为分布式做准备吧——深入理解JVM
文章目录
- 类加载机制
- 类执行机制
- 字节码解释执行
- (运行时)编译执行
- 反射执行
- 内存回收
- 内存空间
- 收集器
- Sun JDK可用的GC
之前我们文章提到过 反射,说的比较浅显,我们这里来理解JVM。
一个标准的JVM是这样的

JVM负责装载class文件并执行,我们首先来了解类加载和执行的机制。
类加载机制
JVM将.class文件加载到JVM,并形成Class对象,之后就可以对Class对象进行实例化并调用。
该过程分为三个步骤:
- 装载。
- 链接。
- 初始化。
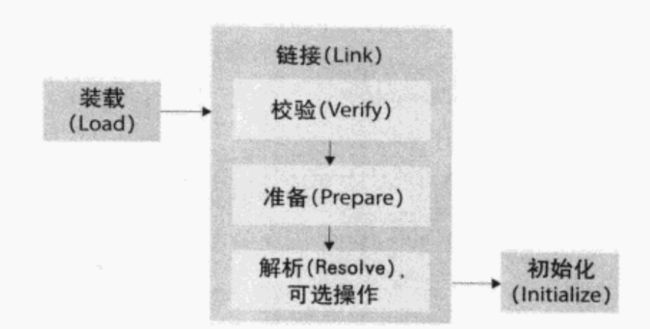
- 装载
负责找到二进制字节码并加载到JVM中。
JVM通过类的全限定名以及类加载器完成类的加载。
比如Object[] o=new Object[10],o的全限定名:[Ljava.lang.Object,并由数组型中的元素类型所在的ClassLoader进行加载。
- 链接
链接过程负责对二进制字节码进行校验、初始化装载类中的静态变量以及解析类中调用的接口、类。
- 初始化
初始化过程即执行类中的静态初始化代码,构造器代码以及静态属性的初始化。
类执行机制
在完成将class文件信息加载到JVM并产生Class对象后,就可执行Class对象的静态方法或实例化对象进行调用了。在源码编译阶段,将源码编译为JVM字节码,JVM字节码是一种中间代码的方式,要由JVM在运行期间对其进行解释并执行。这种方式称为:字节码解释执行方式。
字节码解释执行
由于采用JVM字节码,也就是说JVM有一套自己的指令来执行中间码:
- invokestatic
调用static方法 - invokevirtual
调用对象实例的方法 - invokeinterface
调用接口 - invokespecial
调用private方法和对象初始化方法
比如下面这一段代码:
public class Demo{
public void execute(){
A.execute();
A a=new A();
a.bar();
IFoo b=new B();
b.bar();
}
}
class A{
public static int execute(){
return 1+2;
}
public int bar(){
return 1+2;
}
}
class B implements IFoo{
public int bar(){
return 1+2;
}
}
public interface IFoo{
public int bar();
}
通过javac 编译上面的代码后,使用javap -c Demo 查看其execute方法的字节码:
Compiled from "Demo.java"
public class Demo {
public Demo();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."":()V
4: return
public void execute();
Code:
0: invokestatic #2 // Method A.execute:()I
3: pop
4: new #3 // class A
7: dup
8: invokespecial #4 // Method A."":()V
11: astore_1
12: aload_1
13: invokevirtual #5 // Method A.bar:()I
16: pop
17: new #6 // class B
20: dup
21: invokespecial #7 // Method B."":()V
24: astore_2
25: aload_2
26: invokeinterface #8, 1 // InterfaceMethod IFoo.bar:()I
31: pop
32: return
}
从上面的栗子可以看出,四种指令对应调用方法的情况。
Sun JDK基于栈的体系结构来执行字节码,基于栈方式的好处就是代码紧凑,体积小。
线程在创建后,都会产生程序计数器(PC或者称为PC registers)和栈(Stack);PC存放了下一条要执行的指令在方法内的偏移量;栈中存放了栈帧(StackFrame),每个方法每次调用都会产生栈帧,栈帧主要分为局部变量区和操作数栈两个部分,局部变量区用于存放方法体中的局部变量和参数,操作数栈中用于存放方法执行过程中产生的中间结果,栈帧中还有一些其他空间,例如只想方法已解析的常量池的引用、其他一些VM内部需要的数据等,具体结构如下图所示:

下面来看一个方法执行时过程的栗子:
public class Demo2{
public static void foo(){
int a=1;
int b=2;
int c=(a+b)*5;
}
}
同样的方法获得JVM字节码:
public class Demo2 {
public Demo2();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."":()V
4: return
public static void foo();
Code:
0: iconst_1
1: istore_0
2: iconst_2
3: istore_1
4: iload_0
5: iload_1
6: iadd
7: iconst_5
8: imul
9: istore_2
10: return
}
每条字节码及其对应的解释如下:

对于方法的指令解释执行,执行方式为经典冯诺伊曼体系中的FDX循环方式,即获取下一条指令,解码并分派,然后执行。在实现FDX循环时有switch-threading、token-threading、direct-threading等多种方式。
第一种swith-threading,代码大致如下:
while(true){
int code=fetchNextCode();//下一条指令
switch(code){
case IADD: //do add
case ...: //do sth
}
}
每次执行完都得重新回到循环开始点,然后重新获取下一条指令,并继续switch,这导致了大部分时间都花在了跳转和获取下一条指令上,真的的业务逻辑代码非常短。
token-threading在上面的基础上稍微有所修改:
IADD:{
//do add
fetchNextCode();//下一条指令
dispatch();
}
ICONST_0:{
push(0);
fetchNextCode();下一条指令
dispatch();
}
...
该方法相对第一种switch-threading而言,冗余了fetch next code和dispatch,相对比较消耗内存,但是由于去除了switch,因此性能会稍微好一些。
其他的xxx-threading做了更多的优化,在此不做赘述。Sun JDK的重点为编译成机器码,并没有在解释器上做太复杂的处理,因此采用了token-threading方法,为了让解释执行能够更加高效,Sun JDK还做了一些其他的优化,主要是:栈顶缓存(top-of-stack caching)和部分栈帧共享。
栈顶缓存
在方法执行过程中,可以看到有很多操作要将值放入操作数栈,这导致了寄存器和内存要不断的交换数据,Sun JDK采用了一个栈顶缓存,即将本来位于操作数栈顶的值直接缓存到寄存器上,可直接在寄存器计算,然后放回操作数栈。
部分栈帧共享
当一个方法调用另一个方法时,通常传入另一个方法的参数为已存放在操作数栈的数据,Sun JDK采用:当调用方法时,后一个方法将前一个方法的操作数栈作为当前方法的局部变量,从而节省数据copy带来的消耗。
(运行时)编译执行
由于解释执行的效率太低,Sun JDK提供将字节码编译为机器码,在执行过程中,对执行频率高的代码进行编译执行,对执行不频繁的代码采用解释执行,因此Sun JDK也称为Hotspot VM,在编译上Sun JDK提供了两种模式,client compiler(-client) 和 server compiler(-server)。
- client compiler
client compiler比较轻量级,制作少量性能开销比较高的优化,它占用内存较少,适合于桌面交互式应用,主要的优化有:方法内联、去虚拟化、冗余消除等。
1.方法内联
例如这样一段代码:
public void bar(){
...
bar2();
...
}
public void bar2(){
//bar2执行代码
}
当编译时,如果bar2代码编译后的字节数小雨等于35个字节(可以通过启动参数-XX:MaxInlineSize=35来控制),那么会演变称为这样的结构:
public void bar(){
...
//bar2执行代码
...
