Elasticsearch 预处理没有奇技淫巧,请先用好这一招!
1、上问题
1.1 线上实战问题 1——字符串切分
es可以根据_id字符串切分,再聚合统计吗 比如:数据1、_id=C12345 数据2、_id=C12456 数据3、_id=C31268
通过es聚合统计 C1开头的数量有2个 C3开头的数据有1个
这个API怎么写,有大佬指导下吗?
1.2 线上实战问题 2——json 转 object
插入的时候,能不能对原数据进行一定的转化,再进行indexing
{
"headers":{
"userInfo":[
"{ \"password\": \"test\",\n \"username\": \"zy\"}"
]
}
}
这里面的已经是字符串了,能在数据插入阶段把这个 json 转成 object 么?
1.3 线上实战问题 3——更新数组元素
我想对一个list每个值后面都加一个字符:
比如 {"tag":["a","b","c"]} 这样一个文档 我想变成 {"tag":["a2","b2","c2"]} 这样的,
各位有没有试过用 foreach 和 script 结合使用?
2、问题拆解分析
「问题 1」:分析环节需要聚合统计,当然用painless script 也能实现,但数据量大,势必有性能问题。
可以把数据处理前置,把前_id两个字符提取出来,作为一个字段处理。
「问题 2」:写入的时候期望做字符类型的转换,把复杂的字符串转换为格式化后的 Object 对象数据。
「问题 3」:数组类型数据全部规则化更新,当然 painless script 脚本也可以实现。
但是,在写入环节处理,就能极大减轻后面分析环节的负担。
以上三个问题,写入前用 java 或者 python 写程序处理,然后再写入 Elasticsearch 也是一种方案。
但,如果要死磕一把,有没有更好的方案呢?能否在写入前进行数据的预处理呢?
3、什么是数据预处理
一般情况下,我们程序写入数据或者从第三方数据源(Mysql、Oracle、HBase、Spark等)导入数据,都是原始数据张什么样,直接批量同步 ES,写入ES索引化的数据就是什么样。如下图所示:
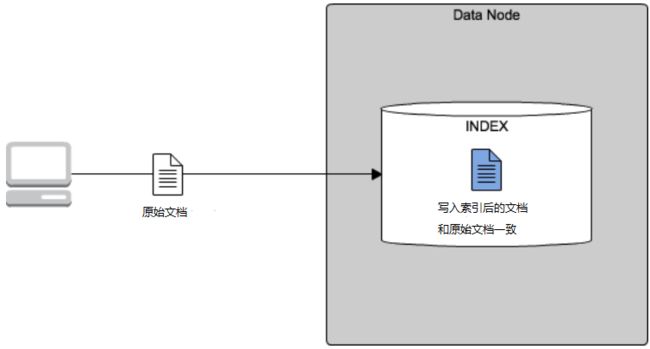
如前所述的三个实战问题,实际业务数据可能不见得是我们真正分析环节所需要的。
需要对这些数据进行合理的预处理后,才便于后面环节的分析和数据挖掘。
数据预处理的步骤大致拆解如下:
数据清洗。
主要是为了去除 重复数据,去噪音(即干扰数据)以及填充缺省值。
数据集成。
将多个数据源的数据放在一个统一的数据存储中。
数据转换。
将数据转化成适合数据挖掘或分析的形式。
在 Elasticsearch 中,有没有预处理的实现呢?
