Pandas学习 - 索引
写在前面
今天这部分我们要学习一下索引的操作。申明一下这个不是我自己编写的噢,是参加了Datawhale的组队学习,其中的成员GYH大神编写的joyful-pandas,可以取github上找到内容!(PS发现大神是同校的小学弟哈哈哈,真的很优秀,自己还要慢慢学习~)
如果有感兴趣的小伙伴可以github自取。
一、单级索引
1. loc方法、iloc方法、[]操作符
一般而言,最常用的索引方法就是这三类
- iloc表示位置索引(i表示index)
- loc表示标签索引
- []也具有很大的便利性
(a)loc方法
trick one: 所有在loc中使用的切片全部包含右端点的,这一点和我们之前的右边不到不一样
①单行索引
# 标签索引为 1103
# 也就是说如果行标签为字符型变量,那么df.loc['a']
df.loc[1103]
②多行索引
df.loc[[1102, 2304]]
df.loc[1304:]
df.loc[2402::-1] # 取从后向前的元素(从2402往前)
trick two: 类似小用法
import numpy as np
a=np.random.rand(5)
print(a)
[ 0.64061262 0.8451399 0.965673 0.89256687 0.48518743]
print(a[-1]) ## 取最后一个元素
[0.48518743]
print(a[:-1]) ## 除了最后一个取全部
[ 0.64061262 0.8451399 0.965673 0.89256687]
print(a[::-1]) ## 取从后向前(相反)的元素
[ 0.48518743 0.89256687 0.965673 0.8451399 0.64061262]
print(a[2::-1]) ## 取从下标为2的元素往前读取
[ 0.965673 0.8451399 0.64061262]
对于上面两种来说,默认是取出所有变量的数据的。
③单列索引
df.loc[:,'Height']
④多列索引
df.loc[:, ['Height','Math']] ## Height和Math两列
df.loc[:, 'Height':'Math'] ## Height到Math这三列
写出对应的变量名即可,记得要用[]括起来。
⑤联合索引
df.loc[1102:2401:3,'Height':'Math'].head()
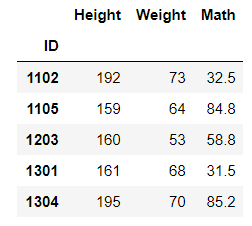
这个索引的意思就是指首先按标签索引,1102到2401为区间,3为步长取数,其次取出Height到Math的这三列数据。
⑥函数式索引
# loc中使用的函数,传入参数就是前面的df
df.loc[lambda x:x['Gender']=='M'].head()
主要就是运用lambda函数对所有的记录进行遍历,找到符合条件的记录。
⑦布尔索引
# 语句一
df.loc[df['Address'].isin(['street_7','street_4'])].head()
# 语句二
## 这里是这样一个逻辑,首先遍历Address找到它的值,然后用i[-1]看是4还是7
df.loc[[True if i[-1]=='4' or i[-1]=='7' else False for i in df['Address'].values]].head()
(b)iloc方法
trick three: 注意与loc不同,切片右端点不包含
①单行索引
# 行位置为3的,也就是说从0开始,第四行
df.iloc[3]
