1. Apache Flink 介绍
来源: http://www.54tianzhisheng.cn/...
Apache Flink 是近年来越来越流行的一款开源大数据计算引擎,它同时支持了批处理和流处理,也能用来做一些基于事件的应用。使用官网的一句话来介绍 Flink 就是 “Stateful Computations Over Streams”。
首先 Flink 是一个纯流式的计算引擎,它的基本数据模型是数据流。流可以是无边界的无限流,即一般意义上的流处理。也可以是有边界的有限流,这样就是批处理。因此 Flink 用一套架构同时支持了流处理和批处理。其次,Flink 的一个优势是支持有状态的计算。如果处理一个事件(或一条数据)的结果只跟事件本身的内容有关,称为无状态处理;反之结果还和之前处理过的事件有关,称为有状态处理。稍微复杂一点的数据处理,比如说基本的聚合,数据流之间的关联都是有状态处理。
- 无穷数据集:无穷的持续集成的数据集合
- 有界数据集:有限不会改变的数据集合
那么那些常见的无穷数据集有哪些呢?
- 用户与客户端的实时交互数据
- 应用实时产生的日志
- 金融市场的实时交易记录
- …
数据运算模型有哪些呢:
- 流式:只要数据一直在产生,计算就持续地进行
- 批处理:在预先定义的时间内运行计算,当完成时释放计算机资源
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i3IYaQm9-1595768814163)(https://ws3.sinaimg.cn/large/...]
){kind=link}
2. What is Flink?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1KK2dXk1-1595768814167)(https://ws3.sinaimg.cn/large/...]
){kind=link}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8uDNlF7v-1595768814169)(https://ws2.sinaimg.cn/large/...]
){kind=link}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W7z6hQI9-1595768814171)(https://ws4.sinaimg.cn/large/...]
){kind=link}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4mHt3Iq8-1595768814173)(/Applications/Typora.app/Contents/Resources/TypeMark/Docs/img/006tNbRwly1fw6nu5yishj31kw0w04cm.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qGWVgGhG-1595768814174)(https://ws2.sinaimg.cn/large/...]
){kind=link}
从下至上:
1、部署:Flink 支持本地运行、能在独立集群或者在被 YARN 或 Mesos 管理的集群上运行, 也能部署在云上。
2、运行:Flink 的核心是分布式流式数据引擎,意味着数据以一次一个事件的形式被处理。
3、API:DataStream、DataSet、Table、SQL API。
4、扩展库:Flink 还包括用于复杂事件处理,机器学习,图形处理和 Apache Storm 兼容性的专用代码库。
3. Flink 数据流编程模型
1. 抽象级别
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yZWEXSka-1595768814175)(https://ws2.sinaimg.cn/large/...]
){kind=link}
- 最底层提供了有状态流。它将通过 过程函数(Process Function)嵌入到 DataStream API 中。它允许用户可以自由地处理来自一个或多个流数据的事件,并使用一致、容错的状态。除此之外,用户可以注册事件时间和处理事件回调,从而使程序可以实现复杂的计算。
- DataStream / DataSet API 是 Flink 提供的核心 API ,DataSet 处理有界的数据集,DataStream 处理有界或者无界的数据流。用户可以通过各种方法(map / flatmap / window / keyby / sum / max / min / avg / join 等)将数据进行转换 / 计算。
- Table API 是以 表 为中心的声明式 DSL,其中表可能会动态变化(在表达流数据时)。Table API 提供了例如 select、project、join、group-by、aggregate 等操作,使用起来却更加简洁(代码量更少)。
你可以在表与 DataStream/DataSet 之间无缝切换,也允许程序将 Table API 与 DataStream 以及 DataSet 混合使用。
- Flink 提供的最高层级的抽象是 SQL 。这一层抽象在语法与表达能力上与 Table API 类似,但是是以 SQL查询表达式的形式表现程序。SQL 抽象与 Table API 交互密切,同时 SQL 查询可以直接在 Table API 定义的表上执行。
2. Flink 程序与数据流结构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j4U1eMhC-1595768814176)(https://ws1.sinaimg.cn/large/...]
