python3爬虫系列13之find_all爬虫高考分数线并绘制分析图(普通版)
python3爬虫系列13之find_all爬虫高考分数线并绘制分析图(普通版)
1. 前言
之前一篇是
python3爬虫系列10之使用pymysql+pyecharts读取Mysql数据可视化分析,里面采用了pyecharts来进行数据绘图。
在上一篇文章中,从新介绍了一下
python3爬虫系列12之lxml+xpath和BeautifulSoup+css selector不同方式tiobe网站爬取,这样我们以后在爬虫中,就可以采用搭配的方式。
说的是 使用 lxml+xpath和BeautifulSoup+css selector 不同方式的都可以对网站的信息进行提取。
2. BeautifulSoup的 find(),find_all(),findAll()区别
那么今天说的内容是关于BeautifulSoup的 find(),find_all() 方法的使用。
区别:find_all()方法的返回的值是包含元素的列表,而 find()方法直接返回的是一个结果。
值得一提的是:有人会在一些老代码中看到find_all和findAll。
说明:
find_all() 与 findAll() 方法的功能相同。
findAll = find_all # Bs3以上
来源:

在BeautifulSoup版本4中,两者方法已完全相同。在混合大小写版本(findAll,findAllNext,nextSibling等)已全部更名。
在新代码中,您应该使用小写版本,例如find_all。
好了,废话少说,搞事情了。

3. BeautifulSoup爬虫高考分数线并绘制分析图
今天说这个,是一个关于高考网的爬虫,历年高考录取分数线图的绘制。
目标网站:http://www.gaokao.com
全国 31 个省份的高考录取分数线,分别是文理科的一本和二本数据。
网页分析:
目标地址:
http://www.gaokao.com/sichuan/fsx/
http://www.gaokao.com/beijing/fsx/
http://www.gaokao.com/hunan/fsx/
由上诉地址可以看出来,地区分布主要是 http://www.gaokao.com/xxxxx/fsx/,
可以看到地址是省份的拼音缩写。
由此我们可以构造url为:
url = ‘http://www.gaokao.com/’ + diquPY + ‘/fsx/’
其中diquPY 为省份的拼音。
其次,在看我们爬去的内容区域:
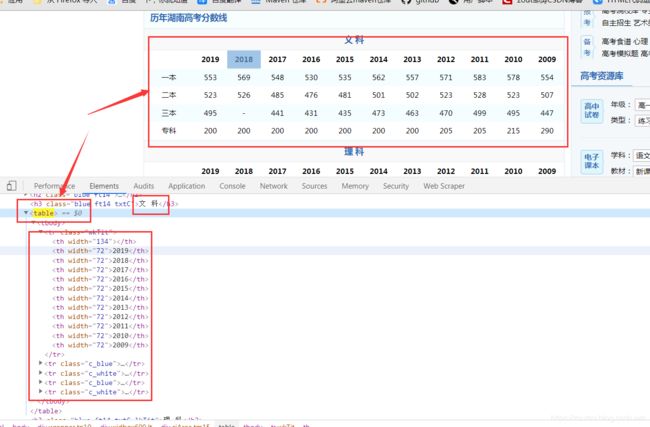
由table标签即可查询到。
所以
爬虫代码:
爬虫代码如下:
#!/usr/bin/python3
import requests
from bs4 import BeautifulSoup
import pypinyin # 与xpinyin相比,pypinyin更强大。
import time
from pyecharts.globals import ThemeType
from pyecharts import options as opts
from pyecharts.charts import Bar
# 爬虫目标地址:http://www.gaokao.com/jiangsu/fsx/
# 有反爬,添加一下header
headers = {
'User - Agent': 'Mozilla / 5.0(Windows NT 6.1;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 73.0.3683.103Safari / 537.36'
}
# 爬虫请求
def yanz(diquname):
diquPY = ''
for i in pypinyin.pinyin(diquname, style=pypinyin.NORMAL):
diquPY += ''.join(i)
#print('汉字转拼音:',diquPY)
url = 'http://www.gaokao.com/' + diquPY + '/fsx/'
print(url)
response = requests.get(url,headers=headers)
if response.status_code == 200:
response.encoding = 'GBK'
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# # 地区只要a标签的href属性
# diqu = soup.find(class_='area_box')
# zzr = diqu.find_all('a')
# for item in zzr:
# diquname = item.text
# # diquhref = item.get('href')
# print(diquname)
print('正在查询历年分数线:')
wenke, nianfen = wenkechax(soup) # 文科查询
like = likechax(soup) # 理科查询
keshihua(diquname,like,wenke,nianfen)
return wenke,like
else:
print('输入地区错误或请求失败:', response.status_code)
html = None
return None
# 文科
def wenkechax(soup):
wenke=[]
nianfen =[]
# div1 = soup.select('body > div.wrapper.tp10 > div.widbox690.lt > div.cjArea.tm15')
# h2 = soup.select('div.cjArea.tm15 > h2 > a')[0].text
# h3 = soup.select('div.cjArea.tm15 > h3 ')[0].text
# print(h3)
# table
tables = soup.findAll('table')
tab = tables[0] # 要第一个table
for tr in tab.findAll('tr'):
for th in tr.findAll('th'): # 年份
if th.text !='':
#print(th.text)
nianfen.append(th.text)
for td in tr.findAll("td"): # 分数
tdNum = (td.text).strip() # str对象-除去不规则符号\r\n\t\t\t\t,不除也可以。
#print(tdNum) # 所有的批次都获取到了。
wenke.append(tdNum)
#print(wenke,type(wenke),len(wenke))
# 为了好看,只要一二本数据。
print('年份',nianfen)
print('文科',wenke[:12])
print('文科',wenke[12:24])
return wenke,nianfen
# 理科
def likechax(soup):
like = [] # 理科
nianfen = [] # 年份
# h4 = soup.select('div.cjArea.tm15 > h3.blue.ft14.txtC.lkTit ')[0].text
# print(h4)
# table
tables = soup.findAll('table')
tab = tables[1] # 要第二个table
for tr in tab.findAll('tr'):
for th in tr.findAll('th'): # 年份
if th.text !='':
#print(th.text)
nianfen.append(th.text)
for td in tr.findAll('td'): # 分数
#print(td.text)
tdNum = (td.text).strip() # str对象-除去不规则符号\r\n\t\t\t\t,不除也可以。
like.append(tdNum)
# 为了好看,只要一二本数据。
print('年份', nianfen)
print('理科', like[:12])
print('理科', like[12:24])
return like
# 历年高考录取分数线绘图
def keshihua(diquname,like,wenke,nianfen):
print(like)
# 为了好看,只要一二本数据。
wenkeYb = wenke[:12]
wenkeEb = wenke[12:24]
likeYb = like[:12]
likeEb = like[12:24]
# 绘图
c = Bar(init_opts=opts.InitOpts(theme=ThemeType.SHINE))
c.add_xaxis([list(z) for z in zip(nianfen)]) # 年份-记住怎么读取出来的!
c.add_yaxis('文科一本',[wenkeYb[i] for i in range(1,len(wenkeYb))]) # 去掉'一本'
c.add_yaxis('理科一本', [likeYb[i] for i in range(1,len(likeYb))])
c.add_yaxis('文科二本', [wenkeEb[i] for i in range(1,len(wenkeEb))])
c.add_yaxis('理科二本',[likeEb[i] for i in range(1,len(likeEb))])
c.set_global_opts(title_opts=opts.TitleOpts(title=diquname +'历年高考录取分数线图',subtitle='2009-2019年'))
c.render(diquname +'历年高考录取分数线图.html')
print(diquname + '历年高考录取分数线图绘制完成。')
if __name__ == '__main__':
start = time.time()
#diquname = '湖南'
diquname = input('请输入查询的省份:')
yanz(diquname)
print('爬虫已完毕,程序结束。')
print("用时: {}".format(time.time() - start))
代码的相关解释已经写在了程序中,主要理解一下find_all()方法的使用。
输入自己要查的省份。
运行一下,效果:

这里注意一下,我们用了 12.445056438446045秒的时间来爬完数据的。可以看到速度还是比较低的。数据量不大都这么慢
需要哪个省份就输入哪个即可自动生成分析图:
自动生成-分析图:


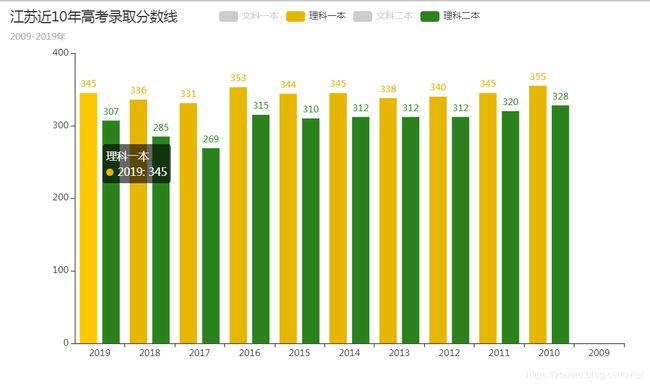
江苏09年理科没有数据。

至于分析,需要哪个省就自己去看吧,可以看出湖南最高的文科录取分数线在2011年出现,583分。
报错解决
- 转义字符的去除:
在提取的数据的时候,有一些网页会出现很多转义字符。
‘\r\n\t\t\t\t528’, ‘\r\n\t\t\t\t523’, ‘\r\n\t\t\t\t507’
除去这种符号:

解决方法:
tdNum = (td.text).strip() # str对象-除去不规则符号\r\n\t\t\t\t。

-
名字转拼音:
将汉字转化成对应的拼音。
diquname = ‘四川’
import pypinyin # 与xpinyin相比,pypinyin更强大。
diquPY = ''
for i in pypinyin.pinyin(diquname, style=pypinyin.NORMAL):
diquPY += ''.join(i)
print('汉字转拼音:',diquPY)
就会转为:

好了,上诉到此结束,实际上本文的重点在于爬虫速度,下一篇会以本文基础采用多进程的方式来优化速度。
参考:
python3爬虫系列04之网页解析器:BeautifulSoup库的解释