②多行索引
# 第四行到第五行的记录
df.iloc[3:5]
③单列索引
df.iloc[:, 3].head()

这里我们看到都是按位置索引,位置为3,其实是第四列
④多列索引
# 这里的::-2是指所有列,然后步长为2,反向读取
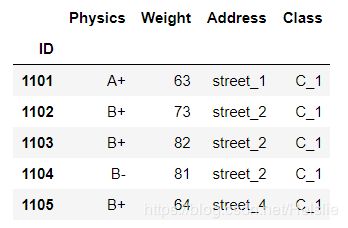
df.iloc[:,7::-2].head()
df.iloc[:,7::-1].head()
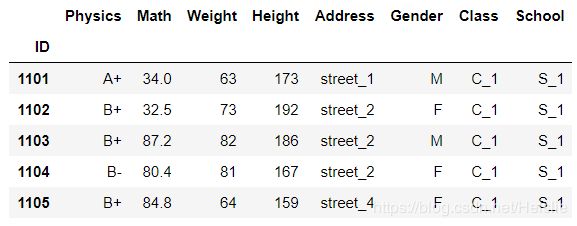
⑤混合索引
df.iloc[3::4,7::-2]
⑥函数式索引
df.iloc[lambda x:[3]]
这个也是就是取位置为3的记录,即第四行
trick four: 由上所述,iloc中接收的参数只能为整数或整数列表,不能使用布尔索引
(c) []操作符
trick five: 如果不想陷入困境,请不要在行索引为浮点时使用[]操作符,因为在Series中的浮点[]并不是进行位置比较,而是值比较,非常特殊
(c.1)Series的[]操作
①单元素索引
# 使用索引标签
s = pd.Series(df['Math'], index=df.index)
# 找出索引标签为1101的Math值
s[1101]
索引标签的使用同前面
②多行索引
m = pd.Series(df['Height'], index=df.index)
m[2402::-1].head()

③函数式索引
s[lambda x: x.index[16::-6]]
# 注意使用lambda函数时,直接切片(如:s[lambda x: 16::-6])就报错,此时使用的不是绝对位置切片,而是元素切片,非常易错
# 注意是x.index
④布尔索引
s[s>80]
# 指值大于80的部分
(c.2)DataFrame的[]操作
①单行索引
df[1:2]
# 这里非常容易写成df['label'],会报错
# 用了标签位置的切片
# 如果想要获得某一个元素,可用如下get_loc方法:
row = df.index.get_loc(1102)
df[row:row+1]

②多行索引
# 用切片,如果是选取指定的某几行,推荐使用loc,否则很可能报错
df[3:5]
③单列索引
df['School'].head()
④多列索引
df[['School','Math']].head()
⑤函数式索引
df[lambda x:['Math','Physics']].head()
⑥布尔索引
df[df['Gender']=='F'].head()
trick six: 一般来说,[]操作符常用于列选择或布尔选择,尽量避免行的选择
2. 布尔索引
(a)布尔符号:’&’,’|’,’~’:分别代表和and,或or,取反not
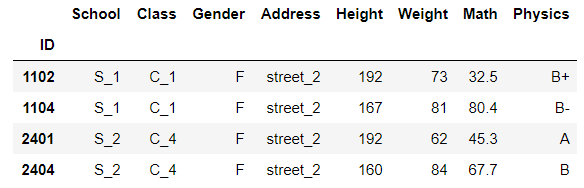
# 性别为F且地址为2号街
df[(df['Gender']=='F')&(df['Address']=='street_2')]
# 数学成绩大于85或者地址为7号街
df[(df['Math']>85)|(df['Address']=='street_7')]
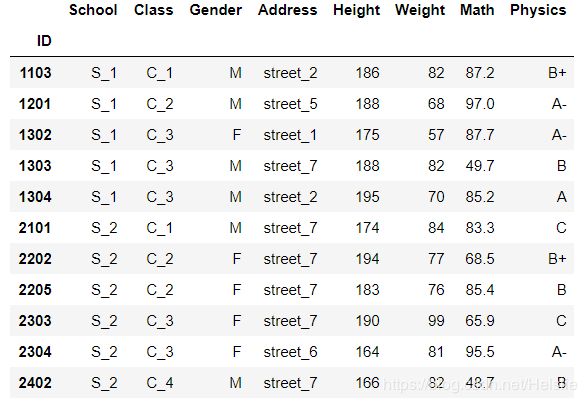
# 数学成绩既不大于75地址也不在1号街
df[~((df['Math']>75)|(df['Address']=='street_1'))].head()
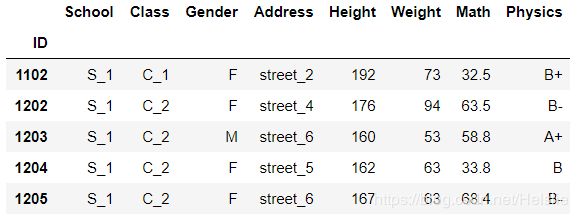
自己写一个例子!