){kind=link}
Flink 应用程序结构就是如上图所示:
1、Source: 数据源,Flink 在流处理和批处理上的 source 大概有 4 类:基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、Apache NiFi 等,当然你也可以定义自己的 source。
2、Transformation:数据转换的各种操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select / Project 等,操作很多,可以将数据转换计算成你想要的数据。
3、Sink:接收器,Flink 将转换计算后的数据发送的地点 ,你可能需要存储下来,Flink 常见的 Sink 大概有如下几类:写入文件、打印出来、写入 socket 、自定义的 sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 sink。
4. 为什么选择Flink
- Flink 在 JVM 中提供了自己的内存管理,使其独立于 Java 的默认垃圾收集器。 它通过使用散列,索引,缓存和排序有效地进行内存管理。
- Flink 拥有丰富的库来进行机器学习,图形处理,关系数据处理等。 由于其架构,很容易执行复杂的事件处理和警报
- Flink 能满足高并发和低延迟(计算大量数据很快)。下图显示了 Apache Flink 与 Apache Storm 在完成流数据清洗的分布式任务的性能对比。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4Tz386WK-1595768814177)(https://ws3.sinaimg.cn/large/...]
){kind=link}
- Flink 保证状态化计算强一致性。”状态化“意味着应用可以维护随着时间推移已经产生的数据聚合或者,并且 Filnk 的检查点机制在一次失败的事件中一个应用状态的强一致性。
- Flink 支持流式计算和带有事件时间语义的视窗。事件时间机制使得那些事件无序到达甚至延迟到达的数据流能够计算出精确的结果。
- 除了提供数据驱动的视窗外,Flink 还支持基于时间,计数,session 等的灵活视窗。视窗能够用灵活的触发条件定制化从而达到对复杂的流传输模式的支持。Flink 的视窗使得模拟真实的创建数据的环境成为可能
- Flink 的容错能力是轻量级的,允许系统保持高并发,同时在相同时间内提供强一致性保证。Flink 以零数据丢失的方式从故障中恢复,但没有考虑可靠性和延迟之间的折衷。
- Flink 保存点提供了一个状态化的版本机制,使得能以无丢失状态和最短停机时间的方式更新应用或者回退历史数据。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6QPM1ZUj-1595768814178)(https://ws1.sinaimg.cn/large/...]
){kind=link}
- ........
5. 搭建Flink环境并运行简单程序
1. 安装Flink
通过 homebrew 来安装。
brew install apache-flink
2. 检查是否安装成功
flink -v
3. 启动Flink
进入到:/usr/local/Cellar/apache-flink/1.7.1/libexec/bin
./start-cluster.sh
4. 启动成功
访问http://localhost:8081/#/overview
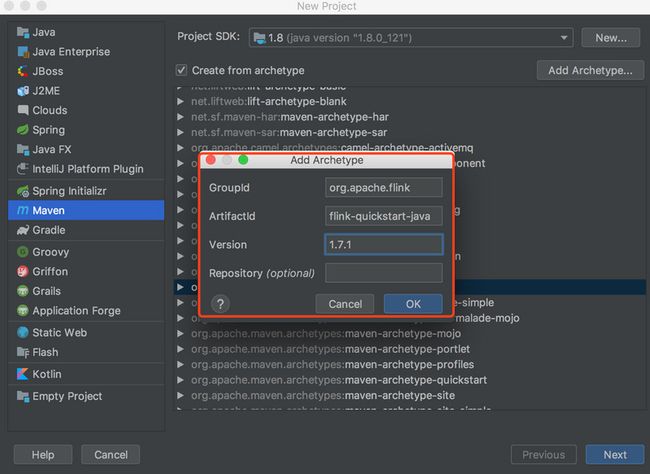
5. 新建maven项目
GroupId=org.apache.flink
ArtifactId=flink-quickstart-java
Version=1.6.1
- 创建一个 SocketTextStreamWordCount 文件,加入以下代码:
package study;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author wangjun
* @date 2019/03/25
*/
public class SocketTextStreamWordCount {
