MySQL小项目练习
文章目录
- 1、数据导入导出
- 1.1 导入sql
- 1.2导入csv文件
- 1.3 导出数据
- 2、作业
- 项目七:各部门工资最高的员工
- 项目八:换座位
- 项目九: 分数排名
- 项目十:行程和用户
1、数据导入导出
1.1 导入sql
mysql> create database bookrecommend;
mysql> use bookrecommend;
mysql> set names utf8;
mysql> source /Users/bishounendai/Downloads/bookRecommend--2/数据库备份/bookrecomme

1.2导入csv文件
(1)现有一个csv文件test1.csv,放于桌面

(2)新建数据库和表
#新建数据库
mysql> create database test1;
mysql> use test1
#新建表
mysql> create table if not exists student(
-> id int(11) not null,
-> name varchar(45) not null,
-> password varchar(45) not null,
-> primary key (id)
-> )ENGINE=InnoDB DEFAULT CHARSET=utf8;
#将csv文件导入mysql
mysql> load data infile '/Users/bishounendai/Desktop/test1.csv'--csv文件存放路径
-> into table student--要将数据导入的表名
-> fields terminated by ',' optionally enclosed by '"' escaped by '"'
-> lines terminated by '\r\n';
遇到的坑:
The MySQL server is running with the --secure-file-priv option so it cannot execute this statement
解决方案:
https://www.jianshu.com/p/9ef06f5a58da
(3)查询插入是否成功:
mysql> select * from student;
1.3 导出数据
(1)将数据导出到text中
mysql> SELECT * FROM runoob_tbl
-> INTO OUTFILE '/tmp/runoob.txt';
(2)将数据导出到csv文件中
mysql> SELECT * FROM passwd INTO OUTFILE '/tmp/runoob.txt'
-> FIELDS TERMINATED BY ',' ENCLOSED BY '"'
-> LINES TERMINATED BY '\r\n';
2、作业
项目七:各部门工资最高的员工
任务:编写一个 SQL 查询,找出每个部门工资最高的员工。例如,根据下述给定的表格,Max 在 IT 部门有最高工资,Henry 在 Sales 部门有最高工资。
(1)创建Employee 表,包含所有员工信息,每个员工有其对应的 Id, salary 和 department Id。
CREATE TABLE Employee(
Id INT(10) NOT NULL PRIMARY KEY,
Name VARCHAR(20),
Salary VARCHAR(20),
DepartmentId INT(10)
);
(2)创建Department 表,包含公司所有部门的信息。
CREATE TABLE Department(
Id INT(10) NOT NULL PRIMARY KEY,
Name VARCHAR(20)
);
(3)插入数据
INSERT INTO Employee(
Id,Name,Salary,DepartmentId
)VALUES(1,'Joe','70000',1),
(2,'Henry','80000',2),
(3,'Sam','60000',2),
(4,'Max','90000',1);
INSERT INTO Department(
Id,Name
)VALUES(1,'IT'),
(2,'Sales');
展示数据表

#思路:根据DepartmentId进行左连接,员工表后加上一列行业,再根据DepartmentId进行分组,寻找每个行业中薪资最高的员工。
mysql> SELECT d.Name AS Department,
-> e.Name AS Employee,
-> e.Salary
-> FROM Employee AS e
-> LEFT JOIN
-> Department AS d ON e.DepartmentId = d.Id
-> WHERE (e.DepartmentId, e.Salary) IN (SELECT e1.DepartmentId,MAX(e1.Salary) AS Salary FROM Employee e1 GROUP BY e1.DepartmentId);

项目八:换座位
小美是一所中学的信息科技老师,她有一张 seat 座位表,平时用来储存学生名字和与他们相对应的座位 id。其中纵列的 id 是连续递增的小美想改变相邻俩学生的座位。你能不能帮她写一个 SQL query 来输出小美想要的结果呢?
示例:
±--------±--------+
| id | student |
±--------±--------+
| 1 | Abbot |
| 2 | Doris |
| 3 | Emerson |
| 4 | Green |
| 5 | Jeames |
±--------±--------+
假如数据输入的是上表,则输出结果如下:
±--------±--------+
| id | student |
±--------±--------+
| 1 | Doris |
| 2 | Abbot |
| 3 | Green |
| 4 | Emerson |
| 5 | Jeames |
±--------±--------+
注意:
如果学生人数是奇数,则不需要改变最后一个同学的座位。
(1)创建表
CREATE TABLE seat(
id INT(10) NOT NULL PRIMARY KEY,
student VARCHAR(10)
);
(2)插入数据
INSERT INTO seat(id,student)
VALUES
(1,"Abbot"),
(2,"Doris"),
(3,"Emerson"),
(4,"Green"),
(5,"Jeames");
(3)判断id 是奇数且最后一个 id不变。
判断id是奇数且不为最后一个 id+1,判断id是偶数 id-1
SELECT (
CASE WHEN id%2=1 and id = (SELECT COUNT(*) FROM seat) THEN id
WHEN id%2 =1 THEN id+1
ELSE id-1
END
) AS id,student
FROM seat
ORDER BY id;
结果如下:

项目九: 分数排名
编写一个 SQL 查询来实现分数排名。如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
创建以下score表:
±—±------+
| Id | Score |
±—±------+
| 1 | 3.50 |
| 2 | 3.65 |
| 3 | 4.00 |
| 4 | 3.85 |
| 5 | 4.00 |
| 6 | 3.65 |
±—±------+
例如,根据上述给定的 Scores 表,你的查询应该返回(按分数从高到低排列):
±------±-----+
| Score | Rank |
±------±-----+
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 2 |
| 3.65 | 3 |
| 3.65 | 3 |
| 3.50 | 4 |
±------±-----+
(1)创建表
CREATE TABLE score(
Id INT(10) NOT NULL PRIMARY KEY,
Score FLOAT(4)
);
(2)插入数据
INSERT INTO score(Id,Score)
VALUES
(1,3.50),
(2,3.65),
(3,4.00),
(4,3.85),
(5,4.00),
(6,3.65);

mysql> SELECT Score,(SELECT COUNT(DISTINCT score) from score WHERE score >= s.score) as Rank
-> from score as s
-> ORDER BY Score DESC;
项目十:行程和用户
Trips 表中存所有出租车的行程信息。每段行程有唯一键 Id,Client_Id 和 Driver_Id 是 Users 表中 Users_Id 的外键。Status 是枚举类型,枚举成员为 (‘completed’, ‘cancelled_by_driver’, ‘cancelled_by_client’)。
±—±----------±----------±--------±-------------------±---------+
| Id | Client_Id | Driver_Id | City_Id | Status |Request_at|
±—±----------±----------±--------±-------------------±---------+
| 1 | 1 | 10 | 1 | completed |2013-10-01|
| 2 | 2 | 11 | 1 | cancelled_by_driver|2013-10-01|
| 3 | 3 | 12 | 6 | completed |2013-10-01|
| 4 | 4 | 13 | 6 | cancelled_by_client|2013-10-01|
| 5 | 1 | 10 | 1 | completed |2013-10-02|
| 6 | 2 | 11 | 6 | completed |2013-10-02|
| 7 | 3 | 12 | 6 | completed |2013-10-02|
| 8 | 2 | 12 | 12 | completed |2013-10-03|
| 9 | 3 | 10 | 12 | completed |2013-10-03|
| 10 | 4 | 13 | 12 | cancelled_by_driver|2013-10-03|
±—±----------±----------±--------±-------------------±---------+
Users 表存所有用户。每个用户有唯一键 Users_Id。Banned 表示这个用户是否被禁止,Role 则是一个表示(‘client’, ‘driver’, ‘partner’)的枚举类型。
±---------±-------±-------+
| Users_Id | Banned | Role |
±---------±-------±-------+
| 1 | No | client |
| 2 | Yes | client |
| 3 | No | client |
| 4 | No | client |
| 10 | No | driver |
| 11 | No | driver |
| 12 | No | driver |
| 13 | No | driver |
±---------±-------±-------+
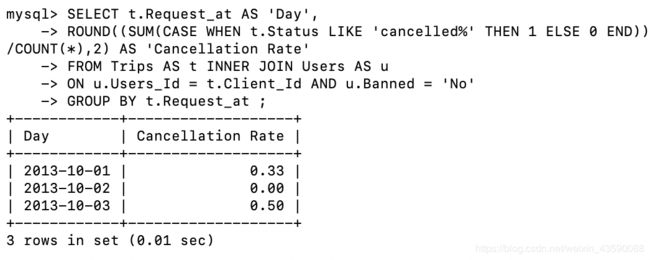
写一段 SQL 语句查出 2013年10月1日 至 2013年10月3日 期间非禁止用户的取消率。基于上表,你的 SQL 语句应返回如下结果,取消率(Cancellation Rate)保留两位小数。
±-----------±------------------+
| Day | Cancellation Rate |
±-----------±------------------+
| 2013-10-01 | 0.33 |
| 2013-10-02 | 0.00 |
| 2013-10-03 | 0.50 |
±-----------±------------------+
(1)创建表
CREATE TABLE trips(
Id INT NOT NULL PRIMARY KEY AUTO_INCREMENT,
Client_Id INT NOT NULL,
Driver_Id INT NOT NULL,
City_Id INT NOT NULL,
Status ENUM('completed', 'cancelled_by_driver', 'cancelled_by_client') NOT NULL,
Request_at DATE DEFAULT NULL);
CREATE TABLE Users(
Users_Id INT NOT NULL PRIMARY KEY AUTO_INCREMENT,
Banned VARCHAR(10) NOT NULL,
Role ENUM('client', 'driver', 'partnet') NOT NULL);
(2)插入数据
INSERT INTO trips
VALUES (1,1,10,1,'completed','2013-10-01'),
(2,2,11,1, 'cancelled_by_driver','2013-10-01'),
(3,3,12,6,'completed','2013-10-01'),
(4,4,13,6,'cancelled_by_client','2013-10-01'),
(5,1,10,1,'completed','2013-10-02'),
(6,2,11,6,'completed','2013-10-02'),
(7,3,12,6,'completed','2013-10-02'),
(8,2,12,12,'completed','2013-10-03'),
(9,3,10,12,'completed','2013-10-03'),
(10,4,13,12, 'cancelled_by_driver','2013-10-03');
INSERT INTO Users
VALUES (1, 'No', 'client'),
(2, 'Yes', 'client'),
(3, 'No', 'client'),
(4, 'No', 'client'),
(10, 'No', 'driver'),
(11, 'No', 'driver'),
(12, 'No', 'driver'),
(13, 'No', 'driver');
(3)查询语句
SELECT t.Request_at AS 'Day',
ROUND((SUM(CASE WHEN t.Status LIKE 'cancelled%' THEN 1 ELSE 0 END))/COUNT(*),2) AS 'Cancellation Rate'
FROM Trips AS t INNER JOIN Users AS u
ON u.Users_Id = t.Client_Id AND u.Banned = 'No'
GROUP BY t.Request_at ;