# 数学成绩在60~90之间并且物理等级为A及以上
df[((df['Math']>=60)&(df['Math']<=90))&((df['Physics']=='A')|(df['Physics']=='A+'))]
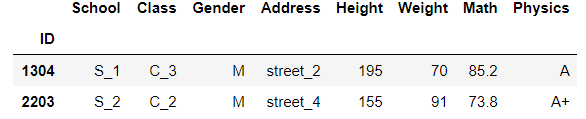
loc和[]中相应位置都能使用布尔列表选择:
df.loc[df['Math']>60,(df[:8]['Address']=='street_6').values].head()
# 如果不加values就会索引对齐发生错误,Pandas中的索引对齐是一个重要特征,很多时候非常使用
# 但是若不加以留意,就会埋下隐患
trick seven: loc的逗号两边可以是单个元素、元素列表、布尔列表或者函数就可以,四选一,逗号前面是行,逗号后面是列。
(b) isin方法
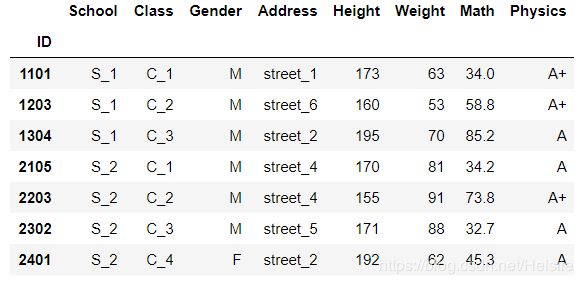
# 学校为S_1、S_2且物理等级在A及以上
df[(df['School'].isin(['S_1','S_2']))&(df['Physics'].isin(['A','A+']))]
# 上面也可以用字典方式写
# all与&的思路是类似
# 其中的1代表按照跨列方向判断是否全为True,类似axis=1
df[df[['School','Physics']].isin({'School':['S_1','S_2'],'Physics':['A','A+']}).all(1)]
3. 快速标量索引
当只需要取一个元素时,at和iat方法能够提供更快的实现
display(df.at[1101,'School'])
display(df.loc[1101,'School'])
display(df.iat[0,0])
display(df.iloc[0,0])
#可尝试去掉注释对比时间
%timeit df.at[1101,'School']
%timeit df.loc[1101,'School']
%timeit df.iat[0,0]
%timeit df.iloc[0,0]

at和iat是比loc和iloc更快的
4. 区间索引
(a)利用interval_range方法
pd.interval_range(start=0,end=5)
# closed参数可选'left''right''both''neither',默认左开右闭

pd.interval_range(start=0,periods=8,freq=5)
# periods参数控制区间个数,freq控制步长
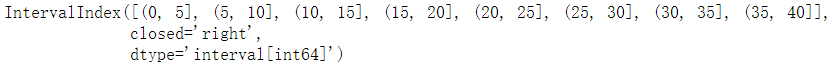
(b)利用cut将数值列转为区间为元素的分类变量,例如统计数学成绩的区间情况
math_interval = pd.cut(df['Math'],bins=[0,40,60,80,100])
# 注意,如果没有类型转换,此时并不是区间类型,而是category类型
math_interval.head()

(c)区间索引的选取
# 包含该值就会被选中
df_i.loc[65].head()
df_i.loc[[65,90]].head()
如果想要选取某个区间,先要把分类变量转为区间变量,再使用overlap方法:
df_i[df_i.index.astype('interval').overlaps(pd.Interval(70, 85))].head()
二、多级索引
1. 创建多级索引
如一级索引和二级索引
(a)通过from_tuple或from_arrays
①直接创建元组
# tuples即多级索引标签
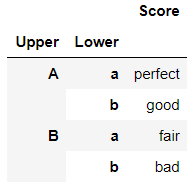
tuples = [('A','a'),('A','b'),('B','a'),('B','b')]