}
可在debug版本的JDK的启动参数上加上-XX:+PrintInlining来查看方法内联信息。
2.去虚拟化
去虚拟化是指在装载class文件后,进行类层次的分析,如发现类中的方法只提供一个实现类,那么对于调用了此方法的代码,也可进行方法内联,从而提升执行的性能。
例如这样的代码:
public interface IFoo{
public void bar();
}
public class Foo implements IFoo{
public void bar(){
//Foo bar method
}
}
public class Demo{
public void execute(IFoo foo){
foo.bar();
}
}
当整个JVM只有Foo实现了IFoo接口,Demo execute方法被编译的时候,就会演变成类似这样的结构:
public void execute(){
//Foo bar method
}
3.冗余消除
冗余消除是指在编译时,根据运行时状况进行折叠或消除代码。
比如:
private static final Log=log.LogFactory.getLog("BLUEDAVY");
private static final boolean isDebug=log.isDebugEnabled();
public void execute(){
if(isDebug){
log.debug(xxx);
}
//do something else
}
如果boolean值是false那么会演变为如下的结构:
public void execute(){
//do something else
}
- server compiler
server compiler较为重量级,采用了大量传统编译优化技巧,占用内存相对较多,适合服务端的应用,下面介绍几个优化:
1.标量替换
例如:
Point p=new Point(1,2);
sout("point.x="+p.x+";point.y="+p.y);
当p对象在后面没用到的时候,会演变成下面的结构:
int x=1;
int y=2;
sout("point.x="+x+";point.y="+y);
2.同步消除
如果发现同步的对象没必要,那么会直接去掉:
Point p=new Point();
sysnchronized(p){
//do something
}
演变为:
Point p=new Point();
//do somehing
从上面两种重量级和轻量级的编译来看,它们做了很多努力来优化。为什么不再一开始就编译称为机器码呢? 主要有下面几方面的原因: 1. 静态编译并不能根据程序的运行状况来优化执行的代码,server compiler收集运行数据越长,编译出来的代码会越优化。 2. 解释执行比编译执行更省内存。 3. 启动时解释执行的启动速度比编译后再启动更快。
那么什么时候就需要编译呢?这需要一个权衡值,Sun JDK有两个计数器来计算阈值:
- CompileThreshold
当方法被调用多少次后,编译为机器码。通过-XX:CompileThreshold=10000来设置该值。client默认1500次,server默认10000; - OnStackReplacePercentage
栈上替换的百分比,该值用于/参与计算是否触发OSR编译的阈值,通过-XX:OnStackReplacePercentage=140来设置。在client模式下,计算规则为:CompileThreshold * (OnStackReplacePercentage/100);在server模式下,计算规则为:(OnStackReplacePercentage – InterpreterProfilePercentage))/100
反射执行
