分代垃圾回收(Mark-Sweep GC),并不是一个具体的算法,只是结合了几种垃圾回收算法,把对象按特点进行了分类,对每种特点的对象集执行不同的回收算法,从而提升回收效率
阅读本文之前,你最好已经了解了复制算法和标记清除算法,因为文中不会过多重复介绍复制算法和清除算法的内容
分代垃圾回收在对象中引用了 “年龄” 的概念,通过优先回收容易称为垃圾的对象,从而提高垃圾回收的效率。
大部分的对象在生成后马上就变成了垃圾, 很少有对象能活得很久。
分代垃圾回收利用这个经验,在对象中加入了 “年龄” 的概念,经理过一次 GC 后还活下来的对象年龄为 1 岁。
分代垃圾回收中把对象分为几代(generation),针对不同的代使用不同的 GC 算法;把新生成的对象称为年轻代 (Young Generation) 对象,到达一定年龄的对象称为老年代 (Old/Tenured Generation) 对象。
由于大多数对象都是 “朝生夕死” 的,所以可以考虑对年轻代进行 “只标记存活对象” 的算法,因为存活对象较少,所以回收效率高。
年轻代 GC 称为 Minor GC。经历多次年轻代 GC 仍然存活的对象,就可以当作老年代对象来处理。这种年轻代转移到老年代的情况称为晋升(promotion)。
因为老年代对象很难成为垃圾(经过几次 GC 还存活的对象,一般都是都是永久存活了),所以老年代 GC 的频率会很低,老年代 GC 称为 Major GC。
本文参考的是 David Ungar 在 1984 年提出的算法,基于 C 语言
名词解释
对象
对象在 GC 的世界里,代表的是数据集合,是垃圾回收的基本单位。
指针
可以理解为就是 C 语言中的指针(又或许是 handle),GC 是根据指针来搜索对象的。
mutatar
这个词有些地方翻译为赋值器,但还是比较奇怪,不如不翻译……
mutator 是 Edsger Dijkstra 琢磨出来的词,有 “改变某物” 的意思。说到要改变什么,那就是 GC 对象间的引用关系。不过光这么说可能大家还是不能理解,其实用一句话概括的话,它的实体就是“应用程序”。
mutatar 的工作有以下两种:
- 生成对象
- 更新指针
mutator 在进行这些操作时,会同时为应用程序的用户进行一些处理(数值计算、浏览网页、编辑文章等)。随着这些处理的逐步推进,对象间的引用关系也会 “改变”。伴随这些变化会产生垃圾,而负责回收这些垃圾的机制就是 GC。
GC ROOTS
GC ROOTS 就是引用的起始点,比如栈,全局变量
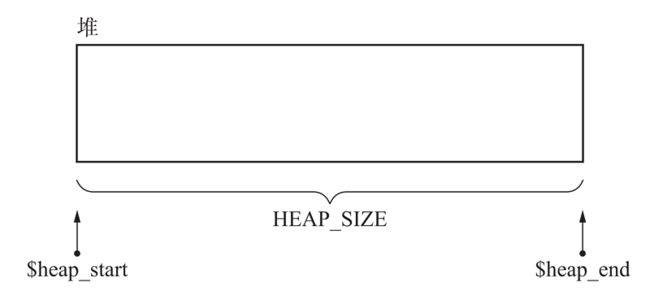
堆 (Heap)
堆就是进程中的一段动态内存,在 GC 的世界里,一般会先申请一大段堆内存,然后 mutatar 在这一大段内存中进行分配
活动对象和非活动对象
活动对象就是能通过 mutatar(GC ROOTS)引用的对象,反之访问不到的就是非活动对象。
准备工作
首先是对象类型的结构:
为了动态访问 “对象” 的属性,此处使用属性偏移量来记录属性的位置,然后通过指针的计算获得属性

然后是对象的结构,虽然 C 语言中没有继承的概念,但是可以通过共同属性的 struct 来实现:

算法实现
在分代垃圾回收中,堆的结构如下图所示。将堆分成了 4 个部分,从左至右分别是新生成区 (Eden),两个大小相等的幸存空间 (Survivor)From/to,以及一个老年代区 (Old Gen),Eden+Survivor 都属于年轻代区域(New Gen)。
年轻代对象会分配在年轻代区域,老年代对象会分配在老年代。
此处还额外准备了一个记录集(Remembered set),来存储跨代的引用(跨代引用下面会介绍)

