Facebook 最新力作 FBNetV3来了!相比 ResNeSt 提速 5 倍,精度不输 EfficientNet
原文链接:Facebook 最新力作 FBNetV3来了!相比 ResNeSt 提速 5 倍,精度不输 EfficientNet
FBNetV1:https://arxiv.org/abs/1812.03443
FBNetV2: https://arxiv.org/abs/2004.05565
FBNetV3: https://arxiv.org/abs/20206.02049
今天逛arxiv时看到了FBNetV3一文,虽然笔者对NAS相关方法并不感冒,但考虑到FBNetV3都出来了,V4出的可能并不大了。尤其当笔者看到FNBetV3可以取得媲美EfficientNet与ResNeSt的精度同时具有更少的FLOPs。索性就花点时间简简单单聊一下FBNet系列咯。注:FBNetV1与FBNetV2已开源,FNBetV3尚未开源,但应该不久,期待FBNetV3能尽快开源。
Abstract
这篇论文提到了一个比较有意思的点:网络架构与训练策略同时进行搜索。这是之前的方法所并未尝试的一个点,之前的方法主要聚焦在网络架构,而训练方法则是采用比较常规的一组训练方式。也许这就是“灯下黑”的缘故吧,看到了网络架构的重要性影响而忽略了训练方式在精度方面的“小影响”。但是,当精度达到一定程度之后,训练方式的这点影响就变得尤为重要了。
所以Facebook的研究员从这点出发提出了FBNetV3,它将网络架构与对应的训练策略通过NAS联合搜索。在ImageNet数据集上,FBNetV3取得了媲美EfficientNet与ResNeSt性能的同时具有更低的FLOPs(1.4x and 5.0x fewer);更重要的是,该方案可以跨网络、跨任务取得一致性的性能提升。
Contribute
尽管NAS在网路架构方面取得了非常好的结果,比如EfficientNet、MixNet、MobileNetV3等等。但无论基于梯度的NAS,还是基于supernet的NAS,亦或给予强化学习的NAS均存在这几个缺陷:
- 忽略了训练超参数,即仅仅关注于网络架构而忽略了训练超参数的影响;
- 仅支持一次性应用,即在特定约束下只会输出一个模型,不同约束需要不同的模型。
为解决上述所提到的缺陷,作者提出了JointNAS同时对网络架构与训练策略进行搜索。JointNAS是一种两阶段的有约束的搜索方法,它包含粗粒度与细粒度两个阶段。本文贡献主要包含下面几点:
- Joint training-architecture search
- Generalizable training recipe
- Multi-use predictor
- State-of-the-art ImageNet accuracy
Method
该文的目标是:在给定资源约束下,搜索具有最高精度的网路架构与训练策略。该问题可以通过如下公式进行描述:
m a x ( A , b ) ∈ Ω a c c ( A , h ) , s.t. g i ( A ) ≤ C i for i = 1 , ⋯ , γ max_{(A,b) \in \Omega} acc(A,h), \text{ s.t. } g_i(A)\le C_i \text{ for }i = 1, \cdots, \gamma max(A,b)∈Ωacc(A,h), s.t. gi(A)≤Ci for i=1,⋯,γ
其中, A , h , Ω A,h,\Omega A,h,Ω分别表示网络架构、训练策略以及搜索空间(见下表); g i ( A ) , γ g_i(A),\gamma gi(A),γ表示资源约束信息,比如计算量、存储以及推理耗时灯。

如果搜索空间过大则会导致搜索评估变得不可能,为缓解复杂度问题,作者设计了一种两阶段的搜索算法:(1)粗粒度搜索;(2)细粒度搜索。见下图中的算法1.