public static void main(String[] args) throws Exception {
//参数检查
if (args.length != 2) {
System.err.println("USAGE:\nSocketTextStreamWordCount ");
return;
}
String hostname = args[0];
Integer port = Integer.parseInt(args[1]);
// set up the streaming execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据
DataStreamSource stream = env.socketTextStream(hostname, port);
//计数
SingleOutputStreamOperator> sum = stream.flatMap(new LineSplitter())
.keyBy(0)
.sum(1);
sum.print();
env.execute("Java WordCount from SocketTextStream Example");
}
public static final class LineSplitter implements FlatMapFunction> {
@Override
public void flatMap(String s, Collector> collector) {
String[] tokens = s.toLowerCase().split("\\W+");
for (String token: tokens) {
if (token.length() > 0) {
collector.collect(new Tuple2(token, 1));
}
}
}
}
} - 接着进入工程目录,使用以下命令打包
mvn clean package -Dmaven.test.skip=true
- 开启监听 9000 端口:
nc -l 9000
- 进入 flink 安装目录 bin 下执行以下命令跑程序
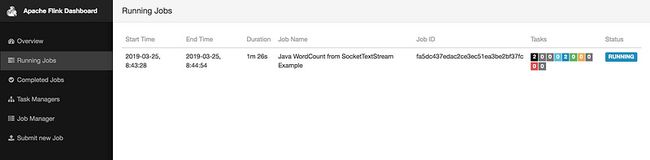
flink run -c study.SocketTextStreamWordCount /Users/wangjun/timwang/codeArea/study/target/original-study-1.0-SNAPSHOT.jar 127.0.0.1 9000
- 我们可以在 webUI 中看到正在运行的程序
- 可以在 nc 监听端口中输入 text,比如

- 然后我们通过 tail 命令看一下输出的 log 文件,来观察统计结果。进入目录 apache-flink/1.6.0/libexec/log,执行以下命令:
tail -f flink-wangjun-taskexecutor-0-wangjundeMBP.out

6. Data Source介绍
数据来源,Flink 做为一款流式计算框架,它可用来做批处理,即处理静态的数据集、历史的数据集;也可以用来做流处理,即实时的处理些实时数据流,实时的产生数据流结果,只要数据源源不断的过来,Flink 就能够一直计算下去,这个 Data Sources 就是数据的来源地。
Flink 中你可以使用 StreamExecutionEnvironment.addSource(sourceFunction) 来为你的程序添加数据来源。
Flink 已经提供了若干实现好了的 source functions,当然你也可以通过实现 SourceFunction 来自定义非并行的 source 或者实现 ParallelSourceFunction 接口或者扩展 RichParallelSourceFunction 来自定义并行的 source,
1. Flink数据来源
StreamExecutionEnvironment 中可以使用以下几个已实现的 stream sources,
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9Jk36Myp-1595768814183)(https://ws4.sinaimg.cn/large/...]
