MySQL进阶必备知识(二):行格式、数据页结构
文章目录
- 前文
- MySQL的记录行记格式
- 存储数据方式
- 行格式的历史
- 行格式的具体信息
- 行溢出
- MySQL的数据页
- 数据页了解
- 数据页类型
- 数据页header
- user records和free space
- Page Directory(页目录)
- Page Header(页面头部)
- File Header(文件头部)
- File Trailer
- 总结
前文
继上篇:MySQL进阶必备知识(一):CS架构、配置文件、字符集等等,本篇继续分享MySQL另一大知识点:行格式和数据页结构,掌握了这两者,那么对MySQL如何存储数据就有了一个较为直观的理解!本文还是对MySQL 是怎样运行的:从根儿上理解 MySQL的总结拓展。话不多说,让我们开始吧!
首先提几个问题,带着问题往下看(以下指代的都是innodb):
- MySQL存储数据的方式?
- 全表扫描是如何进行的?
- B+树扮演一个什么角色?
- 每条记录是如何存储的?如何关联上下文?
- 记录与记录之间如何联系?数据页与数据页之间如何联系?
MySQL的记录行记格式
存储数据方式
我们先大致了解MySQL的存储数据方式:无论是存储数据还是读取数据,我们与MySQL的交互都是基于内存的,这样能保证速度。但是MySQL毕竟是基于磁盘的,所以就必变成读取的时候从磁盘刷到内存,存储的时候从内存刷到磁盘。那就出现一个问题:一次刷新一条记录,则取几万条数据就得和磁盘交互几万次,那磁盘的速度是非常慢的,所以引入了数据页的概念,innodb的数据页默认是16kb大小,每次从磁盘读取数据最小单位是页,即即使只读一条数据,仍旧会从磁盘读取一整个数据页。
那页与页之间是如何联系的?页里面又是如何存储的?答案是:页与页之间是通过双链表来联系的,每个页都有header来记录相关信息,hearder里包含了上下页的位置,这样就跟双链表一样通过指针联系在了一起!页里面是以记录的形式存储一行行的数据,也就是每insert into一条数据,就成为一行记录存储在数据页,记录与记录之间是以单链表的形式连接在一起的,每条记录也有所谓的header,里面包含了下一条所在位置的信息,即下一条相对位置的指针,即能以单链表的形式连接在一起。
行格式的历史
大致了解了存储数据方式,那来详细了解行格式的历史。早期的MySQL文件格式只有一种,所以没有命名,通用这一种。后期为了支持新功能,开发出了不兼容之前的文件格式,于是有了以下两种:
- Antelope: 早期的InnoDB文件格式,支持COMPACT 和 REDUNDANT
- Barracuda:新的InnoDB文件格式,支持COMPRESSED 和 DYNAMIC
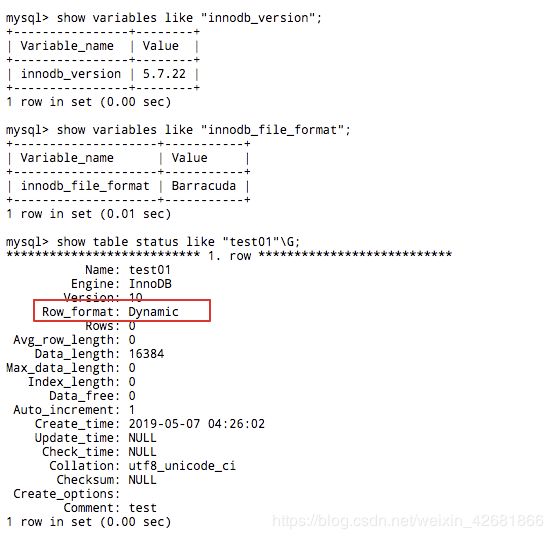
那现在截图我本机和服务器的两个版本的区别,一看便知!我本机是5.6.40,用的是Antelope,行格式是COMPACT;服务器上是5.7.22,用的是Barracuda,行格式是DYNAMIC。对应的查看语句如下:
show variables like "%innodb_version%";
show variables like "innodb_file_format";
show table status like "test03"\G;

行格式的具体信息
了解了行格式的历史由来,发现有4种行格式,其中也是有蛮多细节差别的,那如果一个个掌握肯定比较难,所以我就介绍compact这一种,也就是在innodb 5.7版本之前的,因为dynamic也是基于compact的,只是在其上优化了行溢出的字节,这个我们后面再讲!