mul_index = pd.MultiIndex.from_tuples(tuples, names=('Upper', 'Lower'))
mul_index

pd.DataFrame({'Score':['perfect','good','fair','bad']},index=mul_index)
② 利用zip创建元组
L1 = list('AABB')
L2 = list('abab')
tuples = list(zip(L1,L2))
# 区别就在于创建元组的部分,后续操作同
③ 通过Array创建
arrays = [['A','a'],['A','b'],['B','a'],['B','b']]
mul_index = pd.MultiIndex.from_tuples(arrays, names=('Upper', 'Lower'))
pd.DataFrame({'Score':['perfect','good','fair','bad']},index=mul_index)
(b)通过from_product
L1 = ['A','B']
L2 = ['a','b']
pd.MultiIndex.from_product([L1,L2],names=('Upper', 'Lower'))
# 两两相乘
(c)指定df中的列创建(set_index方法)
# 即顺序即为级别顺序
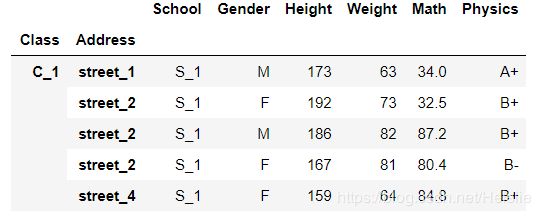
df_using_mul = df.set_index(['Class','Address'])
df_using_mul.head()
df_using_mul = df.set_index(['Address','Class'])
df_using_mul.head()
2. 多层索引切片
我们用上面的数据
(a)一般切片
# 注意要对索引进行排序
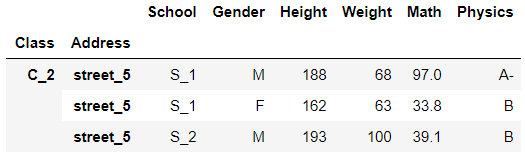
# 多级索引切片有两个标签定位
df_using_mul.sort_index().loc['C_2','street_5']
(b)第一类特殊情况:由元组构成列表
df_using_mul.sort_index().loc[[('C_2','street_7'),('C_3','street_2')]]
# 表示选出某几个元素,精确到最内层索引
(c)第二类特殊情况:由列表构成元组
df_using_mul.sort_index().loc[(['C_2','C_3'],['street_4','street_7']),:]
#选出第一层在‘C_2’和'C_3'中且第二层在'street_4'和'street_7'中的行
3. 多层索引中的slice对象
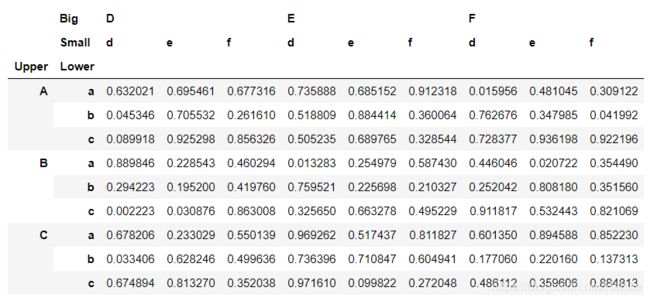
L1, L2 = ['A','B','C'],['a','b','c']
mul_index1 = pd.MultiIndex.from_product([L1,L2],names=('Upper', 'Lower'))
L3, L4 = ['D','E','F'],['d','e','f']
mul_index2 = pd.MultiIndex.from_product([L3,L4],names=('Big', 'Small'))
df_s = pd.DataFrame(np.random.rand(9,9),index=mul_index1,columns=mul_index2)
df_s
这个意思就是行索引和列索引
4. 索引层的交换
(a)swaplevel方法(两层交换)
df_using_mul.swaplevel(i=1,j=0,axis=0).sort_index().head()
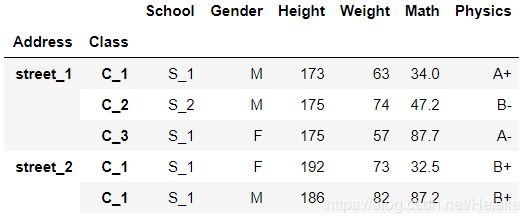