){kind=link}
a. 基于集合
1、fromCollection(Collection) - 从 Java 的 Java.util.Collection 创建数据流。集合中的所有元素类型必须相同。
2、fromCollection(Iterator, Class) - 从一个迭代器中创建数据流。Class 指定了该迭代器返回元素的类型。
3、fromElements(T …) - 从给定的对象序列中创建数据流。所有对象类型必须相同。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream input = env.fromElements(
new Person(1, "name", 12),
new Person(2, "name2", 13),
new Person(3, "name3", 14)
); 4、fromParallelCollection(SplittableIterator, Class) - 从一个迭代器中创建并行数据流。Class 指定了该迭代器返回元素的类型。
5、generateSequence(from, to) - 创建一个生成指定区间范围内的数字序列的并行数据流。
b. 基于文件
1、readTextFile(path) - 读取文本文件,即符合 TextInputFormat 规范的文件,并将其作为字符串返回。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream text = env.readTextFile("file:///path/to/file"); 2、readFile(fileInputFormat, path) - 根据指定的文件输入格式读取文件(一次)。
3、readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo) - 这是上面两个方法内部调用的方法。它根据给定的 fileInputFormat 和读取路径读取文件。根据提供的 watchType,这个 source 可以定期(每隔 interval 毫秒)监测给定路径的新数据(FileProcessingMode.PROCESS_CONTINUOUSLY),或者处理一次路径对应文件的数据并退出(FileProcessingMode.PROCESS_ONCE)。你可以通过 pathFilter 进一步排除掉需要处理的文件。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream stream = env.readFile(
myFormat, myFilePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 100,
FilePathFilter.createDefaultFilter(), typeInfo); c. 基于 Socket:
socketTextStream(String hostname, int port) - 从 socket 读取。元素可以用分隔符切分。
d. 自定义
addSource - 添加一个新的 source function。例如,你可以 addSource(new FlinkKafkaConsumer011<>(…)) 以从 Apache Kafka 读取数据
package study;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
/**
* @author wangjun
* @date 2019/3/25
*/
public class SourceFromMySQL extends RichSourceFunction {
private PreparedStatement ps;
private Connection connection;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
connection = getConnection();
String sql = "select * from student;";
ps = this.connection.prepareStatement(sql);
}
@Override
public void close() throws Exception {
super.close();
if (connection != null) {
connection.close();
}
if (ps != null) {
ps.close();
}
}
@Override
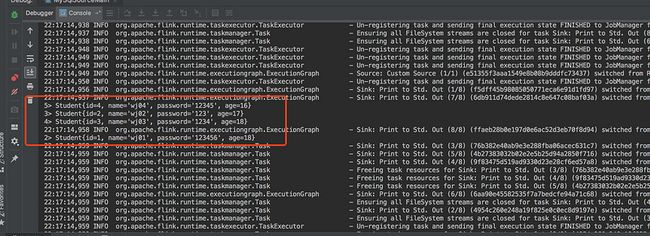
public void run(SourceContext ctx) throws Exception {
ResultSet resultSet = ps.executeQuery();
while (resultSet.next()) {
Student student = new Student(
resultSet.getInt("id"),
resultSet.getString("name").trim(),
resultSet.getString("password").trim(),
resultSet.getInt("age"));
ctx.collect(student);
}
}
@Override
public void cancel() {
}
private static Connection getConnection() {
Connection con = null;
try {
Class.forName("com.mysql.jdbc.Driver");
con = DriverManager.getConnection("jdbc:mysql://localhost:3306/cloud?useUnicode=true&characterEncoding=UTF-8", "root", "123456");
} catch (Exception e) {
System.out.println("-----------mysql get connection has exception , msg = "+ e.getMessage());
}
return con;
}
} package study;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author wangjun
* @date 2019/3/25
*/
public class MySqlSourceMain {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.addSource(new SourceFromMySQL()).print();
env.execute("Flink add data source");
}
}
2. 几种数据源特点
1、基于集合:有界数据集,更偏向于本地测试用
2、基于文件:适合监听文件修改并读取其内容
3、基于 Socket:监听主机的 host port,从 Socket 中获取数据
4、自定义 addSource:大多数的场景数据都是无界的,会源源不断的过来。比如去消费 Kafka 某个 topic 上的数据,这时候就需要用到这个 addSource,可能因为用的比较多的原因吧,Flink 直接提供了 FlinkKafkaConsumer011 等类可供你直接使用。你可以去看看 FlinkKafkaConsumerBase 这个基础类,它是 Flink Kafka 消费的最根本的类。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SS0BBXqM-1595768814185)(https://ws4.sinaimg.cn/large/...]
