数据结构心得3——图
数据结构心得3——图
目录:
1. 图及其基本概念
2. 图的存储方式
3. 图的遍历
4. 最小生成树
5. 最短路径
图及其基本概念
图的定义:图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),其中,G表示一个图,V是图G中顶点的集合,E是图G中边的集合。
有向图: 顶点对
无向图: 顶点对(x, y)是无序的。
完全图:如果任意两个顶点之间都存在边叫完全图。n个顶点,对于完全无向图,共有n(n-1)/2条边,而完全有向图为n(n-1)条边。(想想一个顶点可以连接除它本身之外的n-1条边,就很容易理解这个原理了)。
连通图:在无向图G中,任意两个顶点是相通的就是连通图。
子图: 设有两个图 G=(V, E) 和 G‘=(V’, E‘)。若 V’包含于 V 且 E‘包含于E, 则称图G’是图G 的子图。
强连通图:在有向图中, 若对于每一对顶点vi和vj, 都存在一条从vi到vj和从vj到vi的路径, 则称此图是强连通图。
顶点的度:顶点关联边的数目。有向图图中有,入度:方向指向顶点的边;出度:方向背向顶点的边。在有向图中顶点的度就是两者之和。
路径:在图 G=(V, E) 中, 若从顶点 vi 出发, 沿一些边经过一些顶点 vp1, vp2, …, vpm,到达顶点vj。则称顶点序列 (vi vp1 vp2 ... vpm vj) 为从顶点vi 到顶点 vj 的路径。
路径长度:非带权图的路径长度是指此路径上边的条数。带权图的路径长度是指路径上各边的权之和。
简单路径: 若路径上各顶点 v1,v2,...,vm 均不 互相重复, 则称这样的路径为简单路径。
回路: 若路径上第一个顶点 v1 与最后一个顶点vm 重合, 则称这样的路径为回路或环。
连通:在无向图中, 若从顶点v1到顶点v2有路径, 则称顶点v1与v2是连通的。
连通图:如果图中任意一对顶点都是连通的, 则称此图是连通图。
连通分量:非连通图的极大连通子图叫做连通分量。
强连通分量:非强连通图的极大强连通子图叫做强连通分量。
图的存储方式
邻接矩阵表示法
邻接顶点:如果 (u, v) 是 E(G) 中的一条边,则称 u 与 v 互为邻接顶点。
邻接矩阵:在图的邻接矩阵表示中,有一个记录各个顶点信息的顶点表(一维数组),还有一个表示各个顶点之间关系的邻接矩阵(二维数组)。
有向图、无向图的邻接矩阵表示(考点):
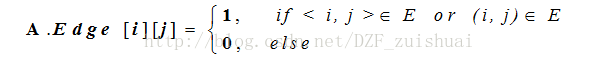
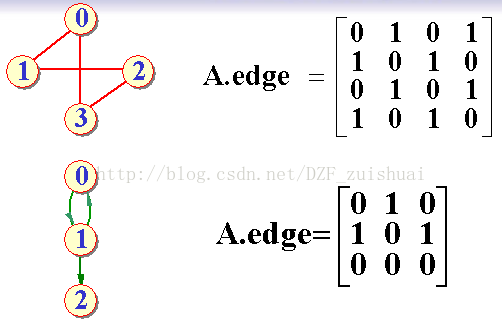
