《推荐系统开发实战》之基于标签的推荐算法介绍和案例实战开发
转载请注明出处:http://blog.csdn.net/gamer_gyt
博主微博:http://weibo.com/234654758
Github:https://github.com/thinkgamer
公众号:搜索与推荐Wiki
个人网站:http://thinkgamer.github.io
标签系统的传统用法是,在一些网站中,用户会为自己感兴趣的对象打上一些标签,如豆瓣、网易云音乐、Last.fm等。这些社会化标签即资源的分类工具,也是用户个人偏好的反映,因此社会化标签为推荐系统获得用户偏好提供了一个新的数据来源。之所以说“传统”,是因为这些标签是用户主观意愿的表达,是主动行为。但是,有些电商网站也会对用户或商品进行一些客观的打标,如对一个经常网购数码产品的用户打上一个“数码达人”的标签,以便后继给该用户推荐数码类商品。
标签系统的应用
推荐系统的目的是联系用户和物品,这种联系需要不同的“媒介”。例如:
- 相似用户(给用户推荐相似用户喜欢的物品),媒介是用户。
- 相似物品(给用户推荐他喜欢物品的相似物品),媒介是物品。
- 隐含的特征(根据用户的历史行为构造特征,进而预测对新物品的偏好程度),媒介是行为特征。
本章将介绍一种新的联系媒介——标签。工业界中的主流标签系统包含:
- Last.fm
- Delicious
- 豆瓣
- 网易云音乐
数据标注与关键词提取
关键词是指能够反映文本语料主题的词语或短语。在不同的业务场景中,词语和短语具有不同的意义。例如:
- 从电商网站商品标题中提取标签时,词语所传达的意义就比较突出。
- 从新闻类网站中生成新闻摘要时,短语所传达的意义就比较突出。
数据标注
数据标注即利用人工或AI(人工智能)技术对数据(文本、图像、用户或物品)进行标注。
标注有许多类型,如:
- 分类标注:即打标签,常用在图像、文本中。一般是指,从既定的标签中选择数据对应的标签,得到的结果是一个封闭的集合。
- 框框标注:常用在图像识别中,如有一张环路上的行车照片,从中框出所有的车辆。
- 区域标注:常见于自动驾驶中。例如从一张图片中标出公路对应的区域。
- 其他标注:除了上述常见的标注类型外,还有许多个性化需求。例如,自动摘要、用户或商品的标签(因为其中总有一些未知标签,当然也可以看成是多分类)。
数据标注的一般步骤为:
(1)确定标注标准:设置标注样例和模板(如标注颜色时对应的比色卡等)。对于模棱两可的数据,制定统一的处理方式。
(2)确定标注形式:标注形式一般由算法人员确定。例如,在垃圾问题识别中,垃圾问题标注为1,正常问题标注为0。
(3)确定标注方法:可以使用人工标注,也可以针对不同的标注类型采用相应的工具进行标注。
那么,数据标注与标签的对应关系是什么呢?
数据标注在推荐系统中的应用
关键词提取在推荐系统中的应用也十分广泛,主要用于用户物品召回(根据用户对关键词的行为偏好,召回相应关键词下的物品)和特征属性构造(对物品的属性进行补充)。
具体的案例这里不过多做介绍。
推荐系统中的关键词提取
关键词是指能够反映文本语料主题的词语或短语。在不同的业务场景中,词语和短语具有不同的意义。例如:
- 从电商网站商品标题中提取标签时,词语所传达的意义就比较突出。