反射执行是基于反射来动态调用某对象实例中对应的方法,访问查看对象的属性等等,之前的文章写的很清楚。
Java中通过如下的方法调用:
Class actionClass=Class.forName(外部实现类);
Method method=actionClass.getMethod(“execute”,null);
Object action=actionClass.newInstance();
method.invoke(action,null);
这样在创建对象过程和方法调用过程是动态的,具有很高的灵活性。
内存回收
内存空间
Sun JDK在实现时,将内存空间划分为方法区、堆、本地方法栈、PC寄存器以及JVM方法栈。如下图所示:
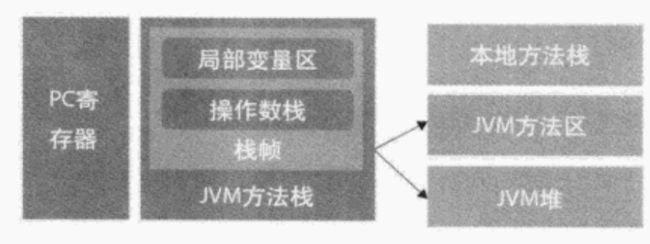
- 方法区
方法区存放了要加载的类的信息、静态变量、final类型常量等信息。方法区是全局共享的。
通过-XX:PermSize和-XX:MaxPermSize来指定最小最大的值,保证方法区内存大小。
- 堆
堆用于存储对象实例及数组值,可以认为Java中所有new的对象都在此分配。
- 本地方法栈
用于支持native方法的执行。在Sun JDK的实现中本地方法栈和JVM方法栈是同一个。
- PC寄存器和JVM方法栈
每个线程单独创建自己的PC寄存器和JVM方法栈(私有的)。当方法运行完毕时,其对应的栈帧所用内存也会自动释放。
收集器
JVM通过GC来回收堆和方法区中的内存,GC的基本原理是首先找到程序中不再被使用的对象,然后回收这些对象所占用的内存。
主要的收集器有引用计数收集器和跟踪收集器。
- 引用计数收集器
顾名思义,通过计数器记录对象引用数目,当引用数目为0时回收对象。 - 跟踪收集器
跟踪收集器采用的为集中式的管理方式,全局记录数据的引用状态。基于一定条件触发(例如定时触发或者空间不足时触发),执行时需要从根集合来扫描对象的引用关系,这可能会造成应用程序暂停,主要有复制、标记-清除、标记-压缩三种实现算法。
(其实就是清理内存的算法,计算机原理也学过)
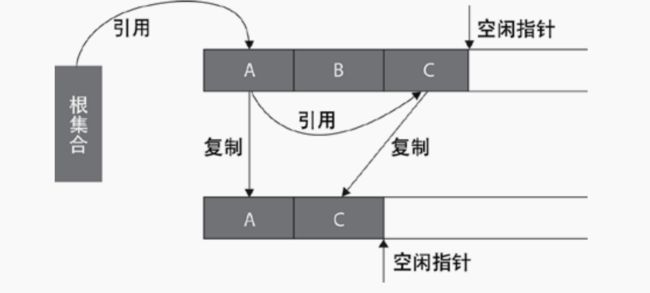
复制:从根集合中扫描存活的对象,复制到未使用的空间中。
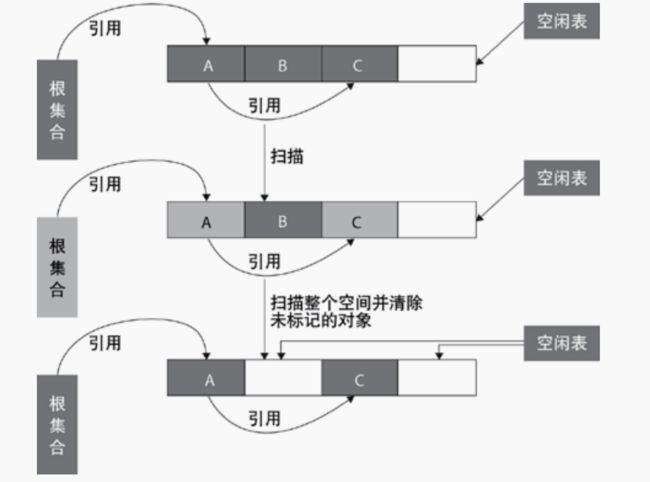
标记清除:从根集合中扫描,对存活的对象标记,然后再扫描整个空间中未标记的对象,进行回收。
标记压缩:和标记清除一样也要进行标记,不过第二步在回收不存活的对象的内存后,会将对象左移压缩。

Sun JDK可用的GC
以上三种跟踪收集器各有优缺点,Sun JDK认为:程序中大部分对象存活时间都是较短的,只有少部分是长期存活的。根据这一分析,JVM被划分为新生代和旧生代,根据两代generation有不同的GC实现。

新生代中对象存活期短,因此选用复制算法进行回收。由于在复制的时候,需要一块未使用的空间来存放存活的对象(和固态硬盘一样,也是要预留空间),所以新生代又被分为Eden、S0、S1三块空间。
Eden Space存放新创建的对象,S0或S1其中一块作为复制的目标空间(轮流):当一块作为复制的目标空间,另一块被清空。因此S0和S1也被称为:From Space和To Space。
Sun JDK提供了串行GC、并行回收GC和并行GC三种方式来回收,在此不做赘述。
旧生代与新生代不同,对象存活的时间比较长,比较稳定,因此采用标记(Mark)算法来进行回收,所谓标记就是扫描出存活的对象,然后再进行回收未被标记的对象,回收后对用空出的空间要么进行合并,要么标记出来便于下次进行分配,总之就是要减少内存碎片带来的效率损耗。在执行机制上JVM提供了串行 GC(SerialMSC)、并行GC(parallelMSC)和并发GC(CMS),具体算法细节还有待进一步深入研究。