Memory Translation and Segmentation(内存转换与段)
Memory Translation and Segmentation(内存转换与段)
https://manybutfinite.com/post/memory-translation-and-segmentation/
This post is the first in a series about memory and protection in Intel-compatible (x86) computers, going further down the path of how kernels work. As in the boot series, I'll link to Linux kernel sources but give Windows examples as well (sorry, I'm ignorant about the BSDs and the Mac, but most of the discussion applies). Let me know what I screw up.
这篇文章是有关英特尔兼容(x86)计算机中的内存和保护的系列文章中的第一篇,它进一步介绍了内核的工作方式。 与启动系列一样,我将链接到Linux内核源代码,但也提供Windows示例(对不起,我对BSD和Mac不了解,但是大多数讨论适用)。 让我知道我搞砸了。
In the chipsets that power Intel motherboards, memory is accessed by the CPU via the front side bus, which connects it to the northbridge chip. The memory addresses exchanged in the front side bus are physical memory addresses, raw numbers from zero to the top of the available physical memory. These numbers are mapped to physical RAM sticks by the northbridge. Physical addresses are concrete and final - no translation, no paging, no privilege checks - you put them on the bus and that's that. Within the CPU, however, programs use logical memory addresses, which must be translated into physical addresses before memory access can take place. Conceptually address translation looks like this:
在为英特尔主板供电的芯片组中,CPU通过前端总线访问内存,该总线将其连接到北桥芯片。 在前端总线中交换的内存地址是物理内存地址,即从零到可用物理内存顶部的原始数字。 这些数字由北桥映射到物理RAM棒。 物理地址是具体且最终的-没有转换,没有分页,没有特权检查-您将它们放在总线上就可以了。 但是,在CPU内,程序使用逻辑内存地址,必须先将其转换为物理地址,然后才能进行内存访问。 从概念上讲,地址翻译如下:
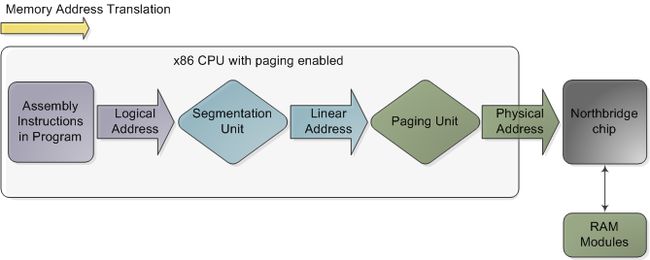
Memory address translation in x86 CPUs with paging enabled(启用分页的x86 CPU中的内存地址转换)
This is not a physical diagram, only a depiction of the address translation process, specifically for when the CPU has paging enabled. If you turn off paging, the output from the segmentation unit is already a physical address; in 16-bit real mode that is always the case. Translation starts when the CPU executes an instruction that refers to a memory address. The first step is translating that logic address into a linear address. But why go through this step instead of having software use linear (or physical) addresses directly? For roughly the same reason humans have an appendix whose primary function is getting infected. It's a wrinkle of evolution. To really make sense of x86 segmentation we need to go back to 1978.
这不是物理图,仅是地址转换过程的描述,特别是当CPU启用分页时。 如果关闭分页,则分段单元的输出已经是物理地址; 在16位实模式下,情况总是如此。 当CPU执行引用内存地址的指令时,转换开始。 第一步是将该逻辑地址转换为线性地址。 但是,为什么要执行此步骤而不是让软件直接使用线性(或物理)地址呢? 出于大致相同的原因,人类有一个阑尾,其主要功能正在被感染。 这是进化的皱纹。 为了真正理解x86分割,我们需要回到1978年。
The original 8086 had 16-bit registers and its instructions used mostly 8-bit or 16-bit operands. This allowed code to work with 216 bytes, or 64K of memory, yet Intel engineers were keen on letting the CPU use more memory without expanding the size of registers and instructions. So they introduced segment registers as a means to tell the CPU which 64K chunk of memory a program's instructions were going to work on. It was a reasonable solution: first you load a segment register, effectively saying "here, I want to work on the memory chunk starting at X"; afterwards, 16-bit memory addresses used by your code are interpreted as offsets into your chunk, or segment. There were four segment registers: one for the stack (ss), one for program code (cs), and two for data (ds, es). Most programs were small enough back then to fit their whole stack, code, and data each in a 64K segment, so segmentation was often transparent.
