手把手带你实现简单的Python爬虫(图片+小说)爬取
目录
1.准备工作:
2.爬取图片
01:urllib中包括了四个模块,包括
03:网页源码(截取部分源码)
04:匹配正则
06:根据正则获取到的数据:
09:下载图片
2.结果:
3.小说
1.代码解释1.print(urls) :
2.f = open('C:\Story\{}.txt'.format(chapter_text), 'w') f.write(content) 流下载
3.结果:
1.准备工作:
前提:安装好Python环境和PyCharm编辑工具 https://www.runoob.com/python/python-install.html
所需开发库
开发库:1.urllib ->urllib.request 2.re python自带
2.爬取图片
import urllib.request
import re
htmlCode = urllib.request.urlopen('http://www.meituba.com/tag/juesemeinv.html').read() #01 源码获取
data = htmlCode.decode('utf-8') #02 设置编码格式
print(data) #03 打印网页源码
reg = r'src="(.*?.jpg)"' #04 匹配页面正则
reg_img = re.compile(reg) #05 根据正则创建模式对象
imglist = reg_img.findall(data) #06 获取到具体的对象
print(
imglist) #07 打印根据正则通配符匹配获取想要的具体的图片
x = 0
for img in imglist:
print(img) #08 循环获取具体元素
urllib.request.urlretrieve(img, 'C:\image\%s.jpg' % x) #09 下载图片到指定
x += 1
01:urllib中包括了四个模块,包括
urllib.request:可以用来发送request和获取request的结果 (常用) 可携带参数,表头......
urllib.error:包含了urllib.request产生的异常
urllib.parse:用来解析和处理URL
urllib.robotparse用来解析页面的robots.txt文件
03:网页源码(截取部分源码)
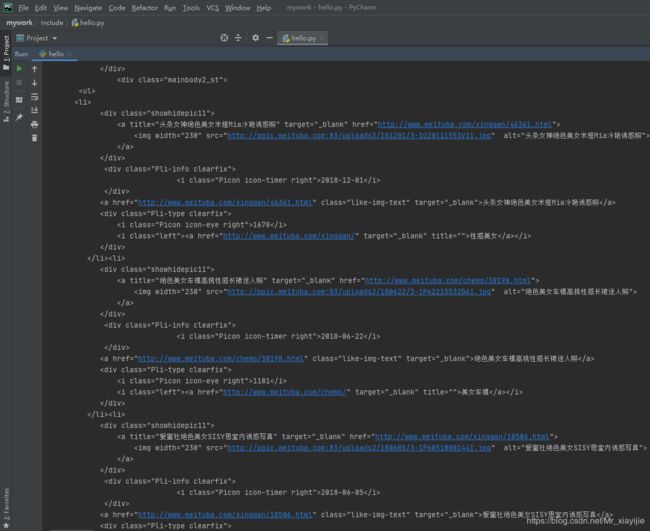
04:匹配正则
直接定位到,想要的资源标签,例如:

06:根据正则获取到的数据:
['http://ppic.meituba.com:83/uploads3/181201/3-1Q20111553V11.jpg', 'http://ppic.meituba.com:83/uploads2/180622/3-1P62215532D61.jpg', 'http://ppic.meituba.com:83/uploads2/180605/3-1P6051000144I.jpg', 'http://ppic.meituba.com:83/uploads2/170511/8-1F5110URc35.jpg', 'http://ppic.meituba.com:83/uploads/160322/8-1603220U50O23.jpg', 'http://ppic.meituba.com:83/uploads2/180317/3-1P31F91U1X9.jpg', 'http://ppic.meituba.com:83/uploads/160718/7-160GQ51G0b4.jpg', 'http://ppic.meituba.com:83/uploads2/170517/8-1F51G50301Q3.jpg', 'http://ppic.meituba.com:83/uploads/161010/7-1610101A202B0.jpg', 'http://ppic.meituba.com:83/uploads2/171102/7-1G102093511F7.jpg', 'http://ppic.meituba.com:83/uploads2/170901/7-1FZ1100545438.jpg', 'http://ppic.meituba.com:83/uploads/160625/8-160625093044631.jpg', 