那先附上官网地址:https://dev.mysql.com/doc/refman/5.7/en/innodb-row-format.html#innodb-row-format-compact
compact行格式的内容:

前三列是核心内容,可以理解为是“数据头”,后面的存储即是数据。
- 变长字段长度列表:用于存储数据里的可变长度(即varchar、text、blob等),存储的是其真实长度,比如a列varchar(100),但存储的那一行只存了3个字节,那就会对应存储0x03(16进制),再加上其他列的内容,组成长度列表存储在其中。注意:
1.字段是逆序存放;
2.存储的最大长度是2个字节,当允许存储的长度超过255字节且真实长度超过127个字节,用2个字节存储,其他的则用1个字节。而最大长度2个字节,说明了最大存储范围就是2^16即65536,当超过了即发生行溢出
3.如果所有列都是固定长度的(比如char),则该变长字段长度列表不存在。但如果存储的是char,而存储的字符集是utf8这类可变字符集,则仍旧属于变长字段 - NULL标志位:统计null值都有哪些列,有则标志为1(not null、主键列就不会存储),和变长字段长度列表相似的是,如果全部列都是not null,则该标志位也不存在;并且也是以逆序的形式存储
- 记录头信息:固定40个字节
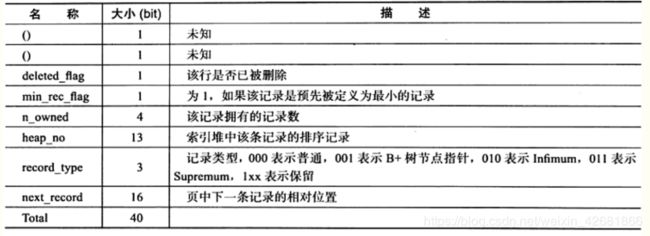
可以看到记录头信息包含了很多字段,这些字段是服务于数据页管理记录的,所以后面会详细介绍,这里需要知道的是:next_record指示下一条记录位置,即一开始我们所说的单链表指针,deleted_flag是表示该行是否删除,也就是当我们删除记录的时候,并不是马上删除,而是在这里标记,然后把所有deleted_flag都是删除的统一放到一个链表里删除! - 数据列
上述行格式除了前三列是”数据头“,后面就是一列列的数据列,需要注意的是,如果该行存储的是null值,则存储在null标志位,而不会存储到对应的数据列。详细可以参考该篇博文的例子:https://www.cnblogs.com/wade-luffy/p/6289183.html
另外,innodb会默认的给我们增加几个列:row_id(主键列,当表中不存在主键或者唯一索引建,innodb会默认添加,存在的话则不添加);transaction_id(事务id建);roll_pointer(回滚指针)
行溢出
讲到这里,基本的行格式就讲完了,让我们讲下行溢出,定义是:当innodb存储text、blob、varchar等可变长度的时候,当存储的数据超过行记录的最大长度时,会选择外部溢出页(overflow page)来存储,这称之为行溢出。在compact和redundant中,会存储真实数据的前768字节+20字节(指针指向外部溢出页),官网上这样说:


而在dynamic和compressed里面,碰到行溢出,则不会再存储前768个字节,而是直接存储20字节的指针指向外部溢出页。对应的官网:

MySQL的数据页
数据页了解
从上文介绍中了解到数据页默认大小是16kb,而数据页之间是以双向链表的形式存储,数据页里的记录以单链表的形式连接。所以这里可以介绍全表扫面的方式:即定位到第一个数据页,然后从第一条记录开始遍历,依次遍历完所有记录开始遍历第二个数据页,直到全部遍历完!可想而知这样的速度是非常慢的!
而我们知道,数据在innodb是以B+树(数据结构)的形式存储,涉及到B+就是涉及到索引的概念,等到索引那章在普及。这里只要了解一点的是,MySQL会默认给每张表创建聚蔟索引,聚蔟索引的特点是根据主键大小按升序创建,在B+树里面分层,底部叶子层存储的是一张张的数据页(数据页的记录包含所有数据,即所谓的索引即数据),非叶子层存储的则是目录结构(存储主键+数据页号),用于快速定位对应的数据页。所以,所谓的全表扫描,就是扫描聚蔟索引的叶子层数据!
因为innodb默认创建聚蔟索引,所以当我们用主键来查找数据的时候就非常快了,能利用到索引目录的结构非常迅速定位到目标!
数据页类型
MySQL的数据页类型有十多种,包括:索引页,Undo页,Inode页,系统页,BloB页等,但我们最常用的就是索引页,所以我们就针对该页来进行分析。接下来所说的数据页都指代索引页!
