Lucene介绍
1、Lucene简介
最受欢迎的java开源全文搜索引擎开发工具包。提供了完整的查询引擎和索引引擎,部分文本分词引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索功能,或者是以此为基础建立起完整的全文检索引擎。
Lucene是Apache的子项目,网址:http://lucene.apache.org/
2、Lucene用途
为软件开发人员提供一个建议的工具包,以方便在目标系统中实现全文检索功能,或者是以此为基础建立的全文检索引擎。
3、Lucene适用场景
- 在应用中为数据库中的数据提供全文检索实现。
- 开发独立的搜索引擎服务、系统
4、Lucene的特性
- 稳定、索引性能高
- 每小时能够索引150GB以上的数据
- 对内存的要求小,只需要1MB的堆内存
- 增量索引和批量索引一样快
- 索引的大小约为索引文本大小的20%~30%
- 高效、准确、高性能的搜索算法
- 良好的搜索排序
- 强大的查询方式支持:短语查询、通配符查询、临近查询、范围查询等
- 支持字段搜索(如标题、作者、内容)
- 可根据任意字段排序
- 支持多个索引查询结果合并
- 支持更新操作和查询操作同时进行
- 支持高亮、join、分组结果功能
- 速度快
- 可扩展排序模块,内置包含向量空间模型、BM25模型可选
- 可配置存储引擎
- 跨平台
- 纯java编写
- 作为Apache开源许可下的开源项目,你可以在商业或开源项目中使用
- Lucene有多种语言实现版(如C,C++、Python等),不仅仅是JAVA
5、Lucene架构
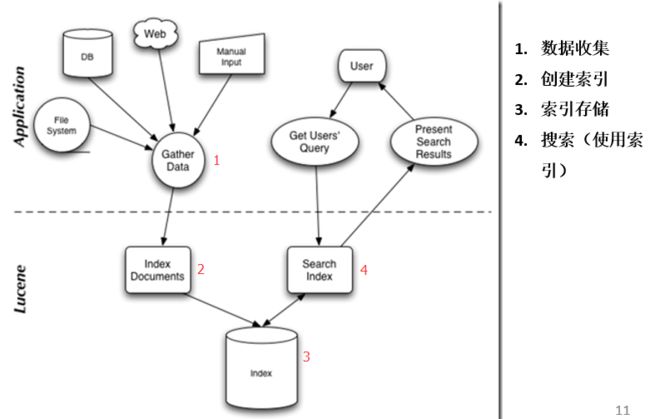
6、Lucene集成
- Lucene版本
当前最新版本7.3.0
- 系统要求
JDK1.8及以上版本
- 集成:将需要的Lucene模块的jar引入到你的应用中
方式一:官网下载zip,解压后拷贝jar到你的项目工程。
方式二:Maven引入依赖
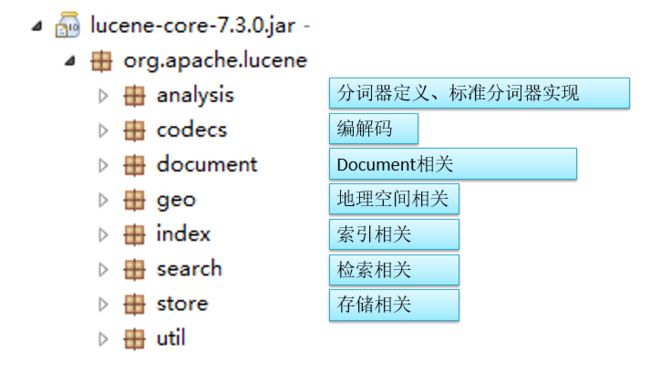
7、Lucene 模块说明
- core: Lucene core library 核心模块:分词、索引、查询
- analyzers- * : 以analyzers开头的都为分词器
- facet: Faceted indexing and search capabilities 提供分类索引、搜索能力
- grouping: Collectors for grouping search results. 搜索结果分组支持
- highlighter: Highlights search keywords in results 关键字高亮支持
- join: Index-time and Query-time joins for normalized content 连接支持
- queries: Filters and Queries that add to core Lucene 补充的查询、过滤方式实现
- queryparser: Query parsers and parsing framework 查询表达式解析模块
- spatial: Geospatial search 地理位置搜索支持
- suggest: Auto-suggest and Spellchecking support 拼写检查、联想提示
1. 引入Lucene的核心模块
org.apache.lucene
lucene-core
7.3.0
2. 了解核心模块的构成
分词器详解
1、Lucene - 分词器API
- org.apache.lucene.analysl.Analyzer
分析器,Analyzer 分词器组件的核心API,它的职责:构建正真正对文本进行分词处理的TokenStream(分词处理器)。通过调用它的如下两个方法,得到输入文本的分词处理器。
//两个都为fianl方法说明方法不能扩展
public final TokenStream tokenStream(String fieldName, Reader reader)
//第一个参数:字段的名字,第二个参数:字符输入流
public final TokenStream tokenStream(String fieldName, String text)
//第一个参数:字段的名字,第二个参数:字符串
问题1:从哪里得到了TokenStream?