原始的8086具有16位寄存器,其指令主要使用8位或16位操作数。 这使代码可以处理216字节或64K内存,但是Intel工程师渴望让CPU使用更多内存而不扩大寄存器和指令的大小。 因此他们引入了段寄存器作为告诉CPU程序指令要在哪个64K内存块上工作的方法。 这是一个合理的解决方案:首先加载一个段寄存器,有效地说:“在这里,我要处理从X开始的内存块”; 之后,代码使用的16位内存地址将被解释为块或段中的偏移量。 有四个段寄存器:一个用于堆栈(ss),一个用于程序代码(cs),两个用于数据(ds,es)。 当时大多数程序都足够小,可以将它们的整个堆栈,代码和数据容纳在一个64K段中,因此分段通常是透明的。
Nowadays segmentation is still present and is always enabled in x86 processors. Each instruction that touches memory implicitly uses a segment register. For example, a jump instruction uses the code segment register (cs) whereas a stack push instruction uses the stack segment register (ss). In most cases you can explicitly override the segment register used by an instruction. Segment registers store 16-bit segment selectors; they can be loaded directly with instructions like MOV. The sole exception is cs, which can only be changed by instructions that affect the flow of execution, like CALL or JMP. Though segmentation is always on, it works differently in real mode versus protected mode.
如今,分段仍然存在,并且始终在x86处理器中启用。 每条隐式接触内存的指令都使用一个段寄存器。 例如,跳转指令使用代码段寄存器(cs),而堆栈压入指令使用堆栈段寄存器(ss)。 在大多数情况下,您可以显式覆盖指令使用的段寄存器。 段寄存器存储16位段选择器; 它们可以直接用MOV等指令加载。 唯一的例外是cs,它只能由影响执行流程的指令(例如CALL或JMP)进行更改。 尽管分段始终处于启用状态,但它在实模式与受保护模式下的工作方式有所不同。
In real mode, such as during early boot, the segment selector is a 16-bit number specifying the physical memory address for the start of a segment. This number must somehow be scaled, otherwise it would also be limited to 64K, defeating the purpose of segmentation. For example, the CPU could use the segment selector as the 16 most significant bits of the physical memory address (by shifting it 16 bits to the left, which is equivalent to multiplying by 216). This simple rule would enable segments to address 4 gigs of memory in 64K chunks, but it would increase chip packaging costs by requiring more physical address pins in the processor. So Intel made the decision to multiply the segment selector by only 24 (or 16), which in a single stroke confined memory to about 1MB and unduly complicated translation. Here's an example showing a jump instruction where cs contains 0x1000:
在实模式下,例如在早期启动期间,段选择器是一个16位数字,用于指定段开始的物理内存地址。 该数字必须以某种方式进行缩放,否则也将其限制为64K,无法实现分段的目的。 例如,CPU可以将段选择器用作物理内存地址的16个最高有效位(通过将其左移16位,相当于乘以216)。 这个简单的规则将使段能够以64K块寻址4 GB的内存,但是会由于需要处理器中更多的物理地址引脚而增加芯片封装成本。 因此,英特尔决定将段选择器仅乘以24(或16),这在单个笔划中将内存限制为大约1MB,并且翻译过于复杂。 这是显示cs包含0x1000的跳转指令的示例:

Real mode segmentation(段真实模式)
Real mode segment starts range from 0 all the way to 0xFFFF0 (16 bytes short of 1 MB) in 16-byte increments. To these values you add a 16-bit offset (the logical address) between 0 and 0xFFFF. It follows that there are multiple segment/offset combinations pointing to the same memory location, and physical addresses fall above 1MB if your segment is high enough (see the infamous A20 line). Also, when writing C code in real mode a far pointer is a pointer that contains both the segment selector and the logical address, which allows it to address 1MB of memory. Far indeed. As programs started getting bigger and outgrowing 64K segments, segmentation and its strange ways complicated development for the x86 platform. This may all sound quaintly odd now but it has driven programmers into the wretched depths of madness.