){kind=link}
7. 实例-计算热门商品数据
本案例将实现一个“实时热门商品”的需求,每隔 5 分钟输出最近一小时内点击量最多的前 N 个商品。将这个需求进行分解
我们大概要做这么几件事情:
• 抽取出业务时间戳,告诉 Flink 框架基于业务时间做窗口
• 过滤出点击行为数据
• 按一小时的窗口大小,每 5 分钟统计一次,做滑动窗口聚合( Sliding Window)
• 按每个窗口聚合,输出每个窗口中点击量前 N 名的商品
1. 数据准备
这里我们准备了一份淘宝用户行为数据集(来自阿里云天池公开数据集)。本数据集包含了淘宝上某一天随机一百万用户的所有行为(包括点击、购买、加购、收藏)。数据集的组织形式和 MovieLens-20M 类似,即数据集的每一行表示一条用户行为,由用户 ID、商品 ID、商品类目 ID、行为类型和时间戳组成,并以逗号分隔。关于数据集中每一列的详细描述如下:

curl https://raw.githubusercontent... UserBehavior.csv
2. 开发
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 为了打印到控制台的结果不乱序,我们配置全局的并发为 1,这里改变并发对结果正确性没有影响
env.setParallelism(1);
// UserBehavior.csv 的本地文件路径
URL fileUrl = HotItems.class.getClassLoader().getResource("UserBehavior.csv");
Path filePath = Path.fromLocalFile(new File(fileUrl.toURI()));
// 抽取 UserBehavior 的 TypeInformation,是一个 PojoTypeInfo
PojoTypeInfo pojoType = (PojoTypeInfo)
TypeExtractor.createTypeInfo(UserBehavior.class);
// 由于 Java 反射抽取出的字段顺序是不确定的,需要显式指定下文件中字段的顺序
String[] fieldOrder = new String[]{"userId", "itemId", "categoryId", "behavior", "timestamp"};
// 创建 PojoCsvInputFormat
PojoCsvInputFormat csvInput = new PojoCsvInputFormat<>(filePath, pojoType, fieldOrder);
// PojoCsvInputFormat 创建输入源。
DataStream dataSource = env.createInput(csvInput, pojoType); 3. 创建模拟数据源
CsvInputFormat 创建模拟数据源。我们先创建一个 UserBehavior 的 POJO 类(所有成员变量声明成 public 便是 POJO 类),强类
型化后能方便后续的处理
package study.goods;
import java.io.Serializable;
/**
* @author wangjun
* @date 2019/3/26
*/
public class UserBehavior implements Serializable {
/**
* 用户 ID
*/
public long userId;
/**
* 商品 ID
*/
public long itemId;
/**
* 商品类目 ID
*/
public int categoryId;
/**
* 用户行为, 包括("pv", "buy", "cart", "fav")
*/
public String behavior;
/**
* 行为发生的时间戳,单位秒
*/
public long timestamp;
public long getUserId() {
return userId;
}
public void setUserId(long userId) {
this.userId = userId;
}
public long getItemId() {
return itemId;
}
public void setItemId(long itemId) {
this.itemId = itemId;
}
public int getCategoryId() {
return categoryId;
}
public void setCategoryId(int categoryId) {
this.categoryId = categoryId;
}
public String getBehavior() {
return behavior;
}
public void setBehavior(String behavior) {
this.behavior = behavior;
}
public long getTimestamp() {
return timestamp;
}
public void setTimestamp(long timestamp) {
this.timestamp = timestamp;
}
} 当我们说“统计过去一小时内点击量”,这里的“一小时”是指什么呢? 在 Flink 中它可以是指 ProcessingTime ,也可以是 EventTime,由用户决定。
• ProcessingTime:事件被处理的时间。也就是由机器的系统时间来决定。
• EventTime:事件发生的时间。一般就是数据本身携带的时间。
在本案例中,我们需要统计业务时间上的每小时的点击量,所以要基于 EventTime 来处理。那么如果让 Flink 按照我们想要的业务时间来处理呢?这里主要有两件事情要做。
第一件是告诉 Flink 我们现在按照 EventTime 模式进行处理, Flink 默认使用 ProcessingTime处理,所以我们要显式设置下。