年轻代 GC(Minor GC)
由于新生代对象特点是 “朝生夕死”,所以对年轻代使用复制算法;Eden 区存放的是新生成的对象,当 Eden 满了之后,年轻代 GC 就会启动,将生成空间的所有活动对象复制,不过目标区域是 Survivor 区。
Survivor 区分为了两个空间,每次回收只会使用其中的一个。当执行年轻代 GC 的时候,Eden 区的活动对象会被复制到 From 中;当第二次年轻代 GC 时,会将 Eden 和 From 区内存活的对象一起复制到 To 区,之后再把 From/To 功能 “互换”(这里的互换并没有互换数据,在程序中只是把引用换了)
下面是 From/To 互换的逻辑,只是将指针互换了以下而已:

具体 “互换” 流程如下图所示:

对象晋升 (Promotion)
对象中有一个 age 字段,代表对象经历的年轻代 GC 次数,新创建的对象年龄为 0,每经历一次年轻代 GC 还存活的对象年龄会加 1;在年轻代 GC 时,每次会检查对象的年龄,当超过一定限制(AGE_MAX)时,会将对象晋升到老年代。
以下是晋升老年代的处理:
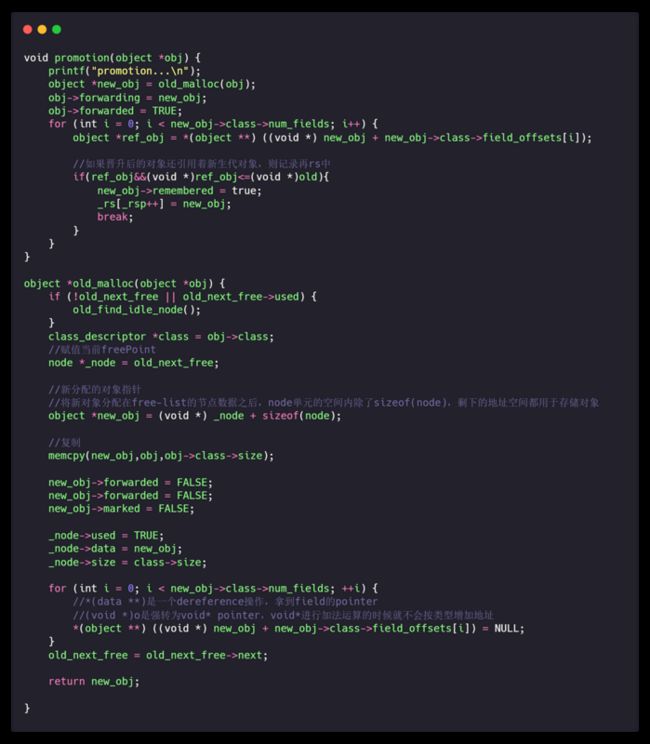
详细晋升流程如下图所示(图中包含了基本的年轻代 GC 过程):