4、Elasticsearch 数据预处理
Elasticsearch的ETL利器——Ingest节点,已经将节点角色划分、Ingest 节点作用,Ingest 实践、Ingest 和 logstash 预处理优缺点对比都做了解读。有相关盲点的同学,可以移步过去过一遍知识点。
Ingest 节点的本质——在实际文档建立索引之前,使用 Ingest 节点对文档进行预处理。Ingest 节点拦截批量索引和单个索引请求,应用转换,然后将文档传递回单个索引或批量索引API 写入数据。
下面这张图,比较形象的说明的 Elasticsearch 数据预处理的流程。
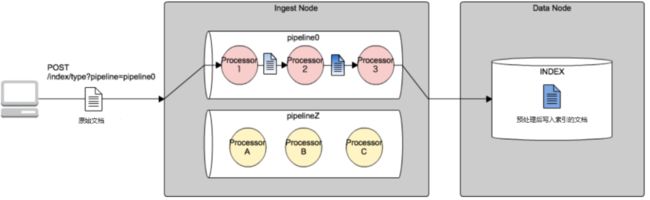
实际业务场景中,预处理步骤如下:
步骤1:定义 Pipeline,通过 Pipeline 实现数据预处理。
根据实际要处理的复杂数据的特点,有针对性的设置1个或者多个 pipeline (管道),上图的粉红和黄色部分。
步骤2:写入数据关联Pipeline。
写入数据、更新数据或者 reindex 索引环节,指定要处理索引的 pipeline , 实际就是写入索引与上面的 pipeline0 和 pipelineZ 关联起来。
步骤3:写入数据。
划重点:Ingest 实现在实际文档编制索引(索引化)之前对文档进行预处理。
5、实践一把
5.1 线上问题 1 实现
PUT _ingest/pipeline/split_id
{
"processors": [
{
"script": {
"lang": "painless",
"source": "ctx.myid_prefix = ctx.myid.substring(0,2)"
}
}
]
}
借助 script 处理器中的 substring 提取子串,构造新的前缀串字段,用于分析环节的聚合操作。
5.2 线上问题 2 实现
PUT _ingest/pipeline/json_builder
{
"processors": [
{
"json": {
"field": "headers.userInfo",
"target_field": "headers.userInfo.target"
}
}
]
}
借助 json 处理器做字段类型转换,字符串转成了 json。
5.3 线上问题3 实现
PUT _ingest/pipeline/add_builder
{
"processors": [
{
"script": {
"lang": "painless",
"source": """
for (int i=0; i < ctx.tag.length;i++) {
ctx.tag[i]=ctx.tag[i]+"2";
}
"""
}
}
]
}
借助 script 处理器,循环遍历数组,实现了每个数组字段内容的再填充。
篇幅原因,更详细解读参见:
https://github.com/mingyitianxia/deep_elasticsearch/blob/master/es_dsl_study/1.ingest_dsl.md
6、不预处理 VS 预处理后写入方案对比
「方案 1」:数据原样导入Elasticsearch,分析阶段再做 painless 脚本处理。简单粗暴。
导入一时爽,处理费大劲!
如前所述,script 处理能力有限,且由于 script 徒增性能问题烦恼。
不推荐使用。
「方案 2」:提前借助 Ingest 节点实现数据预处理,做好必要的数据的清洗(ETL) 操作,哪怕增大空间存储(如新增字段),也要以空间换时间,为后续分析环节扫清障碍。
看似写入变得复杂,实则必须。「以空间为分析赢取了时间」。
推荐使用。
7、常见问题
7.1 Ingest 节点是必须设置的吗?
默认情况下,所有节点都默认启用 Ingest,因此任何节点都可以完成数据的预处理任务。
但是,当集群数据量级够大,集群规模够大后,建议拆分节点角色,和独立主节点、独立协调节点一样,设置独立专用的 Ingest 节点。
7.2 pipeline 什么时候指定呢?
创建索引、创建模板、更新索引、reindex 以及 update_by_query 环节 都可以指定 pipeline。
7.2.1 创建索引环节指定 pipeline
PUT ms-test
{
"settings": {
"index.default_pipeline": "init_pipeline"
}
}
7.2.2 创建模板环节指定 pipeline
PUT _template/template_1
{
"index_patterns": ["te*", "bar*"],
"settings": {
"number_of_shards": 1,
"index.default_pipeline":"add_builder"
}
}
7.2.3 更新索引环节指定pipeline(原索引未指定)
PUT /my_index/_settings
{
"index" : {
"default_pipeline" : "my_pipeline"
}
}
7.2.4 reindex 环节添加 pipeline
POST _reindex
{
"source": {
"index": "source"
},
"dest": {
"index": "dest",
"pipeline": "some_ingest_pipeline"
}
}
7.2.5 update 环节指定pipeline
POST twitter/_update_by_query?pipeline=set-foo
8、小结
开篇三个问题都是在死磕 Elasticsearch QQ群、微信群中讨论的线上业务问题。借助 Elasticsearch Ingest 节点的预处理环节,都能很好的解决。
Ingest Pipelines 是 Elasticsearch 数据预处理的核心功能,一旦将其应用于生产实战环境,你会发现很“「香」”,并且你会离不开它。
参考:
https://dev.classmethod.jp/server-side/elasticsearch/elasticsearch-ingest-node/
《数据分析实战 45 讲》
推荐更多:
Elasticsearch的ETL利器——Ingest节点

更短时间更快习得更多干货!
中国1/5的Elastic认证工程师出自于此!