Coarse-grained Search
第一阶段的粗粒度搜索将输出精度预测器与一组候选网络架构。

- Neural Acquisition Function,即预测器,见上图。它包含编码架构与两个head:(1)Auxiliary proxy head用于预训练编码架构、预测架构统计信息(比如FLOPs与参数两)。注:网络架构通过one-hot方式进行编码;(2)精度预测器,它接收训练策略与网路架构,同时迭代优化给出架构的精度评估。
- Early-stopping,作者还引入一种早停策略以降低候选网络评估的计算消耗;
- Predictor training,得到候选网络后,作者提出训练50epoch同时冻结嵌入层,然后对整个模型再次训练50epoch。作者采用Huber损失训练该精度预测器。该损失有助于使模型避免异常主导现象(prevents the model from being dominated by outliers)。
Fine-grained Search
第二阶段的搜索是一种基于自适应遗传算法的迭代过程,它以第一阶段的搜索结果作为初代候选,在每次迭代时,对其进行遗传变异更新并评估每个个体的得分,从中选择K个得分最高的子代进行下一轮的迭代,直到搜索完毕,最终它将输出具有最高精度的网络与训练策略。
Search space
作者所设计的搜索空间包含训练策略以及网络架构,其中训练策略部分所搜空间包含优化器类型、初始学习率、权重衰减、mixup比例、dropout比例、随机深度drop比例、应用EMA与否;网络脚骨的所搜空间则基于inverted residual而设计,包含输入分辨率、卷积核尺寸、扩展因子、每层通道数以及深度。具体见下表。
在自动训练实验中,作者仅在固定架构上调整了训练策略;而在联合搜索时,作者对训练策略以及网络架构同时进行搜索,整个搜索空间大小为 1 0 17 10^{17} 1017个网络架构与 1 0 7 10^7 107个训练策略。
Experiments
作者首先对给定网络在一个较小的搜索空间下验证其搜索算法;然后在联合搜索任务上评估所提方法。注:为降低搜索时间,作者在ImageNet数据集中随机选择了200类别,并从训练集中随机构建了一个10K的验证集。
AutoTrain
在该部分实验中,作者选择FBNetV2-L3作为基准模型,主要进行训练策略的搜索。从搜索结果来看:RMSProp优于SGD,同时采用了EMA。该组训练策略可以提升模型0.8%精度。更多的实验结果见下图,可以看到在多个网络中,AutoTrain方式均可取得性能上的一致提升,这说明了AutoTrain的泛化性能。与此同时,还可以看到EMA可以进一步提升模型的精度。

Search for efficient networks
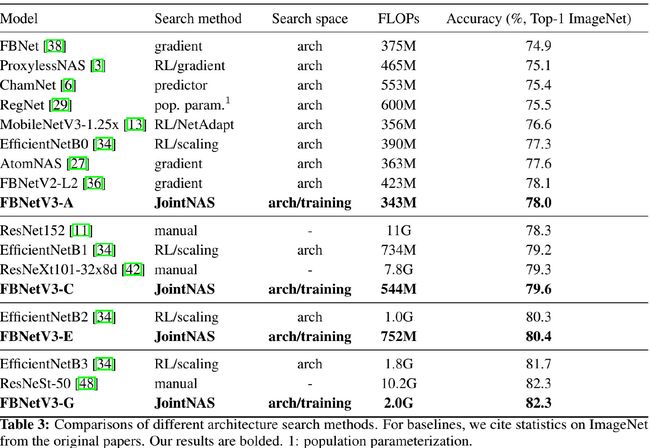
前面的实验验证了训练策略搜索的重要性,这里将对联合搜索进行尝试。搜索结果与其他NAS结果对比见下表。从表中对比可以看到:所提方法取得了更高的精度。比如FBNetV3-E取得了80.4%的精度,而与之对标的EfficientNetB2的精度为80.3%,而它们的FLOPs对比则似乎752M vs 1G;取得了82.3%精度的FBNetV3-G,而与之对标的ResNeSt在相同精度下FLOP却是其5倍之多。
Ablation Study
除此之外,作者还进行了一些消融实验分析。
- 网络架构与训练策略的成对性:见下图中Table4。从一定程度上说明: 仅搜索网络架构只能得到次优结果;
- 细粒度搜索的重要性:见下图的Table5。从一定程度上说明:细粒度搜索可以进一步提升的模型的性能。

- EMA的泛化性能分析:作者通过实验发现了EMA在分类任务上取得了性能的一致提升。认为这种策略同样适用于其他任务,并在COCO目标检测任务上进行了验证,结果见下图。可以看到:EMA策略确实取得了更优的结果。看来EMA也是一种非常棒的trick,提升精度的同时又不影响训练和推理,各位小伙伴还在等什么?快点用起来吧!

Conclusion
Facebook的研究员提出了一种比较好的NAS方案,它将训练策略纳入到网络架构的搜索过程中。之前的研究往往只关注网络架构的搜索而忽视了训练策略的影响,这确实是一点比较容易忽视的。所谓的“灯下黑”,吼吼,笔者突然意识到:是不是还可以将参数初始化方式那纳入到搜索空间呢?感兴趣的小伙伴还不快点去尝试一下。
◎作者档案
Happy,一个爱“胡思乱想”的AI行者
个人公众号:AIWalker
欢迎大家联系极市小编(微信ID:fengcall19)加入极市原创作者行列
关注极市平台公众号(ID:extrememart),获取计算机视觉前沿资讯/技术干货/招聘面经等