(b)reorder_levels方法(多层交换)
# []中的数字是指之后更新的顺序
df_muls.reorder_levels([2,0,1],axis=0).sort_index().head()
# 如果索引有name,可以直接使用name
df_muls.reorder_levels(['Address','School','Class'],axis=0).sort_index().head()
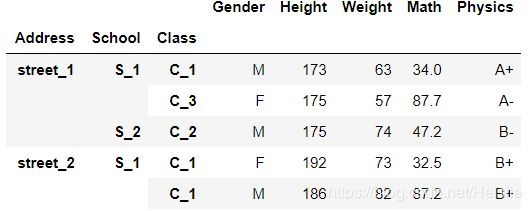
注意这里的axis=0是提醒我们后面的记录是跨行改变
三、索引设定
1. index_col参数
index_col是read_csv中的一个参数,而不是某一个方法。即直接在read_csv时就设定好。
2. reindex和reindex_like
# 设定新index,可能会出现nan值因为没有这个index
df.reindex(index=[1101,1203,1206,2402])
# 设定列,也可能会出现nan值因为没有这个字段
df.reindex(columns=['Height','Gender','Average']).head()
trick eight: 可以选择缺失值的填充方法:fill_value和method(bfill/ffill/nearest),其中method参数必须索引单调
df.reindex(index=[1101,1203,1206,2402],method='bfill')
# bfill表示用所在索引1206的后一个有效行填充,ffill为前一个有效行,nearest是指最近的
df.reindex(index=[1101,1203,1206,2402],method='nearest')
# 数值上1205比1301更接近1206,因此用前者填充
reindex_like的作用为生成一个横纵索引完全与参数列表一致的DataFrame,数据使用被调用的表
df.reindex_like(df[0:5][['Weight','Height']])
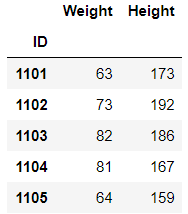
3. set_index和reset_index
首先是set_index
第一个作用上面已经说过,除了作为参数也可以作为方法
df.set_index('Class').head()
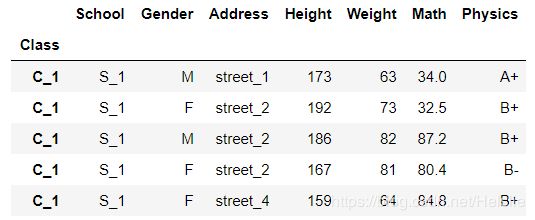
利用append参数可以将当前索引维持不变
# 这句话意思就是在当前索引基础上增加一个索引Class
df.set_index('Class',append=True).head()
当使用与表长相同的列作为索引(需要先转化为Series,否则报错)
df.set_index(pd.Series(range(df.shape[0]))).head()
# 可以直接添加多级索引
df.set_index([pd.Series(range(df.shape[0])),pd.Series(np.ones(df.shape[0]))]).head()
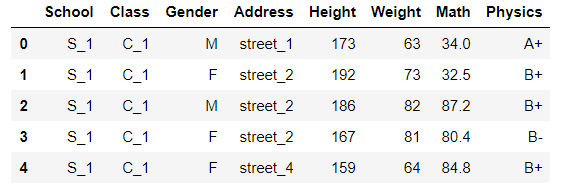
其次是reset_index
默认状态直接恢复到自然数索引
df.reset_index().head()
用level参数指定哪一层被reset,用col_level参数指定set到哪一层
以这个数据集为例:
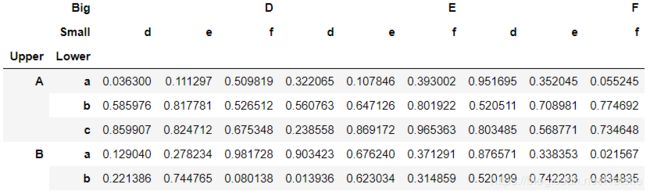
df_temp1 = df_temp.reset_index(level=1,col_level=1)
df_temp1.head()
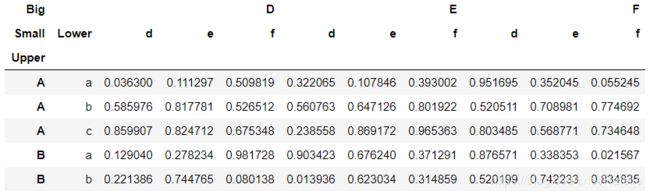
4. rename_axis和rename