这种题,很可能给一个有向图或者无向图的邻接矩阵,让画出图的表示。或者给出有向图的邻接矩阵,让求入度和出度,记住“行出列入”,即行之和是出度,列之和为入度。同时也要记住,无向图的邻接矩阵是对称阵。
网络的邻接矩阵表示(考点):
带权的图叫做网络,网络的邻接矩阵与图的邻接矩阵表示大致相近,具体公式如下:


此时,0不再表示不连通,而是表示顶点自身和自身的关系,至于不连通,则使用无穷大表示,在实际编程过程中,通常用一个很大的数来表示无穷大。其边的权重,代替了图的表示法的1。至于题型,和上文出题方式一致。
注意:也有教材采用无穷大表示自身和自身,并不影响什么。
邻接表
数组和链表相结合的存储方法为邻接表。图中顶点用一个一维数组存储,每个顶点Vi的所有邻接点构成一个线性表。其实就是建立一个节点数组,或者说是一个链表数组。
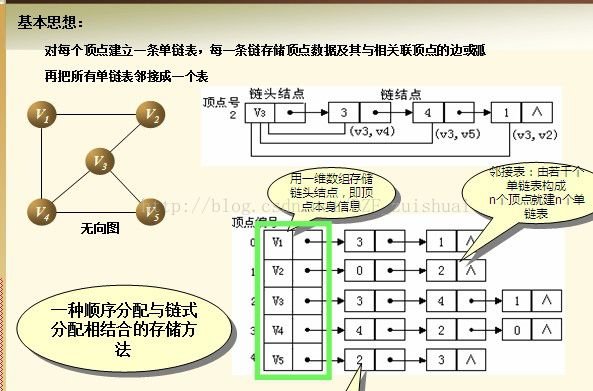
对于有向图,出度表叫邻接表,入度表叫逆邻接表。
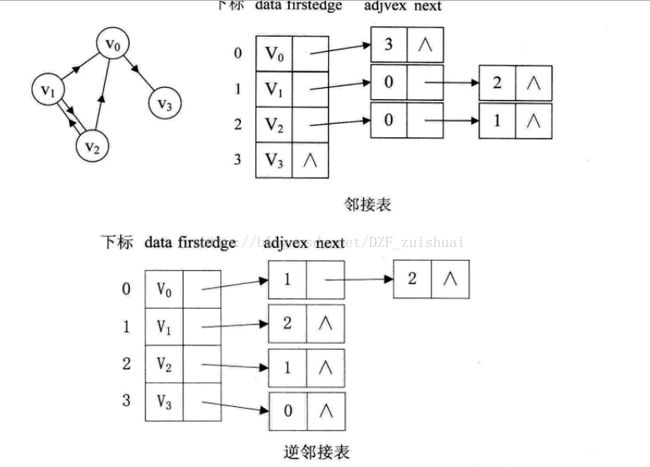
对于网络,实际上就是节点类多出了一个权数而以,称之为cost

两个结论:设图中有 n 个顶点,e 条边,则用邻接表表示无向图时,需要 n 个顶点结点,2e 个边结点;用邻接表表示有向图时,若不考虑逆邻接表,只需 n 个顶点结点,e 个边结点。
图的遍历
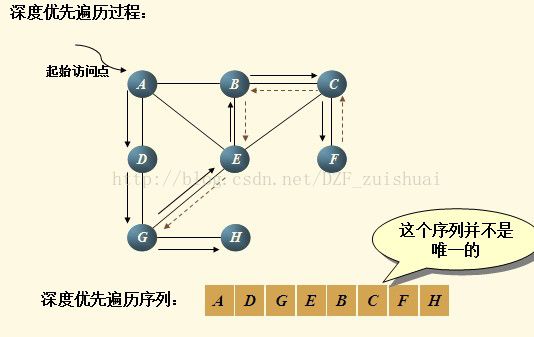
深度优先遍历DFS (Depth First Search)
1 首先访问顶点i
2 若当前访问的顶点的邻接顶点有未被访问的,则任选一个访问之;
反之,退回到最近访问过的顶点;直到与起始顶点相通的全部顶点都访问完毕;
3 若此时图中尚有顶点未被访问,则再选其中一个顶点作为起始顶点并访问之,重复上述过程; 反之,遍历结束
为记录访问情况,需要一个数组,访问该结点后,将其访问标记置为访问过,即visited[i]=1。

广度优先遍历方法:BFS (Breadth First Search)
1首先访问顶点i,并将其访问标志置为已被访问,即visited[i]=1;
2 接着依次访问与顶点i有边相连的所有顶点W1,W2,…,Wt
3然后再按顺序访问与W1,W2,…,Wt有边相连又未曾访问过的顶点;依此类推,直到图中所有顶点都被访问完为止。
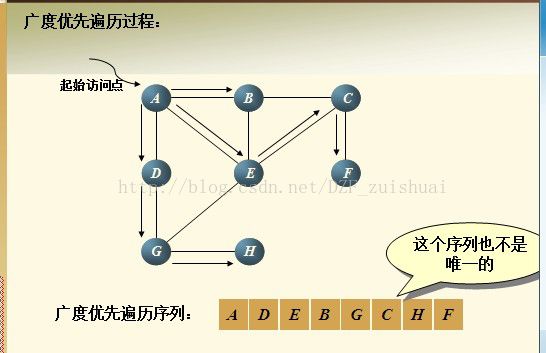
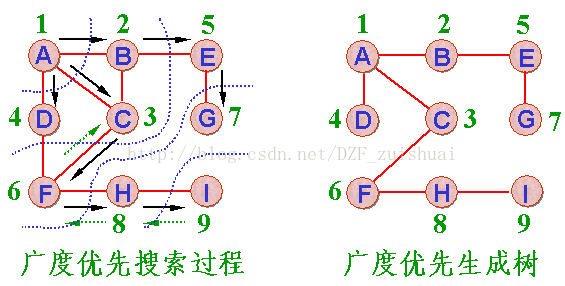