跨代引用
既然有晋升的操作,那么这里会有一个问题:当对象晋升后,引用关系如何处理,对于老年代到年轻代的引用,可达性分析时怎么处理,是否还需要从 GC ROOTS 开始遍历老年代呢?
比如对象 A 晋升前,和年轻代另一个存活的对象 B 关联,A 在 GC ROOTS 中,B 不在;当对象 A 晋升后,对于 GC ROOTS 来说 B 是不可达(unreachable)的,但是对于 A 来说 B 是可达的
或者对象 A 晋升后,又新分配了对象 C,然后用 A 引用 C,此时对于 GC ROOTS 来说,C 也是不可达的
由于存在跨代引用的可能,所以在年轻代 GC 时,只从 GC ROOTS 开始遍历年轻代对象是不够的,还需要将老年代中引用年轻代的那部分对象也作为 GC ROOTS,这样才能保证完整的回收年轻代
扫描老年代这部分对象看起来没问题,可是由于老年代的特点是长期存活的对象,空间很大对象很多,扫描老年代的成本要远远大于扫描 GC ROOTS,成本太高,所以直接从 GC ROOTS 遍历老年代或者顺序遍历老年代的 free-list 不合适。
记录集合(Remembered set)
跨代引用这个问题可以以空间换时间的方式,使用一个额外的数组来存储跨代引用的关系:
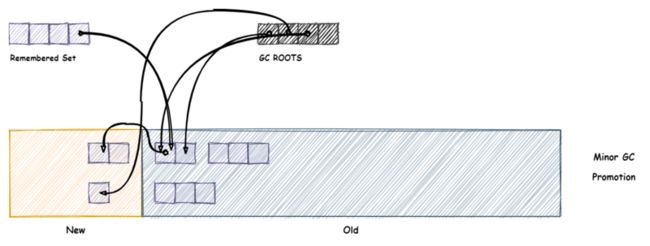
如上图所示,使用一个额外的 Remembered Set 来存储引用着年轻代那部分的老年代对象,当发生年轻代 GC 时,除了要遍历 GC ROOTS 中那部分年轻代对象,还要遍历 Remembered Set 中的这部分存在跨代引用的对象,这样就避免了额外扫描老年代的问题
至于这个 Remembered Set 的添加时机也很简单,只需要在发生晋升时检查晋升对象是否还包含年轻代对象的引用即可,如果包含就将晋升的对象添加到 Remembered Set。
本文中只做了最简单的实现,当晋升后的对象还保留年轻代的引用时,手动添加到 Remembered Set
手动更新引用:若老年代对象的新引用是年轻代对象,则添加到 Remembered Set
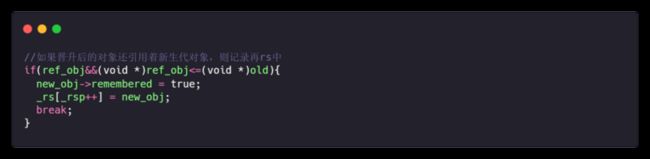
自动更新引用:对晋升的对象执行 "write_barrier",检查是否存在跨代引用,若存在则添加到 Remembered Set 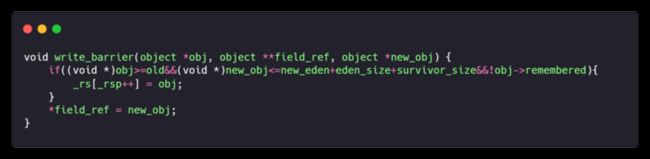
这个额外的添加操作看着有点傻,而且如果跨代引用过多还可能会导致 RS 溢出,所以有另一种替代 Remembered Set 的方式:页面标记(Card Marking),由于本文没有实现,这里就不做介绍了
老年代 GC(Major GC)
由于老年代对象的特点是长期存活,所以老年代空间一般会比年轻代大很多。而且基于这个长期存活的特点,老年代并不适合复制算法,因为复制算法需要频繁移动对象,且复制算法效率取决于存活对象数量;所以老年代会使用标记 - 清除算法,和基本的清除算法一样,具体参考之前的文章《垃圾回收算法实现之 - 标记 - 清除(完整可运行 C 语言代码)》
优点
“大部分的对象在生成后马上就变成了垃圾, 很少有对象能活得很久。” 这一说法虽然并不绝对,但还是可以适应绝大多数场景的。以这个理论为前提,新生代 GC 只会扫描新生代空间的对象,这样就可以减少 GC 的时间消耗
而且一般年轻代空间会设置的较小,而且是复制算法效率极高,所以就算新生代 GC 频繁,在时间的消耗上一般也是可以介绍的;老年代清除算法效率低且空间大,但是由于老年代对象的特点是长期存活,所以老年代的 GC 频率会很低。
综合来看,分代回收之后,会大幅改善 GC 所消耗的时间
缺点
“大部分的对象在生成后马上就变成了垃圾, 很少有对象能活得很久。” 这个原则毕竟只适合大多数情况,不可能适用所有程序,所以如果出现不匹配的场景,就可能会导致以下问题:
- 年轻代 GC 后不可达对象极少,导致复制对象过多造成耗时增加
- 老年代被提前填满,导致老年代 GC 频繁
完整代码
https://github.com/kongwu-/gc_impl/tree/master/generational
相关文章
- 垃圾回收算法实现之 - 标记-清除(完整可运行C语言代码)
- 垃圾回收算法实现之 - 引用计数(完整可运行C语言代码)
- 垃圾回收算法实现之 - 复制(完整可运行C语言代码)
- 垃圾回收算法实现之 - 标记-整理(完整可运行C语言代码)
- 垃圾回收算法实现之 - 分代回收(完整可运行C语言代码)
参考
- 《垃圾回收的算法与实现》 中村成洋 , 相川光 , 竹内郁雄 (作者) 丁灵 (译者)
- 《垃圾回收算法手册 自动内存管理的艺术》 理查德·琼斯 著,王雅光 译