//查看源码可以看出它返回的是一个components.getTokenStream(); 说明TokenStream是从components下得来的
public final TokenStream tokenStream(final String fieldName,
final Reader reader) {
TokenStreamComponents components = reuseStrategy.getReusableComponents(this, fieldName);
final Reader r = initReader(fieldName, reader);
if (components == null) {
components = createComponents(fieldName);
reuseStrategy.setReusableComponents(this, fieldName, components);
}
components.setReader(r);
return components.getTokenStream();
}
问题2:方法传入的字符流Reader 给了谁?
//通过上面的源码中
final Reader r = initReader(fieldName, reader);
components.setReader(r);
//可以看出Reader 交给了components处理
问题3: components是什么?components的获取逻辑是怎样?
//通过上面的源码中
TokenStreamComponents components = reuseStrategy.getReusableComponents(this, fieldName);
components.setReader(r);
if (components == null) {
components = createComponents(fieldName);
reuseStrategy.setReusableComponents(this, fieldName, components);
}
//可以看出components 首先是从重用策略(reuseStrategy)中去获取components ,如果没有则回去创建一个components 然后将其放入到 reuseStrategy 中
lucene中有一个特性为 对内存的要求小,只需要1MB的堆内存 所以在代码中会大量使用重用策略
问题4:createComponents(fieldName) 方法是个什么方法?
//在源码中我们可以看出 createComponents 是一个抽象方法需要其子类区具体实现
protected abstract TokenStreamComponents createComponents(String fieldName);
问题5:Analyzer能直接创建对象吗?
Analyzer 是一个抽象类所以它不能是new他们自己,但可以new他们的实现类
问题6:为什么它要这样设计?
因为Analyzer只是帮你构建TokenStream,但是它并不知道你将要把它用在何种语言下。
问题7:请看一下Analyzer的实现子类有哪些?
//Analyzer本身 只有这一个标准实现类
public final class StandardAnalyzer extends StopwordAnalyzerBase
问题8:要实现一个自己的Analyzer,必须实现哪个方法?
//必须实现 Analyzer 只有这一个抽象方法
protected abstract TokenStreamComponents createComponents(String fieldName);
- TokenStreamComponents createComponents(String fieldName)
createComponents 是Analizer中唯一的抽象方法,扩展点。通过提供该方法的实现来实现自己的Analyzer。
参数说明:fieldName,如果我们需要为不同的字段 创建 不同的分词处理器组件,则可根据这个参数来判断。否则,就用不到这个参数。
返回值:TokenStreamCoponents 分词处理器组件。
我们需要在 createComponents 方法中创建我们想要的分词处理器组件。
TonkenStreamComponents是什么?
TonkenStreamComponents 分词处理器组件:这个类中封装有供外部使用的TonkenStream分词处理器。提供了对source(源)和 sink(供外部使用分词处理器)两个属性的访问方法。
问题1:这个类的构造方法有几个?区别是什么?从中能发现什么?