# rename_axis是针对多级索引的方法
# 作用是修改某一层的索引名,而不是索引标签
df_temp.rename_axis(index={'Lower':'LowerLower'},columns={'Big':'BigBig'})
# rename方法用于修改列或者行索引标签,而不是索引名
df_temp.rename(index={'A':'T'},columns={'e':'changed_e'}).head()
四、常用索引型函数
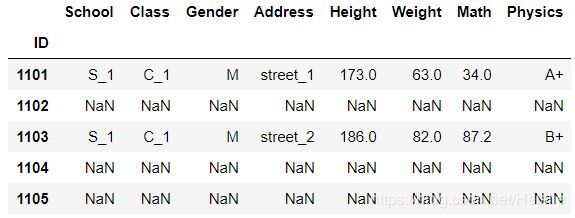
1. where函数
df.where(df['Gender']=='M').head()
# 不满足条件的行全部被设置为NaN
trick nine: 所以可以进行筛选,不符合条件的变成nan值之后,再dropna
df.where(df['Gender']=='M').dropna().head()

也可以进行填充,逗号后面即为填充的值
df.where(df['Gender']=='M',np.random.rand(df.shape[0],df.shape[1])).head()
2. mask函数
mask函数与where功能上相反,其余完全一致,即对条件为True的单元进行填充
3. query函数
query函数中的布尔表达式中,下面的符号都是合法的:行列索引名、字符串、and/not/or/&/|/~/not in/in/==/!=、四则运算符
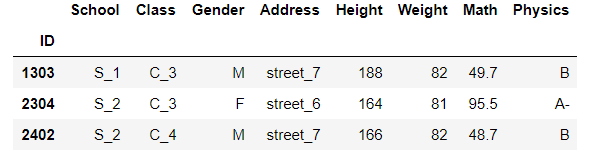
df.query('(Address in ["street_6","street_7"])&(Weight>(70+10))&(ID in [1303,2304,2402])')
五、重复元素处理
1. duplicated方法
# 返回了是否重复的布尔列表
df.duplicated('Class')
# 可选参数keep默认为first,即首次出现设为不重复,若为last,则最后一次设为不重复
df.duplicated('Class',keep='last')
# 若为False,则所有重复项为True
df.duplicated('Class',keep=False)
2. drop_duplicates方法
# 剔除重复项
df.drop_duplicates('Class')
df.drop_duplicates('Class',keep='last')
# 在传入多列时等价于将多列共同视作一个多级索引,比较重复项
df.drop_duplicates(['School','Class'])
六、抽样函数(即sample函数)
sample函数中有很多参数,下面进行一一解释
# n为样本量
df.sample(n=5)
# frac为抽样比
df.sample(frac=0.05)
# replace为是否放回,True即可重复
df.sample(n=df.shape[0],replace=True)
# axis为抽样维度,默认为0,即抽行
df.sample(n=3,axis=1) # 指抽三个列
# weights为样本权重,自动归一化
df.sample(n=3,weights=np.random.rand(df.shape[0]))
#以某一列为权重,这在抽样理论中很常见
#抽到的概率与Math数值成正比
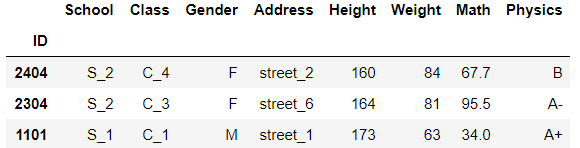
df.sample(n=3,weights=df['Math'])
七、问题与练习
1.问题
【问题一】 如何更改列或行的顺序?如何交换奇偶行(列)的顺序?
【问题二】 如果要选出DataFrame的某个子集,请给出尽可能多的方法实现。
【问题三】 query函数比其他索引方法的速度更慢吗?在什么场合使用什么索引最高效?