实模式段的范围从0一直到0xFFFF0(1 MB少16个字节),以16个字节为增量。向这些值添加0到0xFFFF之间的16位偏移量(逻辑地址)。随之而来的是,有多个段/偏移量组合指向相同的内存位置,并且如果段足够高,则物理地址将超过1MB(请参见臭名昭著的A20行)。同样,在实模式下编写C代码时,远指针是一个既包含段选择器又包含逻辑地址的指针,这使其可以寻址1MB的内存。确实如此。随着程序开始变得越来越大并超出了64K的细分市场,分段及其奇怪的方式使x86平台的开发变得复杂。这听起来似乎有些古怪,但它已使程序员陷入疯狂的悲惨境地。
In 32-bit protected mode, a segment selector is no longer a raw number, but instead it contains an index into a table of segment descriptors. The table is simply an array containing 8-byte records, where each record describes one segment and looks thus:
在32位保护模式下,段选择器不再是原始数字,而是包含段描述符表的索引。该表只是一个包含8字节记录的数组,其中每个记录描述了一个段并因此看起来:

Segment descriptor(段描述符)
There are three types of segments: code, data, and system. For brevity, only the common features in the descriptor are shown here. The base address is a 32-bit linear address pointing to the beginning of the segment, while the limit specifies how big the segment is. Adding the base address to a logical memory address yields a linear address. DPL is the descriptor privilege level; it is a number from 0 (most privileged, kernel mode) to 3 (least privileged, user mode) that controls access to the segment.
段分为三种类型:代码,数据和系统。 为简洁起见,此处仅显示描述符中的共同特征。 基地址是指向段开头的32位线性地址,而限制则指定段的大小。 将基地址添加到逻辑存储器地址会产生线性地址。 DPL是描述符特权级别; 它是一个数字(从0(最高特权,内核模式)到3(最低特权,用户模式))来控制对该段的访问。
These segment descriptors are stored in two tables: the Global Descriptor Table (GDT) and the Local Descriptor Table (LDT). Each CPU (or core) in a computer contains a register called gdtr which stores the linear memory address of the first byte in the GDT. To choose a segment, you must load a segment register with a segment selector in the following format:
这些段描述符存储在两个表中:全局描述符表(GDT)和本地描述符表(LDT)。 计算机中的每个CPU(或内核)都包含一个名为gdtr的寄存器,该寄存器存储GDT中第一个字节的线性内存地址。 要选择一个段,您必须使用以下格式的段选择器加载段寄存器:

Segment Selector(段选择器)
The TI bit is 0 for the GDT and 1 for the LDT, while the index specifies the desired segment selector within the table. We'll deal with RPL, Requested Privilege Level, later on. Now, come to think of it, when the CPU is in 32-bit mode registers and instructions can address the entire linear address space anyway, so there's really no need to give them a push with a base address or other shenanigan. So why not set the base address to zero and let logical addresses coincide with linear addresses? Intel docs call this "flat model" and it's exactly what modern x86 kernels do (they use the basic flat model, specifically). Basic flat model is equivalent to disabling segmentation when it comes to translating memory addresses. So in all its glory, here's the jump example running in 32-bit protected mode, with real-world values for a Linux user-mode app:
对于GDT,TI位为0,对于LDT,TI位为1,而索引指定表中所需的段选择器。 稍后,我们将处理RPL(请求的特权级别)。 现在,想一想,当CPU处于32位模式时,指令无论如何都可以寻址整个线性地址空间,因此,实际上没有必要使用基地址或其他shenanigan进行推送。 那么,为什么不将基址设置为零,而让逻辑地址与线性地址重合呢? 英特尔文档称此为“平面模型”,这正是现代x86内核所做的(具体来说,它们使用基本的平面模型)。 基本平面模型等效于在转换内存地址时禁用分段。 因此,在所有方面,这都是在32位保护模式下运行的跳转示例,其中包含Linux用户模式应用程序的实际值:
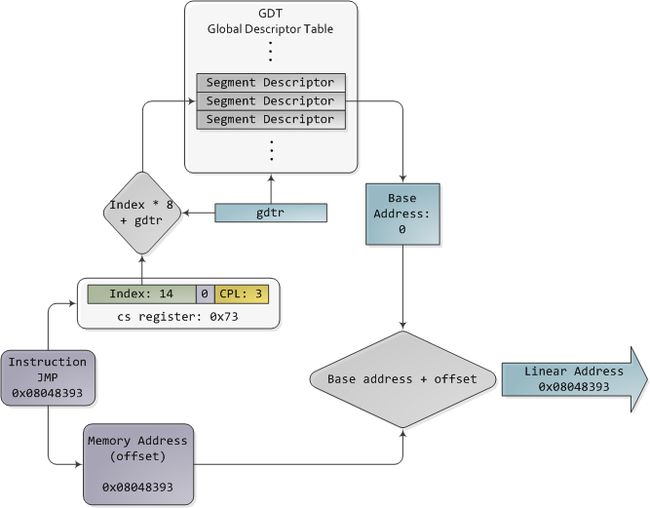
Protected Mode Segmentation(段保护模式)
The contents of a segment descriptor are cached once they are accessed, so there's no need to actually read the GDT in subsequent accesses, which would kill performance. Each segment register has a hidden part to store the cached descriptor that corresponds to its segment selector. For more details, including more info on the LDT, see chapter 3 of the Intel System Programming Guide Volume 3a. Volumes 2a and 2b, which cover every x86 instruction, also shed light on the various types of x86 addressing operands - 16-bit, 16-bit with segment selector (which can be used by far pointers), 32-bit, etc.
