SequoiaDB Spark Yarn部署及案例演示
1、背景
由于MRv1在扩展性、可靠性、资源利用率和多框架等方面存在明显的不足,在Hadoop MRv2中引入了资源管理和调度系统YARN。YARN是 Hadoop MRv2计算机框架中构建的一个独立的、通用的资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。主要体现在以下几个方面:
(1)资源利用率大大提高。一种计算框架一个集群,往往会由于应用程序数量和资源需求的不均衡性,使得在某段时间有些计算框架集群资源紧张,而另外一些集群资源空闲。共享集群模式则通过多种框架共享资源,使得集群中的资源得到更加充分的利用;
(2)运维成本大大降低。共享集群模式使得少数管理员就可以完成多个框架的统一管理;
(3)共享集群的模式也让多种框架共享数据和硬件资源更为方便。
2、产品介绍
巨杉数据库SequoiaDB是一款分布式非关系型文档数据库,可以被用来存取海量非关系型的数据,其底层主要基于分布式,高可用,高性能与动态数据类型设计,它兼顾了关系型数据库中众多的优秀设计:如索引、动态查询和更新等,同时以文档记录为基础更好地处理了动态灵活的数据类型。并且为了用户能够使用常见的分布式计算框架,SequoiaDB可以和常见分布式计算框架如Spark、Hadoop、HBase进行整合。本文主要讲解SequoiaDB与Spark、YARN的整合以及通过一个案例来演示MapReduce分析存储在SequoiaDB中的业务数据。
3、环境搭建
3.1、服务器分布

3.2、软件配置
操作系统:RedHat6.5
JDK版本:1.7.0_80 64位
Scala版本:
Hadoop版本:2.7.2
Spark版本:2.0
SequoiaDB版本:2.0
3.3、安装步骤
1、JDK安装
tar -xvf jdk-7u45-linux-x64.tar.gz –C /usr/local
cd /usr/local
ln -s jdk1.7.0_45 jdk配置环境变量
vim ~/.bash_profile
export JAVA_HOME=/usr/local/jdk
export CLASS_PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile 2、Scala安装
tar -xvf scala-2.11.8.tgz –C /usr/local
cd /usr/local
ln -s scala-2.11.8 scala配置环境变量
vim ~/.bash_profile
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin 3、修改主机hosts文件配置
在每台主机上修改host文件
vim /etc/hosts
192.168.1.46 node01
192.168.1.47 node02
192.168.1.48 master4、 SSH免密钥登录
在master节点中执行ssh-keygen按回车键
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys 将master节点中的授权文件authorized_keys传输到slave节点中
scp ~/.ssh/id_rsa.pub root@master:~/.ssh/在slave节点中执行
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
在slave节点中验证SSH免密钥登录
ssh master
5、Hadoop集群安装
拷贝hadoop文件hadoop-2.7.2.tar.gz到/opt目录中
解压hadoop安装包
tar –xvf hadoop-2.7.2.tar.gz
mv hadoop-2.7.2 /opt/cloud/hadoop
创建hadoop数据存储及临时目录
mkdir –p /opt/hadoop/data
mkdir –p /opt/hadoop/tmp
配置Hadoop jdk环境变量
vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk
编辑core.xml文件
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
/opt/data/tmp
io.file.buffer.size
4096
编辑mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobtracker.http.address
master:50030
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
编辑hdfs-site.xml
dfs.nameservices
master
dfs.namenode.secondary.http-address
master:50090
dfs.namenode.name.dir
file:///opt/hadoop/data/name
dfs.datanode.data.dir
file:///opt/hadoop/data
dfs.replication
3
dfs.webhdfs.enabled
true
编辑yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.resource-tracker.address
master:8031
yarn.resourcemanager.admin.address
master:8033
yarn.resourcemanager.webapp.address
master:8088
yarn.nodemanager.resource.memory-mb
12288
yarn.nodemanager.log-dirs
/opt/hadoop/tmp/userlogs
启动Hadoop
首次启动集群时,做如下操作
进入到/opt/cloud/hadoop/bin目录中执行./hdfs namenode –format格式化
hdfs文件系统
进入到/opt/cloud/hadoop/sbin目录中执行./start-all.sh启动hadoop集群
6、安装Spark集群
拷贝Spark安装包到/opt目录中,解压
tar –xvf spark-2.0.0-bin-hadoop2.7.tgz
mv spark-2.0.0-bin-hadoop2.7 /opt/cloud/spark编辑spark-env.sh
vim spark-env.sh
JAVA_HOME="/usr/jdk1.7"
SPARK_DRIVER_MEMORY="1g"
SPARK_EXECUTOR_CORES=1
SPARK_EXECUTOR_MEMORY="512m"
SPARK_MASTER_PORT="7077"
SPARK_MASTER_WEBUI_PORT="8070"
SPARK_CLASSPATH="/opt/cloud/spark/jars/sequoiadb.jar:/opt/cloud/spark/jars/spark-sequoiadb_2.11-2.6.0.jar"
SPARK_MASTER_IP="node03"
SPARK_WORKER_MEMORY="712m"
SPARK_WORKER_CORES=1
SPARK_WORKER_INSTANCES=1
SPARK_WORKER_DIR="/opt/data/spark/work"
SPARK_LOCAL_DIRS="/opt/data/spark/tmp"
HADOOP_HOME="/opt/cloud/hadoop"
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop编辑 slaves
node02
node03启动spark集群
进入到目录/opt/cloud/spark/sbin目录中
./start-all.sh
Spark成功启动后截图如下:

7、Spark Yarn连接SequoiaDB
在SequoiaDB中创建集合空间、集合
db.createCS('poc');
db.poc.createCL('test');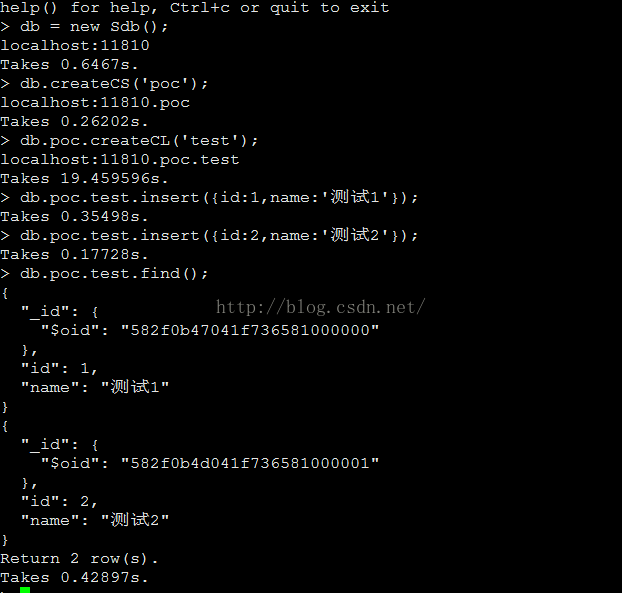
进入到spark安装目录bin中,执行./spark-sql –master yarn启动spark sql交互界面
创建表,映射到上述poc集合空间中test集合
CREATE TABLE `test` (`id` INT, `name` STRING)
USING com.sequoiadb.spark
OPTIONS (
`collection` 'test',
`host` 'node02:11810,node03:11810',
`serialization.format` '1',
`collectionspace` 'poc'
);查询表test数据,执行:
Select * from test;
进入到yarn管理页面查看spark任务

5、 案例演示
为了配合司法部门的执法和银行内部的风险监管,部分商业银行对于存取款业务定制了相关预警方案,本案例以个人存取款业务高频交易来讲述MapReduce如何分析SequoiaDB中的个人交易明细数据。
具体场景为:分析同一实体柜员办理,1小时内同一账户连续3笔以上支取类金额的交易账户及明细。
本演示案例采用Hadoop Map Reduce实现,开发语言为Java语言。整个测试程序分为两个部分Map算法和Reduce算法。演示程序中Map算法负责将同一个账号的所有对应交易明细归并在一起并输出给Reduce端,Reduce端根据Map算法的结果运算具体的业务场景,最后将运算结果写入到SequoiaDB中。
具体架构如下:

Reduce端具体算法流程如下:

Map端算法代码如下:
static class TMapper extends Mapper{
@Override
protected void map(Object key, BSONWritable value, Context context)
throws IOException, InterruptedException {
BSONObject obj = value.getBson();
String acct_no=(String) obj.get("ACCT_NO");
context.write(new Text(acct_no), value);
}
}
Reduce端算法代码如下:
static class TReducer extends Reducer{
private static String pattern = "yyyy-MM-dd HH:mm:ss";
private DateFormat df = new SimpleDateFormat(pattern);
private static int tradeNum1 = 3;
private static int tradeTime1 = 3600;
private static int tradeNum2 = 2;
private static int tradeTime2 = 1800;
private static int tradeAll = 100000;
private Sequoiadb sdb = null;
private CollectionSpace cs = null;
private DBCollection cl_1 = null;
private DBCollection cl_2 = null;
private static String CS_NAME="";
private static String CL_NAME_1="";
private static String CL_NAME_2="";
public TReducer(){
if (null == sdb) {
sdb = ConnectionPool.getInstance().getConnection();
}
if (sdb.isCollectionSpaceExist(CS_NAME)) {
cs = sdb.getCollectionSpace(CS_NAME);
} else {
throw new BaseException("集合空间" + CS_NAME + "不存在!");
}
if (null == cs) {
throw new BaseException("集合空间不能为null!");
} else {
this.cl_1 = cs.getCollection(CL_NAME_1);
}
if (null == cs) {
throw new BaseException("集合空间不能为null!");
} else {
this.cl_2 = cs.getCollection(CL_NAME_2);
}
}
@Override
protected void reduce(Text key, Iterable values,
Context context)
throws IOException, InterruptedException{
Iterator iterator=values.iterator();
long sum=0;
List oldList = new ArrayList();
while(iterator.hasNext()){
BSONWritable bsonWritable = iterator.next();
oldList.add(bsonWritable);
}
//对values进行排序,排序字段为TRN_TIME(交易时间)
Collections.sort(oldList, new Comparator() {
@Override
public int compare(BSONWritable o1, BSONWritable o2) {
String trn_time1 = (String)o1.getBson().get("TRN_TIME");
String trn_time2 = (String)o2.getBson().get("TRN_TIME");
return trn_time2.compareTo(trn_time1);
}
});
Map result = new HashMap();
if(oldList != null && oldList.size() > 0){
//记录同一账户满足条件的笔数
Map tempMap = new HashMap();
for(int i=0;i tradeTime1){
break;
}
tempMap.put(jrnl_no2,bSONWritable2);
}else{ //end if TRN_CD1.equals("000045")
continue;
}
}//end for
if(tempMap.size() >= tradeNum1){
result.putAll(tempMap);
tempMap.clear();
}
}else{
continue;
}//end if ||
}//end for
}
Map result2 = new HashMap();
List cl_1_list = new ArrayList();
//结果写入sdb
Iterator iter1 = result.keySet().iterator();
while(iter1.hasNext()){
String keyValue = (String)iter1.next();
BSONWritable resultValue = result.get(keyValue);
cl_1_list.add(resultValue.getBson());
cl_1.insert(resultValue.getBson());
}
cl_1.bulkInsert(cl_1_list, DBCollection.FLG_INSERT_CONTONDUP);
cl_1_list = null;
List cl_2_list = new ArrayList();
context.write(null,null);
}
} SequoiaDB巨杉数据库2.6最新版下载
SequoiaDB巨杉数据库技术博客
SequoiaDB巨杉数据库社区