论文浅尝 - ACL2020 | 用于回答知识库中的多跳复杂问题的查询图生成方法
论文笔记整理:谭亦鸣,东南大学博士。

来源:ACL 2020
链接:
https://www.aclweb.org/anthology/2020.acl-main.91.pdf
1.介绍
在以往的工作中,知识图谱复杂问答一般被分为两种类型分别处理:
其一是带有约束的问题,例如“Who was the first president of the U.S.?”,其中仅包含一个关系“presidentof…”但存在约束“first”,对于这类问题,一般采用多阶段方法通过构建包含关系的主路径,再对其添加约束的方式得到对应查询图;
其二则是多关系问题,例如“Who is the wife of the founder of Facebook?”,其中包含两个关系“wife of…”以及“founder of…”,这类问题的回答需要考虑更长的关系路径,主要挑战在于长路径带来的更大的搜索空间,一般采用beam search的方式实现答案路径的构成;这篇文章里,作者尝试同时解决这两类问题(较少有人考虑同时处理这两类问题)。
动机:作者发现,通过优先将约束合并到查询图中(querygraph),可以有效减少多关系情况下的搜索空间规模。基于上述动机,作者提出了一种改进的阶段查询图生成方法用于灵活的生成查询图。在三个benchmark KBQA数据集上,该模型均达到了最优实验效果。
2.模型/方法
参照过去的工作,一个查询图包含四类节点,如图1所示:
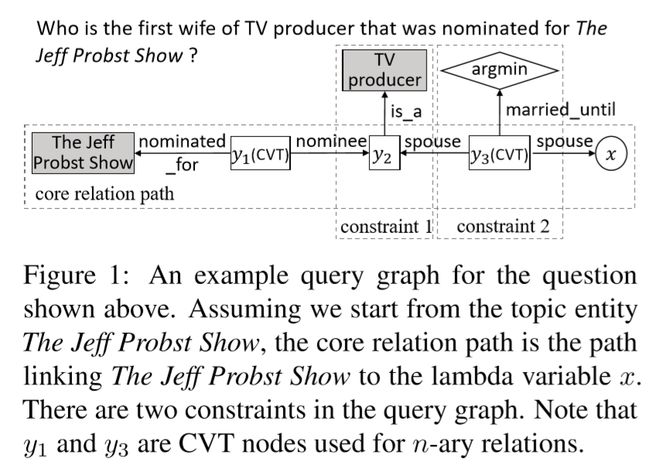
Grounded entity(图1灰色矩形节点):是已经存在于KG的实体节点;
Existential variable(图1白色矩形节点):未确定的KG中的实体节点;
Lambda variable(图1圆形节点):也是未确定的KG实体节点,一般表示答案;
Aggregation function(图1菱形节点):是一种对实体集合的聚合函数,例如argmin取最小值,或count计数等;
一般阶段查询图构建过程是:
a.从groundedentity出发,确定一条主关系路径,连接到一个lambda variable节点(目前的工作中,这主路径只包含一个关系)
b.向主路径中添加(问题里出现的)一个或多个约束,约束由一个固定实体或者一个聚合函数与一个关系组成。
c.对于前两步得到的所有candidate查询图,通过衡量它们与问题的相似性进行排序,而后挑出目标查询图(一般利用CNN完成),从而从KG中找到答案
本文工作的挑战是多跳(多关系)主路径问题,作者表示,如果简单的利用上述方法扩充到2-hop或更多跳的问题中,对于每个问题将会得到10000规模的主路径候选,穷举情况下,这个计算量就相当不划算了。
以图1中的问题为例,作者考虑的多关系问题解答过程举例如下:
给定一个局部主路径The Jeff Probst Show(entity)→nominated_for(elation) → y1(entity) →nominee(relation)→y2(entity),首先对y2添加约束(is_a, TV producer)约束,再找y2对应实体时的搜索空间将大幅缩减。
作者提出了三种action:{extend,connect,aggregate}用于查询图生成的循环过程,从而使得生成过程更加灵活。
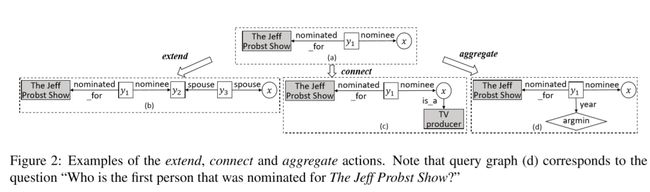
Extend:在主路径上添加一个关系,如果当前查询图仅包含一个主实体,extend操作将会找到一个在KG中连接到主实体的r,并扩充主路径。如果主路径上存在lambdavariable,extend操作将会把该节点变为existential variable,通过执行当前查询图,从KG中找到所有与该节点相结合的节点,并找到对应的关系添加到查询图中,关系的另一端节点则标为新的lambdavariable。
Connect:除了主实体之外,问题中也常常存在其他确定实体,connect操作将这些确定实体连接到答案节点或者某个中间节点上。
Aggregate:则是将聚合操作函数作为新的节点添加到答案节点或中间节点上。
三个操作并没有严格的顺序规定,因此查询图生成过程的限制相对较少。
在得到候选查询图之后,作者使用一个七维特征向量衡量图与原始自然语言问题之间的相似性,实现查询图排序。七维特征分别来自:
BERT-based 语义匹配模型
查询图中确定实体的累计实体链接得分
确定实体在查询图中出现的数量
实体类型数,时序表达以及查询图中的最高级,最后一个特征是答案实体在查询图中的个数。
3.实验
实验数据:ComplexWebQuestion, WebQuestionSP以及ComplexQuestions, 其中以ComplexWebQuestion为主要评估数据集,因为其中的多关系带约束复杂问题占比相对其他两者更多。
对比模型包括三类:现有的阶段查询图生成模型(无法处理多跳关系);beam搜索方法(无法处理约束);将复杂问题拆分为简单问题的方法。
实验结果如下表所示

OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。