【问题四】 单级索引能使用Slice对象吗?能的话怎么使用,请给出一个例子。
【问题五】 如何快速找出某一列的缺失值所在索引?
【问题六】 索引设定中的所有方法分别适用于哪些场合?怎么直接把某个DataFrame的索引换成任意给定同长度的索引?
【问题七】 多级索引有什么适用场合?
【问题八】 对于多层索引,怎么对内层进行条件筛选?
【问题九】 什么时候需要重复元素处理?
2.练习
【练习一】 现有一份关于UFO的数据集,请解决下列问题:
(a)在所有被观测时间超过60s的时间中,哪个形状最多?
df = pd.read_csv('data/UFO.csv')
# 这个列名要改一下,我试过原名会报错
df.rename(columns={'duration (seconds)':'duration'},inplace=True)
# 注意到这里的秒是字符串型,转换形式
df['duration'].astype('float')
# 用query函数进行布尔的筛选
## 首先找到观测时间超过60s的shape值
## 然后进行计数
## 最后找到最大,用index[0]
df.query('duration > 60')['shape'].value_counts().index[0]
![]()
trick ten: inplace参数的理解
修改一个对象时:
- inplace=True:不创建新的对象,直接对原始对象进行修改;
- inplace=False:对数据进行修改,创建并返回新的对象承载其修改结果。
(b)对经纬度进行划分:-180°至180°以30°为一个经度划分,-90°至90°以18°为一个维度划分,请问哪个区域中报告的UFO事件数量最多?
# 划分区域并tolist
bins_long = np.linspace(-180,180,13).tolist()
bins_la = np.linspace(-90,90,11).tolist()
# 根据划分的区域将每个值有一个分区变量
cuts_long = pd.cut(df['longitude'],bins=bins_long)
df['cuts_long'] = cuts_long
cuts_la = pd.cut(df['latitude'],bins=bins_la)
df['cuts_la'] = cuts_la
# 根据分区变量进行二级索引计数
df.set_index(['cuts_long','cuts_la']).index.value_counts().head()

【练习二】 现有一份关于口袋妖怪的数据集,请解决下列问题:
(a)双属性的Pokemon占总体比例的多少?
df = pd.read_csv('data/Pokemon.csv')
# 双属性就是指两个属性都不为nan值
# 个数/行数
df['Type 2'].count()/df.shape[0]
(b)在所有种族值(Total)不小于580的Pokemon中,非神兽(Legendary=False)的比例为多少?
# 如果value_counts中没有参数那么计算的是个数
# normalize=True即归一化
df.query('Total >= 580')['Legendary'].value_counts(normalize=True)

(c)在第一属性为格斗系(Fighting)的Pokemon中,物攻排名前三高的是哪些?
# 首先根据[]来找出第一属性为格斗系的
# 然后用sort_values来排名Attack,参数为降序
# 用iloc找到前三行
df[df['Type 1']=='Fighting'].sort_values(by='Attack',ascending=False).iloc[:3]
(d)请问六项种族指标(HP、物攻、特攻、物防、特防、速度)极差的均值最大的是哪个属性(只考虑第一属性,且均值是对属性而言)?
df['range'] = df.iloc[:,5:11].max(axis=1)-df.iloc[:,5:11].min(axis=1)
attribute = df[['Type 1','range']].set_index('Type 1')
max_range = 0
result = ''
for i in attribute.index.unique():
temp = attribute.loc[i,:].mean()
if temp.values[0] > max_range:
max_range = temp.values[0]
result = i
result
(e)哪个属性(只考虑第一属性)神兽占总Pokemon的比例最高?该属性神兽的种族值也是最高的吗?
df.query('Legendary == True')['Type 1'].value_counts(normalize=True).index[0]
attribute = df.query('Legendary == True')[['Type 1','Total']].set_index('Type 1')
max_value = 0
result = ''
for i in attribute.index.unique()[:-1]:
temp = attribute.loc[i,:].mean()
if temp[0] > max_value:
max_value = temp[0]
result = i
result
最后这两题应该还需要再研究一下,不太明白。