数据页header
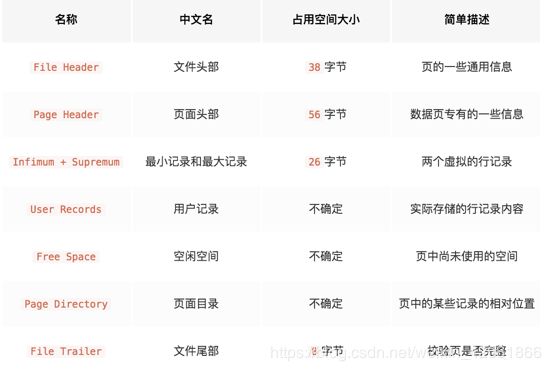
数据页的header即数据页头就是记载数据页的相关信息,可以说是数据页的核心部分(除了记录的真实数据)了,所以掌握了头部,就相当于掌握了数据页的结构。
user records和free space
可以看到涉及的字段还是非常多的,先来介绍user records和free space,这两者是相辅相成的,一开始数据页未插入记录数据的时候是空的,所以user records为空,当不断插入一条条数据,user records逐渐变大,free space则主键变小!
在此讲下之前的行格式的记录头信息的字段:
- delete_mark:当记录被删除的时候,被标记为1,此时链表会跨过这一条,并且该条会和其他条组成垃圾链表,之后再插入可能还能复用
- heap_no:表示记录在页中的位置,比如2、3、4、5,但是0和1是留给伪记录最小记录和最大记录的
- record_type:即表示记录的类型:0 普通记录,1 B+树非子节点,2最小记录,3最大记录
- next_record:即下一条记录的偏移量,要注意的是第一条永远是infimum,最后一条是supremum
当我们删除一条数据的操作:将next_record指向0,delete_mark指向1,同时会和其他被删的数据组成垃圾链表
Page Directory(页目录)
在页里面如何找到记录呢?通过遍历肯定是过慢的,于是槽的概念就出来了。我们知道索引页都是有序的,只要是有序,我们就能通过算法快速定位,比如二分法。
槽的定义:将记录分组,每组取其中最大的一条记录(在聚蔟索引里即主键最大)的地址偏移量,然后分别存储到靠近页的底部。而这个底部就被称之为页目录即page directory。
另外,我们知道行记录头里有n_owned这条属性,就是服务于记录分组的,可以记录改组的记录数量(规定最大不能超过8条)。
所以当我们在页里定位数据的流程是:
- 通过page directory用二分法定位到对应的槽
- 根据槽遍历对应的记录组所有记录,找到对应的那条
Page Header(页面头部)
用于表示数据页中记录的状态信息
里面的字段太多(记录了该页的信息),了解就行,要记住的:
- PAGE_N_DIR_SLOTS:有多少槽
- PAGE_LAST_INSERT:最后插入记录的位置(这样当下条记录来的时候直接就能定位到)
- PAGE_N_RECS;记录的数量(这也是服务于统计信息)
File Header(文件头部)
page header只针对索引页有效,file header基本针对所有页。前者记录了有多少记录、多少槽;后者记录了页编号、上一页、下一页页号。
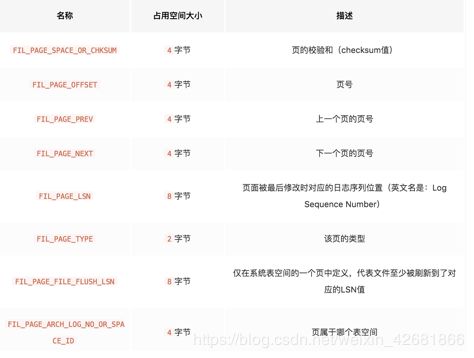
我们知道有很多类型的页,所以file header的存在是非常重要的,首先页的校验和即checksum就是和file trailer相对应,两者都有校验和,当我们从内存刷到磁盘,如何保证刷的数据页完整的刷过去了呢?就是通过校验和!另外就是页号的存在了,innodb通过表空间+页号唯一对应数据页,而这里存储了上一页和下一页的页号,这样就构成了开头所说的双向链表!
File Trailer
前4个字节:和file header搭配用于检验页的完整性,比如页的数据要从内存刷到磁盘,那怎么保证全部刷过去了呢?就是通过file header和file trailer的前4个字节,因为file header是最先刷的,file trailer最后刷,如果两者的前4个字节校验和不同,则说明数据没有完全刷到磁盘。
后4个字节:表示最后修改时对应的日志序列位置(LSN),也是用于校验是否完整。
总结
本次分享到这,山不转水转,我们下回再见!