开源数据分析挖掘系统
1KNIME一款强大开源的数据挖掘软件平台
通过数据挖掘可以从大量有序或者杂乱无章的数据中发现潜在的规律,甚至通过训练学习还能通过已知的数据预测未来的发展变化,今天就给大家推荐一款强大开源的数据挖掘软件平台:KNIME数据分析平台。其提供了自建服务器版和云版两种支持方式,其基本的工作流程如下,先读取要分析的数据,然后对其中的一些数据进行转换,然后分析出其中的规律,最后部署到平台,KNIME数据分析平台的最新版本是3.5.
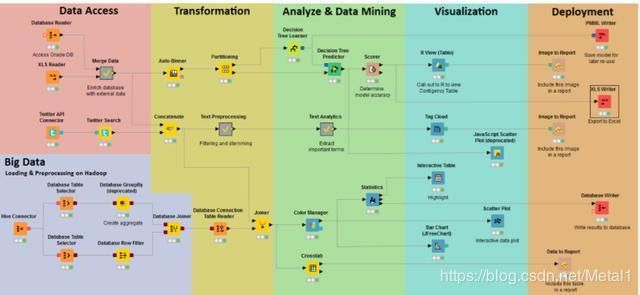
其下载地址为:https://www.knime.com/knime-analytics-platform
KNIME数据分析平台最引人注目的是其强大的数据和工具的集成能力:
容易与第三方的大数据框架集成其通过大数据组件的扩展(Big Data Extension)能够方便的和Apache的Hadoop和Spark等大数据框架集成在一起,非常的容易使用。
兼容多种数据形式其不但支持纯文本,数据库,文档,图像,网络,甚至还支持基于Hadoop的数据格式兼容多种数据分析工具和语言其不但集成了很多的工具,包括支持R语言和Python语言的脚本,从而让专家经验被复用强大的可视化功能提供了易于使用的图形化接口,能够把分析结果通过生动形象的图形展示给用户。最最最重要的是其提供了1500多个模块,且现在还在不断的增长,通过这些模块:
支持主要的文件格式和数据库本地和数据库数据的调整和转换支持主流的数据格式:XML, JSON, 图形, 文档等非常容易与第三方的机器学习库集成使用,比如H2O,Keras,Scikit-Learn等提供基于Web报告或者数据视图的展示支持动态工作流的设计
2、国内涌现出了不少数据分析平台产品,魔镜
3、数据观。
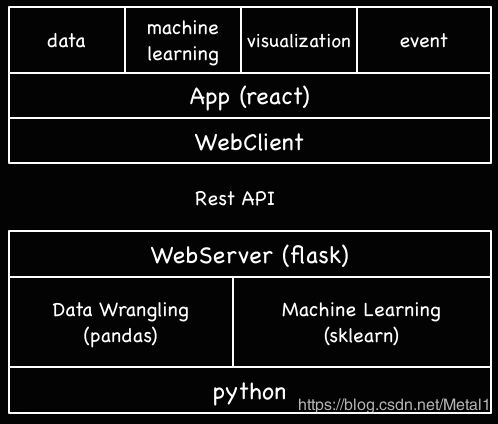
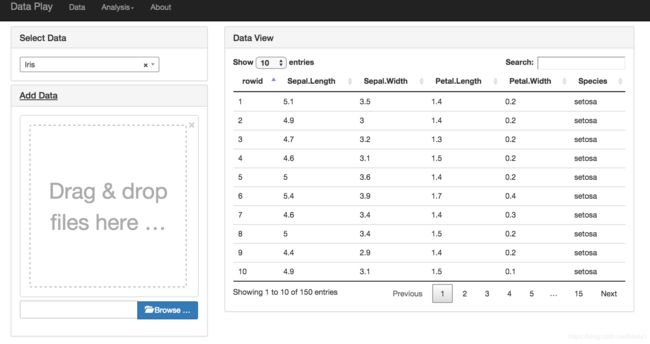
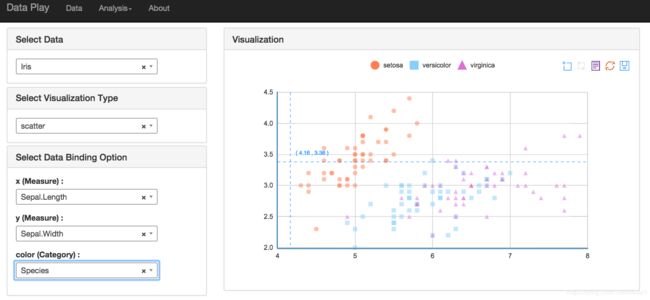
4、dataplay2
地址:https://blog.csdn.net/braveswang/article/details/79681297
代码在这里 https://github.com/gangtao/dataplay2
1、WEKA
WEKA 原生的非 Java 版本主要是为了分析农业领域数据而开发的。该工具基于 Java 版本,是非常复杂的,并且应用在许多不同的应用中,包括数据分析以及预测建模的可视化和算法。与 RapidMiner 相比优势在于,它在 GNU 通用公共许可证下是免费的,因为用户可以按照自己的喜好选择自定义。
WEKA 支持多种标准数据挖掘任务,包括数据预处理、收集、分类、回归分析、可视化和特征选取。添加序列建模后,WEKA 将会变得更强大,但目前不包括在内。
WEKA Knowledge Flow 具有以下功能特点:
(1) 可移植性。WEKA基于Java 编程语言进行操作,从而几乎任何现代计算平台都可以运行。
(2) 支持标准的机器学习任务,包括数据预处理、聚类、分类、回归以及特征选择。各方面任务特点如下:
ü 数据预处理任务从数据库、CSV 文件等输入数据,并使用过滤算法对数据进行预处理。这些过滤器可用于转换数据(例如连续型数值属性变成离散型),从而根据具体的标准删除实例和属性。