//有两个构造方法,一个是传一个参数,一个是传两个参数。
//我们可以发现Tokenizer是继承了TokenStream的
public TokenStreamComponents(final Tokenizer source,
final TokenStream result) {
this.source = source;
this.sink = result;
}
public TokenStreamComponents(final Tokenizer source) {
this.source = source;
this.sink = source;
}
问题2:source 和 sink属性分别是什么类型?这两个类型有什么关系?
Tokenizer(source)是TokenStream(sink)的的子类
问题3:在这个类中没有创建source、sink对象的代码(而是由构造方法传入)。也就是说我们在Analyzer.createCommponents方法中创建它的对象前,需要先创建什么?
需要创建source、sink对象的
问题4:在Analyzer中tokenStream() 方法中把输入流给了谁?得到的TokenStream对象是谁?TokenStream对象sink中是否必须封装有source对象?
//我们将输入流交给了 source(Tokenizer)
protected void setReader(final Reader reader) {
source.setReader(reader);
}
//我们获取TokenStream对象为 sink(TokenStream)
public TokenStream getTokenStream() {
return sink;
}
//所以说我们TokenStream对象sink中必须封装有source对象
- org.apache.lucene.analysis.TokenStream
分词处理器,负责对输入文本完成分词、处理。
问题1:TokenStream中有没有对应的给入方法?
TokenStream并没有对应去获取Tokenizer的方法
问题2:TokenStream是一个抽象类,有哪些方法,它的抽象方法有哪些?它的构造方法有什么特点?
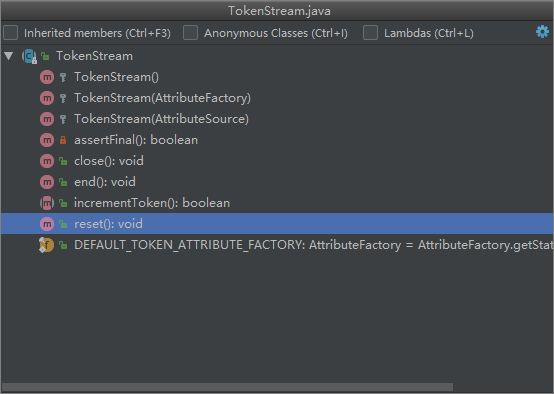
//一个抽象方法,这个方法主要是用于取得下一个分项的,如果有则返回true没有则返回false。每调一次返回一个分项
public abstract boolean incrementToken() throws IOException;
//构造方法三个都为 protected
protected TokenStream() {
super(DEFAULT_TOKEN_ATTRIBUTE_FACTORY);
assert assertFinal();
}
protected TokenStream(AttributeSource input) {
super(input);
assert assertFinal();
}
protected TokenStream(AttributeFactory factory) {
super(factory);
assert assertFinal();
}
问题3:TokenStream的具体子类分为哪两类?有什么区别?
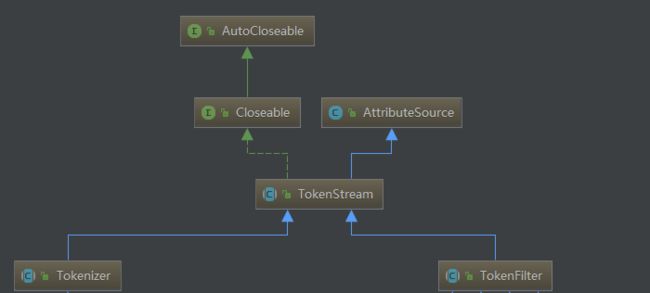
概念说明:Token:分项,从字符流中分出一个一个项。
Tokenizer:表示分词器,完成分词工作。输入:字符流。
TokenFilter:表示分项过滤器。输入:TokenStream。
先分词再分项
问题4:TokenStream继承了谁?他是干什么用的?