段描述符的内容一旦被访问就被缓存,因此无需在后续访问中实际读取GDT,这会降低性能。 每个段寄存器都有一个隐藏部分来存储与其段选择器相对应的缓存描述符。 有关更多详细信息,包括有关LDT的更多信息,请参阅《英特尔系统编程指南第3a卷》第3章。 卷2a和2b涵盖了每条x86指令,也阐明了各种类型的x86寻址操作数-16位,带段选择器的16位(可用于远指针),32位等。
In Linux, only 3 segment descriptors are used during boot. They are defined with the GDT_ENTRY macro and stored in the boot_gdt array. Two of the segments are flat, addressing the entire 32-bit space: a code segment loaded into cs and a data segment loaded into the other segment registers. The third segment is a system segment called the Task State Segment. After boot, each CPU has its own copy of the GDT. They are all nearly identical, but a few entries change depending on the running process. You can see the layout of the Linux GDT in segment.h and its instantiation is here. There are four primary GDT entries: two flat ones for code and data in kernel mode, and another two for user mode. When looking at the Linux GDT, notice the holes inserted on purpose to align data with CPU cache lines - an artifact of the von Neumann bottleneck that has become a plague. Finally, the classic "Segmentation fault" Unix error message is not due to x86-style segments, but rather invalid memory addresses normally detected by the paging unit - alas, topic for an upcoming post.
在Linux中,引导期间仅使用3个段描述符。它们由GDT_ENTRY宏定义,并存储在boot_gdt数组中。其中两个段是平面的,可寻址整个32位空间:一个代码段加载到cs中,一个数据段加载到其他段寄存器中。第三段是称为任务状态段的系统段。引导后,每个CPU都有自己的GDT副本。它们几乎都是相同的,但是一些条目会根据运行的进程而变化。您可以在segment.h中看到Linux GDT的布局,其实例位于此处。 GDT有四个主要条目:两个平坦的条目用于内核模式下的代码和数据,另外两个平坦的条目用于用户模式。在查看Linux GDT时,请注意故意插入的孔以使数据与CPU缓存行对齐-这是困扰冯·诺依曼瓶颈的产物。最后,经典的“ Segmentation fault” Unix错误消息不是由于x86样式的段,而是由于分页单元通常检测到的无效内存地址-,,即将发表的帖子的主题。
Intel deftly worked around their original segmentation kludge, offering a flexible way for us to choose whether to segment or go flat. Since coinciding logical and linear addresses are simpler to handle, they became standard, such that 64-bit mode now enforces a flat linear address space. But even in flat mode segments are still crucial for x86 protection, the mechanism that defends the kernel from user-mode processes and every process from each other. It's a dog eat dog world out there! In the next post, we'll take a peek at protection levels and how segments implement them.
英特尔巧妙地解决了他们最初的细分难题,为我们提供了一种灵活的方式来选择是细分还是合并。 由于一致的逻辑地址和线性地址更易于处理,因此它们成为标准配置,因此64位模式现在可以强制执行平坦的线性地址空间。 但是,即使在平面模式下,分段对于x86保护仍然至关重要,这种机制可以保护内核免受用户模式进程的侵害,并使每个进程相互抵御。 这是一个狗吃狗的世界! 在下一篇文章中,我们将窥视保护级别以及分段如何实现它们。
Thanks to Nate Lawson for a correction in this post.