ü 关联分析任务提供了不同的关联规则学习算法,譬如Apriori或FP-growth等,方便找出数据属性之间所有重要的关联关系。
ü 分类任务提供了贝叶斯、决策树、随机森林等不同的分类器进行数据分类学习,此外,使用户应用分类和回归算法的结果数据集,去评估预测模型产生结果的准确性,并可视化错误预测、ROC 曲线和模型本身(如果模型是适合可视化的,如贝叶斯)。
ü 聚类面板给WEKA提供了聚类技术,如简单的K-Means算法,也可以用期望最大化算法进行混合正态分布的学习。
ü 特征选择属性任务提供了数据集中大多数预测属性的识别算法。
(3) WEKA KnowledgeFlow的所有技术是建立在数据可作为一个单一的平面文件或关系这个假设前提上的,其中每个数据点被设计成一个固定数量的属性(通常是数字或名义的属性,但一些其它的属性类型也被支持)。因此WEKA Knowledge Flow 不能进行多位关系数据挖掘,但有独立的软件可以将连接的数据库表转换成一个单一的表,使其可以使用WEKA 进行处理。

2、RapidMiner
该工具是用 Java 语言编写的,通过基于模板的框架提供先进的分析技术。该款工具最大的好处就是,用户无需写任何代码。它是作为一个服务提供,而不是一款本地软件。值得一提的是,该工具在数据挖掘工具榜上位列榜首。
另外,除了数据挖掘,RapidMiner 还提供如数据预处理和可视化、预测分析和统计建模、评估和部署等功能。更厉害的是它还提供来自 WEKA(一种智能分析环境)和 R 脚本的学习方案、模型和算法。
RapidMiner 分布在 AGPL 开源许可下,可以从 SourceForge 上下载。SourceForge 是一个开发者进行开发管理的集中式场所,大量开源项目在此落户,其中就包括维基百科使用的 MediaWiki。
3、NLTK
当涉及到语言处理任务,没有什么可以打败 NLTK。NLTK 提供了一个语言处理工具,包括数据挖掘、机器学习、数据抓取、情感分析等各种语言处理任务。
而您需要做的只是安装 NLTK,然后将一个包拖拽到您最喜爱的任务中,您就可以去做其他事了。因为它是用 Python 语言编写的,你可以在上面建立应用,还可以自定义它的小任务。
4、Orange
Python 之所以受欢迎,是因为它简单易学并且功能强大。如果你是一个 Python 开发者,当涉及到需要找一个工作用的工具时,那么没有比 Orange 更合适的了。它是一个基于 Python 语言,功能强大的开源工具,并且对初学者和专家级的大神均适用。
此外,你肯定会爱上这个工具的可视化编程和 Python 脚本。它不仅有机器学习的组件,还附加有生物信息和文本挖掘,可以说是充满了数据分析的各种功能。

5、KNIME
数据处理主要有三个部分:提取、转换和加载。 而这三者 KNIME 都可以做到。 KNIME 为您提供了一个图形化的用户界面,以便对数据节点进行处理。它是一个开源的数据分析、报告和综合平台,同时还通过其模块化数据的流水型概念,集成了各种机 器学习的组件和数据挖掘,并引起了商业智能和财务数据分析的注意。
KNIME 是基于 Eclipse,用 Java 编写的,并且易于扩展和补充插件。其附加功能可随时添加,并且其大量的数据集成模块已包含在核心版本中。
KNIME(以KNIME 3.1为例)具有以下特点:
(1) 可视化的工作平台集成了数据访问、数据转换、数据探索和预测分析等常用的机器学习功能。