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); 第二件事情是指定如何获得业务时间,以及生成 Watermark。 Watermark 是用来追踪业务事件的概念,可以理解成 EventTime 世界中的时钟,用来指示当前处理到什么时刻的数据了。由于我们的数据源的数据已经经过整理,没有乱序,即事件的时间戳是单调递增的,所以可以将每条数据的业务时间就当做 Watermark。这里我们用 AscendingTimestampExtractor 来实现时间戳的抽取和 Watermark 的生成。
// 这样我们就得到了一个带有时间标记的数据流了,后面就能做一些窗口的操作
DataStream timedData = dataSource.assignTimestampsAndWatermarks(new AscendingTimestampExtractor() {
@Override
public long extractAscendingTimestamp(UserBehavior userBehavior) {
// 原始数据单位秒,将其转成毫秒
return userBehavior.timestamp * 1000;
}
}); 在开始窗口操作之前,先回顾下需求“每隔 5 分钟输出过去一小时内点击量最多的前 N 个商品”。由于原始数据中存在点击、加购、购买、收藏各种行为的数据,但是我们只需要统计点击量,所以先使用 FilterFunction 将点击行为数据过滤出来
DataStream pvData = timedData.filter(new FilterFunction() {
@Override
public boolean filter(UserBehavior userBehavior) throws Exception {
// 过滤出只有点击的数据
return userBehavior.behavior.equals("pv");
}
}); 由于要每隔 5 分钟统计一次最近一小时每个商品的点击量,所以窗口大小是一小时,每隔 5 分钟滑动一次。即分别要统计 [09:00, 10:00), [09:05, 10:05), [09:10, 10:10)... 等窗口的商品点击量。是一个常见的滑动窗口需求( Sliding Window)
DataStream windowedData = pvData.keyBy("itemId")
.timeWindow(Time.minutes(60), Time.minutes(5))
.aggregate(new CountAgg(), new WindowResultFunction()); 我们使用.keyBy("itemId")对商品进行分组,使用.timeWindow(Time size, Time slide)对每个 商 品 做 滑 动 窗 口 (1 小 时 窗 口 , 5 分 钟 滑 动 一 次 )。 然 后 我 们 使用 .aggregate(AggregateFunction af, WindowFunction wf) 做增量的聚合操作,它能使用AggregateFunction 提前聚合掉数据,减少 state 的存储压力。较之.apply(WindowFunction wf)会将窗口中的数据都存储下来,最后一起计算要高效地多。aggregate()方法的第一个参数用于
这里的 CountAgg 实现了 AggregateFunction 接口,功能是统计窗口中的条数,即遇到一条数据就加一。
package study.goods;
import org.apache.flink.api.common.functions.AggregateFunction;
/**
* COUNT 统计的聚合函数实现,每出现一条记录加一
* @author wangjun
* @date 2019/3/26
*/
public class CountAgg implements AggregateFunction {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(UserBehavior userBehavior, Long acc) {
return acc + 1;
}
@Override
public Long getResult(Long acc) {
return acc;
}
@Override
public Long merge(Long acc1, Long acc2) {
return acc1 + acc2;
}
} aggregate(AggregateFunction af, WindowFunction wf)的第二个参数 WindowFunction 将每个 key 每个窗口聚合后的结果带上其他信息进行输出。我们这里实现的 WindowResultFunction将主键商品 ID,窗口,点击量封装成了 ItemViewCount 进行输出。
package study.goods;
/**
* @author wangjun
* @date 2019/3/26
*/
public class ItemViewCount {
public long itemId; // 商品 ID
public long windowEnd; // 窗口结束时间戳
public long viewCount; // 商品的点击量
public static ItemViewCount of(long itemId, long windowEnd, long viewCount) {
ItemViewCount result = new ItemViewCount();
result.itemId = itemId;
result.windowEnd = windowEnd;
result.viewCount = viewCount;
return result;
}