'http://ppic.meituba.com:83/uploads/160419/7-160419161553153.jpg', 'http://ppic.meituba.com:83/uploads2/170323/7-1F323103404A2.jpg', 'http://ppic.meituba.com:83/uploads2/170322/7-1F322105R1255.jpg', 'http://ppic.meituba.com:83/uploads2/170211/7-1F21110040Y63.jpg', 'http://ppic.meituba.com:83/uploads2/170110/7-1F110102005930.jpg', 'http://ppic.meituba.com:83/uploads/160618/8-16061Q04450391.jpg', 'http://ppic.meituba.com:83/uploads2/170330/3-1F3301HI6138.jpg', 'http://ppic.meituba.com:83/uploads2/161230/4-161230100U5V8.jpg']获取到了全部的图片生成一个数组
09:下载图片
urlretrieve(url, filename=None, reporthook=None, data=None)
url:下载链接地址
filename:指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据。)
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
data:指post导服务器的数据,该方法返回一个包含两个元素的(filename, headers) 元组,filename 表示保存到本地的路径,header表示服务器的响应头
拓展:可显示下载进度
import urllib.request
import re
#打印进度
def cbk(a, b, c):
per = 100.0 * a * b / c
if per > 100:
per = 100
print('%.2f%%' % per)
htmlCode = urllib.request.urlopen('http://www.meituba.com/tag/juesemeinv.html').read() # 01 源码获取
data = htmlCode.decode('utf-8') # 02 设置编码格式
print(data) # 03 打印网页源码
reg = r'src="(.*?.jpg)"' # 04 匹配页面正则
reg_img = re.compile(reg) # 05 根据正则创建模式对象
imglist = reg_img.findall(data) # 06 获取到具体的对象
print(
imglist) # 07 打印根据正则通配符匹配获取想要的具体的图片
x = 0
for img in imglist:
print(img) # 08 循环获取具体元素
urllib.request.urlretrieve(img, 'C:\image\%s.jpg' % x,cbk) # 09 下载图片到指定
x += 1
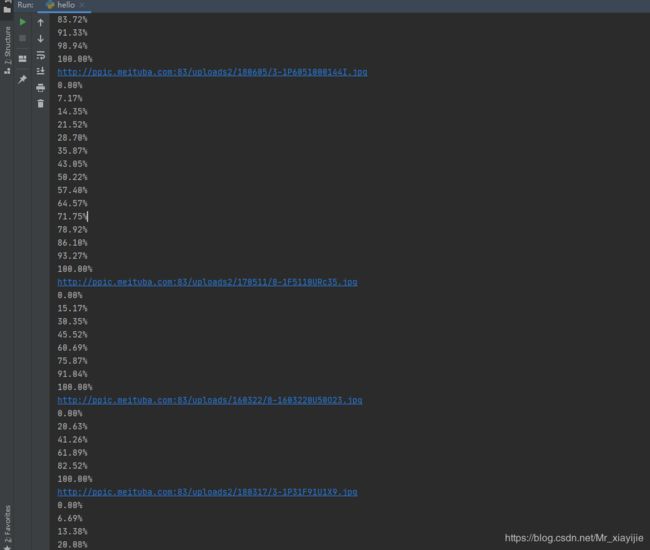
2.结果:

3.小说
data = urllib.request.urlopen('http://www.quanshuwang.com/book/44/44683').read()
data = data.decode('gbk')
reg = r'(.*?) ' #第一个正则为文章地址,第二个为标题
reg = re.compile(reg)
urls = reg.findall(data) #几个[格式:(正则)]就获取几个数据
print(urls)
for url in urls:
chapter_url = url[0] # 文章地址
chapter_text = url[1] # 文章标题
chapter_html = urllib.request.urlopen(chapter_url).read() # 获取该章节的全文代码
chapter_html = chapter_html.decode('gbk')
chapter_reg = r' .*?
(.*?)