需要说明的是,这两种遍历方式,结果都不唯一。因此只要掌握其思想就好。
最小生成树
最小生成树:n个顶点的生成树很多,最小生成树就需要从这很多树中选一棵代价最小的生成树(即该树各边的代价或者称之为权重之和最小)。
贪心算法的思想:分解问题,对各个问题求局部最优,最后各个局部最优解堆叠形成全局最优解。对于简单的优化问题,这种解决方法可行,如求最小生成树的Prim算法和Kruskal算法,就是通过贪心策略实现的;但是对于复杂的优化问题,使用贪心算法容易陷入局部最优,难以得到所期望的全局最优,对于复杂的优化问题,启发式算法更具优越性。
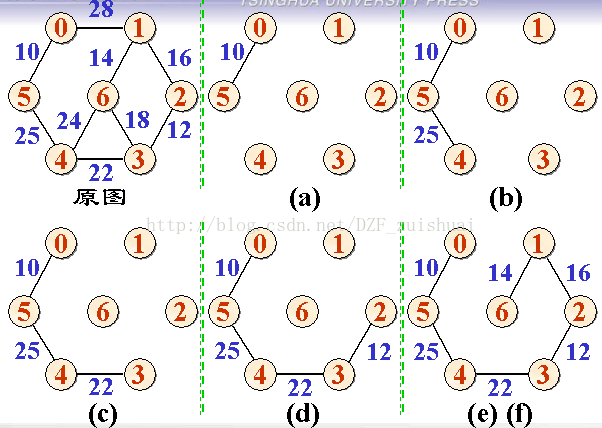
Prim算法
1).输入:一个加权连通图,其中顶点集合为V,边集合为E;
2).初始化:Vnew = {x},其中x为集合V中的任一节点(起始点),Enew = {},为空;
3).重复下列操作,直到Vnew = V:
a.在集合E中选取权值最小的边
b.将v加入集合Vnew中,将
4).输出:使用集合Vnew和Enew来描述所得到的最小生成树。
看起来很复杂,简单的说就是,先随便找个节点当成起始点,然后就找一个和这个起始点相连的权重最小的顶点连起来,然后再看和这两个点相连的顶点,选最小权重边的点再相连,之后重复该操作,但是要保证任意连线不构成回路就好。对,就是这么简单。
Kruskal算法
1).记Graph中有v个顶点,e个边。
2).新建图Graphnew,Graphnew中拥有原图中相同的e个顶点,但没有边。
3).将原图Graph中所有e个边按权值从小到大排序。
4).循环:从权值最小的边开始遍历每条边 直至图Graph中所有的节点都在同一个连通分量中if 这条边连接的两个节点于图Graphnew中且不在同一个连通分量中,添加这条边到图Graphnew中。
说白了,就是把边排序,选小的且不构成回路的连接,就构成了最小生成树。
两种算法时间复杂度比较
设n个顶点,e条边:
Prim: T(n)=O(n2), 适合边多的稠密度。
Kruskl: T(n)=O(elog2e), 适合边少的稀疏图。
最短路径
这里课堂上只讲了Dijkstra算法,这部分内容也会在运筹学课堂上讲到。别人家的博客已经写的很完善了,所以谢谢大佬的博客,直接上链接:
https://www.cnblogs.com/liuzhen1995/p/6527929.html
https://www.cnblogs.com/he-px/p/6677063.html
声明:由于本片博客借鉴了很多他人的内容,如有侵权,请联系我删除!