- 从新闻类网站中生成新闻摘要时,短语所传达的意义就比较突出。
这里所介绍的关键提取和数据标注同样都是一个动作,都是为了得到一些标签或属性特征。
关键词提取从最终的结果反馈上来看可以分为两类:
- 关键词分配:给定一个指定的词库,选取和文本关联度最大的几个词作为该文本的关键词。
- 关键词提取:没有指定的词库,从文本中抽取代表性词作为该文本的关键词。
不管通过哪种方式生成,关键词都是对短文本所传达含义的抽取概述,都直接反映了短文本的所传达的属性或特征
标签的分类
在推荐系统中,不管是数据标注还是关键词提取,其目的都是得到用户或物品的标签。但是在不同场景下,标签的具体内容是不定的。例如,同样是分类标注,新闻的类别里可以有军事、科技等,但音乐的类别里就很少会涉及军事或科技了。
对于社会化标签在标识项目方面的功能,Golder和Huberman将其归纳为以下7种:
- 标识对象的内容。此类标签一般为名词,如“IBM”“音乐”“房产销售”等。
- 标识对象的类别。例如标识对象为“文章”“日志”“书籍”等。
- 标识对象的创建者或所有者。例如博客文章的作者署名、论文的作者署名等。
标识对象的品质和特征。例如“有趣”“幽默”等。
- 用户参考用到的标签。例如“myPhoto”“myFavorite”等。
- 分类提炼用的标签。用数字化标签对现有分类进一步细化,如一个人收藏的技术博客,按照难度等级分为“1”“2”“3”“4”等。
- 用于任务组织的标签。例如“to read”“IT blog”等。
当然以上7种类别标签是一个通用框架,在每一个具体的场景下会有不同的划分。
基于TF-IDF提取标题中的关键词
TF-IDF(Term Frequency–Inverse Document Frequency)是一种用于资讯检索与文本挖掘的常用加权技术。TF-IDF算法的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或短语具有很好的类别区分能力,适合用来分类。TF-IDF实际是TF*IDF。
那么TF-IDF的具体算法原理是什么?以及我们如何从商品标题中提取关键词呢?
基于标签的推荐系统
标签是用户描述、整理、分享网络内容的一种新的形式,同时也反映出用户自身的兴趣和态度。标签为创建用户兴趣模型提供了一种全新的途径。
本节将展开介绍基于标签的用户如何进行兴趣建模。
标签评分算法
用户对标签的认同度可以使用二元关系表示,如“喜欢”或“不喜欢”;也可以使用“连续数值”表示喜好程度。
二元表示方法简单明了,但精确度不够,在对标签喜好程度进行排序时,也无法进行区分。所以,这里选用“连续数值”来表达用户对标签的喜好程度。
为了计算用户对标签的喜好程度,需要将用户对物品的评分传递给这个物品所拥有的标签,传递的分值为物品与标签的相关度。
1.用户对标签的依赖程度
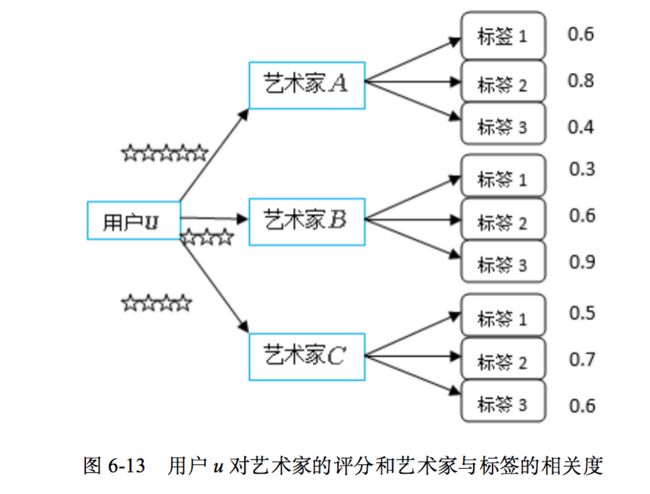
如图6-13所示,用户u对艺术家A的评分为5星,对艺术家B的评分为3星,对艺术家C的评分为4星。
艺术家A与标签1、2、3的相关度分别为:0.6,0.8,0.4;
艺术家B与标签1、2、3的相关度分别为:0.3,0.6,0.9;
艺术家C与标签1、2、3的相关度分别为:0.5,0.7,0.6。
对应的用户(u)对标签(t)的喜好程度计算公式为:

式中:
- rate(u,t)表示用户u对标签t的喜好程度。
- rate(u,i)表示用户u对艺术家i的评分。
- rel(i,t)表示艺术家i与标签t的相关度。
根据式(6.4)计算出用户u对标签1的喜好程度为:
(50.6+30.3+40.5)/(0.6+0.3+0.5)=4.21
同理可以计算出用户u对标签2的喜好程度为 4.10,对标签3的喜好程度为3.74。
2.优化用户对标签的喜好程度
如果一个用户的评分行为较少,就会导致预测结果存在误差。那么该如何改进呢?
标签评分算法改进
这里使用TF-IDF算法来计算每个标签的权重,用该权重来表达用户对标签的依赖程度。
TF-IDF算法在6.3.1节中进行了介绍,这里不再赘述。每个用户标记的标签对应的TF值的计算公式为:

式中:
- n(u,ti)表示用户u使用标签ti标记的次数。
- 分母部分表示用户u使用所有标签标记的次数和。
TF(u,t)表示用户u使用标签t标记的频率,即用户u对标签t的依赖程度。
优化用户对标签的依赖程度
在社会化标签的使用网站中存在“马太效应”,即热门标签由于被展示的次数较多而变得越来越热门,而冷门标签也会越来越冷门。大多数用户标注的标签都集中在一个很小的集合内,而大量长尾标签则较少有用户使用。
事实上,较冷门的标签才能更好地体现用户的个性和特点。为了抑制这种现象,更好地体现用户的个性化,这里使用逆向文件频率(IDF)来对那些热门标签进行数值惩罚。
每个用户标记的标签对应的IDF值的计算公式为:

- 分子表示所有用户对所有标签的标记计数和。
- 分母表示所有用户对标签t的标记计数和。
- IDF( u, t)表示t的热门程度,即一个标签被不同用户使用的概率。
对于一个标签而言,如果使用过它的用户数量很少,但某一个用户经常使用它,说明这个用户与这个标签的关系很紧密。
用户对标签的兴趣读
综合式(6.6)和式(6.7),用户对标签的依赖度为:
在6之前分析了用户对标签的主观喜好程度,本节分析了用户对标签的依赖程度,综合可以得到用户u对标签的兴趣度为:

标签基因
标签基因是GroupLens研究组的一个项目。
在社会化标签系统中,每个物品都可以被看作与其相关的标签的集合,rel(i, t)以从0(完全不相关)到1(完全正相关)的连续值衡量一个标签与一个物品的符合程度。
例如图6-13中:
- rel(艺术家A,标签1)=0.6;
- rel(艺术家A,标签2)=0.8;
- rel(艺术家A,标签3)=0.4。
采用标签基因可以为每个艺术家i计算出一个标签向量rel(i),其元素是i与T中所有标签的相关度。这里,rel( i)相当于以标签为基因描绘出了不同物品的基因图谱。形式化的表达如下:

例如,图6-13中,艺术家A的标签基因为:rel(艺术家A)=[0.6,0.8,0.4]。
选用标签基因来表示标签与物品的关系有以下三个原因:
(1)它提供了从0到1的连续数值;
(2)关系矩阵是稠密的,它定义了每个标签t∈ T与每个物品 i∈ I的相关度;
(3)它是基于真实数据构建的。
用户兴趣建模
根据训练数据,可以构建所有商品的标签基因矩阵Ti和用户最终对标签的兴趣度Tu,则用户对商品的可能喜好程度为:

式中:
- Tu:用户u对所有标签的兴趣度矩阵(1行m列,m为标签个数)。
- Ti^T:所有商品的标签基因矩阵Ti的转置矩阵(m行n列,m为标签个数,n为商品个数)。
- T(u,i):用户u对所有商品的喜好程度矩阵(1行n列,n为商品个数)。
最终从计算结果中选取前K个推荐给用户。
基于标签推荐算法实现艺术家推荐
利用标签推荐算法实现一个艺术家推荐系统,即,根据用户已经标记过的标签进行标签兴趣建模,进而为用户推荐喜好标签下最相关的艺术家。
这里使用Last.fm数据集中的数据作为基础数据,该数据集在3.3节有相关的介绍。该实例的具体实现思路如下:
(1)加载并准备数据;
(2)计算每个用户对应的标签基因;
(3)计算用户最终对每个标签的兴趣度;
(4)进行艺术家推荐和效果评估。
注:《推荐系统开发实战》是小编近期要上的一本图书,预计本月(7月末)可在京东,当当上线,感兴趣的朋友可以进行关注!