继承于AttributeSource类。
Token Attribute:分项属性(分项的信息):如包含的词、位置等
TokenStream的两类子类
Tokenizer:分词器,输入是Reader字符流的TokenStream,完成从流中分出分项
TokenFilter:分项过滤器,它的输入是另一个TokenStream,完成对从上一个TokenStream中流出的token的特殊处理。
问题1:请查看Tokenizer类的源码及注释,这个类该如何使用?要实现自己的Tokenizer只需要做什么?
使用实现就必须要实现它父类中的 incrementToken() 抽象方法。
问题2:Tokenizer的子类有那些?
在Lucene-core核心包中只有 StandardTokenizer
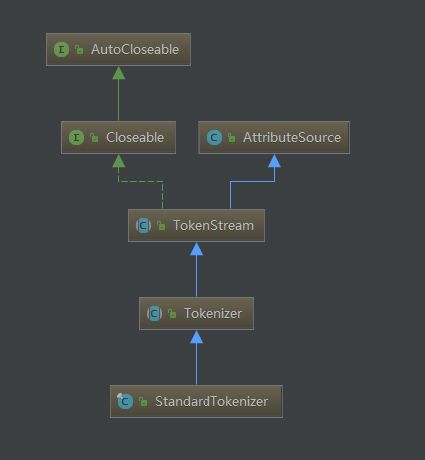
//StandardTokenizer 实现incrementToken方法
@Override
public final boolean incrementToken() throws IOException {
clearAttributes();
skippedPositions = 0;
while(true) {
int tokenType = scanner.getNextToken();
if (tokenType == StandardTokenizerImpl.YYEOF) {
return false;
}
if (scanner.yylength() <= maxTokenLength) {
posIncrAtt.setPositionIncrement(skippedPositions+1);
scanner.getText(termAtt);
final int start = scanner.yychar();
offsetAtt.setOffset(correctOffset(start), correctOffset(start+termAtt.length()));
typeAtt.setType(StandardTokenizer.TOKEN_TYPES[tokenType]);
return true;
} else
// When we skip a too-long term, we still increment the
// position increment
skippedPositions++;
}
}
问题3:请查看TokenFilter类的源码及注释,如何实现自己的TokenFilter?
使用实现就必须要实现它父类中的 incrementToken() 抽象方法。
问题4:TokenFilter的子类有哪些?
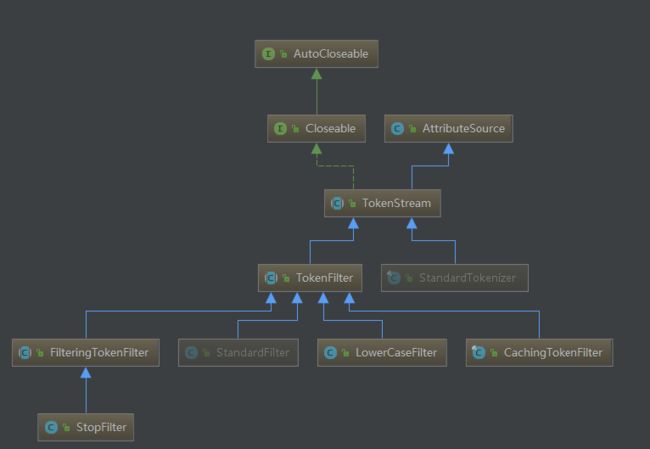
问题5:TokenFilter是不是一个典型的装饰器模式?
如果我们需要对分词进行各种处理,只需要按我们的处理顺序一层层包裹即可(每一层完成特定的处理)。不同的处理需要,只用不同的包裹顺序、层数。
TokenStream 继承了 AttributeSource
问题1:我们在TokenStream及它的两个子类中是否有看到关于分项信息的存储,如该分项的词是什么、这个词的位置索引?
概念说明:Attribute 属性 Token Attribute 分项属性(分项信息),如分项的词、词的索引位置等等。这些属性通过不同的Tokenizer/TokenFilter处理统计得出。
不同的Tokenizer/TokenFilter组合,就会有不同的分项信息。它是会动态变化的,你不知道有多少,是什么。那该如何实现分项信息的存储呢?
