大数据HDFS的NameNode和SecondaryNameNode区别以及DataNode(面试开发重点)
NameNode和SecondaryNameNode(面试开发重点)
nn和2nn的工作机制?2nn有什么作用?集群的故障处理、集群的安全模式
1、NameNode工作机制
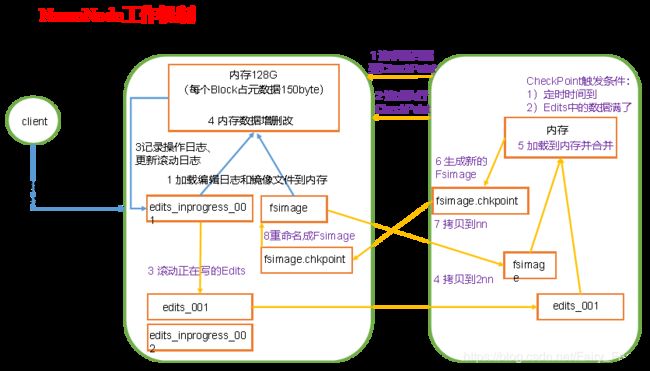
第一阶段:NameNode启动
·第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存
·客户端对元数据进行增删改的请求
·NameNode记录操作日志,更新滚动日志
·NameNode在内存中对元数据进行增删改
第二阶段:SecondaryNameNode工作
·Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果
·Secondary NameNode请求执行CheckPoint
·NameNode滚动正在写的Edits日志
·将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode
·Secondary NameNode加载编辑日志和镜像文件到内存,并合并
·生成新的镜像文件fsimage.chkpoint
·拷贝fsimage.chkpoint到NameNode
·NameNode将fsimage.chkpoint重新命名成fsimage
2、2nn作用
·2nn的作用就是帮助NameNode进行Edits和Fsimage的合并工作
3、集群的故障处理
NameNode故障后,可以采用如下两种方法恢复数据
(1).将SecondaryNameNode中数据拷贝到NameNode存储数据的目录
·kill -9 NameNode进程
·删除NameNode存储的数据:rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/*
·拷贝SecondaryNameNode中数据到原NameNode存储数据目录
·重新启动NameNode
(2)使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode 中数据拷贝到NameNode目录中
·修改hdfs-site.xml中的
dfs.namenode.checkpoint.period
120
dfs.namenode.name.dir
/opt/module/hadoop-2.7.2/data/tmp/dfs/name
·kill -9 NameNode进程
·删除NameNode存储的数据:rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/*
·如果SecondaryNameNode和NameNode不在一个主机节点上,需要将 SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并 删除in_use.lock文件
·导入检查点数据(等待一会ctrl+c结束掉):bin/hdfs namenode -importCheckpoint
·启动NameNode
4、集群的安全模式
·查看安全模式状态:bin/hdfs dfsadmin -safemode get
·进入安全模式状态:bin/hdfs dfsadmin -safemode enter
·离开安全模式状态:bin/hdfs dfsadmin -safemode leave
·等待安全模式状态:bin/hdfs dfsadmin -safemode wait
DataNode工作机制

·一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本 身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳
·DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报 所有的块信息
·心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数 据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心 跳,则认为该节点不可用
·集群运行中可以安全加入和退出一些机器
数据完整性
思考:如果电脑磁盘里面存储的数据是控制高铁信号灯的红灯信号(1)和绿灯信号(0),但是存储该数据的磁盘坏了,一直显示是绿灯,是否很危险?同理DataNode节点上的数据损坏了,却没有发现,是否也很危险,那么如何解决呢?
如下是DataNode节点保证数据完整性的方法。
1)当DataNode读取Block的时候,它会计算CheckSum。
2)如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏。
3)Client读取其他DataNode上的Block。
4)DataNode在其文件创建后周期验证CheckSum

判断DataNode的离线
A.DataNode进程死亡或者网络故障造成DataNode无法与NameNode通信
B.NameNode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长
C.HDFS默认的超时时长为10分钟+30秒
D.如果定义超时时间为TimeOut,则超时时长的计算公式为:
TimeOut = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval
默认dfs.namenode.heartbeat.recheck-interval 大小为5分钟, dfs.heartbeat.interval默认为3秒
如图:
添加新节点
.在hadoop01主机上再克隆一台hadoop04主机
.修改IP地址和主机名称
.删除原来HDFS文件系统留存的文件(data和logs)
.source一下配置文件
.直接启动DataNode,即可关联到集群
.在hadoop04上上传文件
.如果数据不均衡,可以用命令实现集群的再平衡
什么是黑名单?什么是白名单?如何退役旧节点?如何设置白名单?
.在黑名单上面的主机都会被强制退出
.添加到白名单的主机节点,都允许访问NameNode,不在白名单的主机节点,都会被 退出
.添加白名单,黑名单退役;不允许白名单和黑名单中同时出现一个主机名称
.设置白名单
·在NameNode的/opt/module/hadoop-2.7.2/etc/hadoop目录下创建dfs.hosts文件
添加主机名称(不添加hadoop04)
hadoop01
hadoop02
hadoop03
·在NameNode的hdfs-site.xml配置文件中增加dfs.hosts属性
dfs.hosts
/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts
·配置文件分发:myrsync hdfs-site.xml
·刷新NameNode:hdfs dfsadmin -refreshNodes
·更新ResourceManager节点:yarn rmadmin -refreshNodes
·在web浏览器上查看
·如果数据不均衡,可以用命令实现集群的再平衡
Datanode多目录配置
- DataNode也可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本
2.具体配置如下
hdfs-site.xml
dfs.datanode.data.dir
file:/// h a d o o p . t m p . d i r / d f s / d a t a 1 , f i l e : / / / {hadoop.tmp.dir}/dfs/data1,file:/// hadoop.tmp.dir/dfs/data1,file:///{hadoop.tmp.dir}/dfs/data2