}现在我们得到了每个商品在每个窗口的点击量的数据流。
为了统计每个窗口下最热门的商品,我们需要再次按窗口进行分组,这里根据 ItemViewCount中的 windowEnd 进行 keyBy()操作。然后使用 ProcessFunction 实现一个自定义的 TopN 函数TopNHotItems来计算点击量排名前 3名的商品,并将排名结果格式化成字符串,便于后续输出。
DataStream topItems = windowedData
.keyBy("windowEnd")
.process(new TopNHotItems(3)); // 求点击量前 3 名的商品 ProcessFunction 是 Flink 提供的一个 low-level API,用于实现更高级的功能。它主要提供了定时器 timer 的功能(支持 EventTime 或 ProcessingTime)。本案例中我们将利用 timer 来判断何时收齐了某个 window 下所有商品的点击量数据。由于 Watermark 的进度是全局的,
在 processElement 方法中,每当收到一条数据( ItemViewCount),我们就注册一个 windowEnd+1的定时器( Flink 框架会自动忽略同一时间的重复注册)。 windowEnd+1 的定时器被触发时,意味着收到了 windowEnd+1 的 Watermark,即收齐了该 windowEnd 下的所有商品窗口统计值。我
们在 onTimer()中处理将收集的所有商品及点击量进行排序,选出 TopN,并将排名信息格式化成字符串后进行输出。
这里我们还使用了 ListState
package study.goods;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import java.sql.Timestamp;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
/**
* @author wangjun
* @date 2019/3/26
*/
public class TopNHotItems extends KeyedProcessFunction {
private final int topSize;
// 用于存储商品与点击数的状态,待收齐同一个窗口的数据后,再触发 TopN 计算
private ListState itemState;
public TopNHotItems(int topSize) {
this.topSize = topSize;
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// 状态的注册
ListStateDescriptor itemsStateDesc = new ListStateDescriptor<>(
"itemState-state",
ItemViewCount.class);
itemState = getRuntimeContext().getListState(itemsStateDesc);
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector out) throws Exception {
// 获取收到的所有商品点击量
List allItems = new ArrayList<>();
for (ItemViewCount item : itemState.get()) {
allItems.add(item);
}
// 提前清除状态中的数据,释放空间
itemState.clear();
// 按照点击量从大到小排序
allItems.sort(new Comparator() {
@Override
public int compare(ItemViewCount o1, ItemViewCount o2) {
return (int) (o2.viewCount - o1.viewCount);
}
});
// 将排名信息格式化成 String, 便于打印
StringBuilder result = new StringBuilder();
result.append("====================================\n");
result.append("时间: ").append(new Timestamp(timestamp - 1)).append("\n");
for (int i = 0; i < topSize; i++) {
ItemViewCount currentItem = allItems.get(i);
// No1: 商品 ID=12224 浏览量=2413
result.append("No").append(i).append(":")
.append(" 商品 ID=").append(currentItem.itemId)
.append(" 浏览量=").append(currentItem.viewCount)
.append("\n");
}
result.append("====================================\n\n");
out.collect(result.toString());
}
@Override
public void processElement(ItemViewCount input, Context context, Collector collector) throws Exception {
// 每条数据都保存到状态中
itemState.add(input);
// 注册 windowEnd+1 的 EventTime Timer, 当触发时,说明收齐了属于 windowEnd 窗口的所有商品数据
context.timerService().registerEventTimeTimer(input.windowEnd + 1);
}
}