答案就是:AttributeSource、Attribute、AttributeImpl、AttributeFactory
- AttributeSource 负责存放Attribute对象,他提供对应的存、取方法
- Attribute 对象中则可以存储一个或多个属性信息
- AttributeFactory 则是负责创建Attribute对象的工厂,在TokenStream中默认使用了 AttributeFactory.getStaticImplementation 我们不需要提供,遵守它的规则即可。
AttributeSource使用规则说明
- 某个TokenStream 实现中如要储存分项属性,通过AttributeSource的两个add方法之一,往AttributeSource中加入属性对象。
T addAttribute(Class attClass)
- 该方法要求传入你需要添加的属性的接口类(继承Attribute),返回对应的实现类实例给你。从接口到实例,这就是为什么需要AttributeFactory的原因。
void addAttributeImpl(AttributeImpl att)
加入每一个Attribute实现类在AttributeSource中只会有一个实例,分词过程中,分项是重复使用这一实例来存放分项的属性信息。重复调用add方法添加它返回已存储的实例对象。
要获取分享的某属性信息,则需要持有某属性的实例对象,通过 addAttribute 方法获得Attribute对象,在调用实例的方法来获取、设置值。
-
在TokenStream中,我们用自己实现的Attribute,默认的工厂。当我们调用这个add方法时,他怎么知道实现类是哪个?这里有一定规则要遵守:
- 自定义的属性接口 MyAttribute 继承 Attribute
- 自定义的属性实现类必须继承AttributeImpl,实现自定义的接口MyAttribute
- 自定义的属性实现必须提供无参构造方法
- 为了让默认工厂(AttributeFactory)能根据自定义接口找到实现类,实现类需为 接口名+Impl
TokenStream的使用步骤
我们在应用中并不直接使用分词器,只需要为索引引擎和搜索引擎创建我们想要的分词器对象。但我们在选择分词器时,会需要测试分词器的效果,就需要知道如何使用得到的分词处理器TokenStream,使用步骤
- 从tokenStream获得你想要获得的分项属性对象(信息是存放在属性对象中的)
- 调用 tokenStream的 reset() 方法,进行重置。因为tokenStream是重复利用的。
- 循环调用tokenStream的increamentToken(),一个一个分词,直到它返回false
- 再循环中去除每个分项你想要的属性值
- 调用tokenStream的end(),执行任务需要的结束处理
- 调用tokenStream的close()方法,释放占有的资源。
简单实现一个我们自己的Analyzer

- 说明:Tokenizer分词时,是从字符流中一个一个字符读取,判断是否是空白字符来进行分词。
代码github地址
思考:Tokenizer是一个 AttributeSource对象,TokenFilter 又是一个AttributeSource对象。在这两个我们自己的实现类中,我们都调用了addAttribute方法,怎么会只有一个 attribute对象? 请查看源码找到答案。
在源码中TokenFilter继承于TokenStream
public abstract class TokenFilter extends TokenStream {
并且TokenFilter构造方法为
protected TokenFilter(TokenStream input) {
super(input);
this.input = input;
}
TokenStream构造方法,继承与AttributeSource
protected TokenStream(AttributeSource input) {
super(input);
assert assertFinal();
}
AttributeSource构造方法
public AttributeSource(AttributeSource input) {
Objects.requireNonNull(input, "input AttributeSource must not be null");
this.attributes = input.attributes;
this.attributeImpls = input.attributeImpls;
this.currentState = input.currentState;
this.factory = input.factory;
}
在实例代码中,贴出主要代码
//创建Tokenizer
Tokenizer source = new MyWhitespaceTokenizer();
//创建TokenStream 分项过滤器
TokenStream filter = new MyLowerCaseTokenFilter(source);
public MyLowerCaseTokenFilter(TokenStream input){
super(input);
}
MyLowerCaseTokenFilter 继承于 TokenFilter