(2) 集成了数百个处理结点来进行数据输入与输出﹑预处理和清洗﹑建模﹑分析﹑数据挖掘以及制作各种互动的视图(如散点图﹑平行坐标和其他视图)。
(3) 可集成所有的分析模版到众所周知的WEKA 数据挖掘环境中,并有额外的插件模块允许R-脚本运行,还提供了广大统计例程库接口。
(4) 基于Eclipse 平台开发,并且通过其模块化的API 可轻松进行扩展。因为KNIME在后台可进行智能自动的数据缓存,同时最大限度地提高吞吐量性能,所以这种模块化和可扩展性允许KNIME 在商业的生产环境以及教学和研究原型设置工作中得到应用。
(5) 提供超过1000 个数据分析例程,无论是在本地或通过R和 WEKA都可以进行,如单元和多元统计、数据挖掘、时间系列、图像处理、Web 分析、文本挖掘以及社会化媒体分析等。
(6) 机器学习建模工作流程不仅可以通过交互式用户界面运行而且执行批处理模式,使数据分析过程可以很容易地定期集成到本地工作运行的管理中去。
(7) KNIME提供了大量的行业应用模板和定制化化的算子,便于特定应用行业的数据分析,譬如生物医药行业。
(8)具有 HiLite 功能,允许用户在节点结果中标记感兴趣的记录,并进一步展开后续探索。
6、R-Programming
如果我告诉你R项目,一个 GNU 项目,是由 R(R-programming简称,以下统称R)自身编写的,你会怎么想?它主要是由 C 语言和 FORTRAN 语言编写的,并且很多模块都是由 R 编写的,这是一款针对编程语言和软件环境进行统计计算和制图的免费软件。
R语言被广泛应用于数据挖掘,以及开发统计软件和数据分析中。近年来,易用性和可扩展性也大大提高了 R 的知名度。除了数据,它还提供统计和制图技术,包括线性和非线性建模,经典的统计测试,时间序列分析、分类、收集等等。
7.明略
明略可视化机器学习平台DataInsight本质是一种MLAAS平台,用户无须在客户端安装平台工具,通过浏览器即可进行拖拽,交互式数据探索,完成机器学习模型的训练、部署和应用。DataInsight不仅集成了Spark MLlib分布式机器学习能力,还定制了高效的分布式机器学习算法。
明略DataInsight平台基于BS架构,DataInsight通过提供一体化、并行化的高效模型应用平台,能帮助企业有效降低机器学习的应用曲线和落地成本。具有如下特点:
(1) 扩展性强。明略DataInsight平台基于Hadoop和Spark的并行化平台,计算能力随着大数据平台计算能力的扩展而扩展。其提供了多种数据预处理的并行化算法,以及大量并行运行于Spark之上的数据挖掘和机器学习算法。
(2) 模型工作流。使用工作流的概念表示整个建模过程,每个建模步骤看作一个算子,使得整个建模过程形成一幅有向无环图,建模过程将原始的输入通过一系列算子组合得到最终的业务结果。
(3) 交互式探索。明略DataInsight提供了交互式数据探索工具供用户对数据进行实验性的探索工作,帮助用户实时的对数据进行探索和实验。同时,明略DataInsight通过可视化的方法,提供了常用的数据统计和分析的图表,供用户能够直观的从图形中发掘数据背后的意义。
(4) 模型应用管理。提供模型应用的版本管理,能够方便的进行模型的维护和更新,提升工作效率。并且对模型的应用管理提供了用户和角色的支持,方便权限控制。
(5) 模型即服务。DataInsight平台通过Restful API向企业其他生产系统提供服务,外部系统可以通过Restful API实现模型的运行和更新等操作。