue();
}
}
return mostCommon;
}
/**
* TODO compute the most common first name out of all students that are no
* longer active in the class using parallel streams. This should mirror the
* functionality of mostCommonFirstNameOfInactiveStudentsImperative. This
* method should not use any loops.
*
* @param studentArray Student data for the class.
* @return Most common first name of inactive students
*/
public String mostCommonFirstNameOfInactiveStudentsParallelStream(
final Student[] studentArray) {
Map<String, Long> map = Stream.of(studentArray).parallel()
.filter(s -> !s.checkIsCurrent())
.collect(Collectors.groupingBy(Student::getFirstName,
Collectors.counting()));
return map.keySet().stream()
.max((x, y) -> Long.compare(map.get(x), map.get(y))).get();
}
相比之下,这个例子更能体现出 stream 的易用性,在这里,collect 被用作一个收集器进行分类汇总,然后将结果传递给下游收集器 Collectors.counting() 进行进一步的 reduce 计算。
出了上面给出的例子,reduce 也是一个功能强大的 API,更多信息参考:
Java8-15-Stream 收集器 01-归约与汇总+分组
Java Streams,第 2 部分- 使用流执行聚合-轻松地分解数据