Spark中使用UDF函数、zipWithIndex配合Array数组来对Vector类的列进行分割,实现聚类中心读取为DataFrame
简介
使用的数据集是UCI提供的Machine-Learning-Databases数据集。
本篇博客的内容是笔者在输出聚类中心信息时实践所得:
- 由于在ml中得到的聚类中心是Array[Vector]类的数据,Array中保存每个聚类中心的数据,Vector记录每个聚类中心的每个维度,很难将其读入DataFrame,本篇文章通过rdd作为中介来将其成功转换。
- 而对于每个聚类中心的数据,如果根据所需将其分割成不同列表,每个列表记录一个维度的信息,再将其反索引得到文字信息就是能显著提高可读性。
主要讲解的内容如下:
- User-defined function类函数的定义与使用
- 使用zipWithIndex来对Array类表格进行分割操作
- Attribute类的理解及应用
- 通过RDD的中转实现Array类读取为Dataframe
github地址:Truedick23 - AdultBase
配置
- 语言:Scala 2.11
- Spark版本:Spark 2.3.1
类型介绍
User-defined function
维基百科对其定义如下:User-defined function - Wikipedia
A user-defined function (UDF) is a function provided by the user of a program or environment, in a context where the usual assumption is that functions are built into the program or environment.
由此定义可知,udf函数是由用户提供的一类函数,与其对应的是程序定义的函数,这一类函数可以实现一般语法难以实现的功能,常用以实现类型转换等。
对于Spark的实现我们可以查看其对应的Spark文档:
Spark 2.3.2 ScalaDoc - UserDefinedFunction
以下代码实现将features这一列的数据由Vector类转化为Array类:
val vecToArray = udf( (xs: Vector) => xs.toArray )
val dfArr = cluster_table.withColumn("featuresArray" , vecToArray($"features") )
前后效果对比如下:
+--------------------+
| features|
+--------------------+
|[37.0,7.0,13.0,5....|
|[57.0,7.0,12.0,5....|
|[46.0,7.0,13.0,5....|
|[21.0,7.0,13.0,5....|
|[49.0,7.0,11.0,5....|
|[70.0,6.0,11.0,5....|
|[29.0,7.0,13.0,5....|
|[29.0,7.0,12.0,5....|
+--------------------+
+-----------------------------------------+-------------------------------------------------+
|features |featuresArray |
+-----------------------------------------+-------------------------------------------------+
|[37.0,7.0,13.0,5.0,10.0,4.0,4.0,1.0,41.0]|[37.0, 7.0, 13.0, 5.0, 10.0, 4.0, 4.0, 1.0, 41.0]|
|[57.0,7.0,12.0,5.0,10.0,4.0,4.0,1.0,41.0]|[57.0, 7.0, 12.0, 5.0, 10.0, 4.0, 4.0, 1.0, 41.0]|
|[46.0,7.0,13.0,5.0,10.0,4.0,4.0,1.0,41.0]|[46.0, 7.0, 13.0, 5.0, 10.0, 4.0, 4.0, 1.0, 41.0]|
|[21.0,7.0,13.0,5.0,9.0,3.0,4.0,1.0,41.0] |[21.0, 7.0, 13.0, 5.0, 9.0, 3.0, 4.0, 1.0, 41.0] |
|[49.0,7.0,11.0,5.0,10.0,4.0,3.0,1.0,20.0]|[49.0, 7.0, 11.0, 5.0, 10.0, 4.0, 3.0, 1.0, 20.0]|
|[70.0,6.0,11.0,5.0,9.0,4.0,4.0,1.0,40.0] |[70.0, 6.0, 11.0, 5.0, 9.0, 4.0, 4.0, 1.0, 40.0] |
|[29.0,7.0,13.0,5.0,10.0,4.0,4.0,1.0,41.0]|[29.0, 7.0, 13.0, 5.0, 10.0, 4.0, 4.0, 1.0, 41.0]|
|[29.0,7.0,12.0,5.0,10.0,3.0,3.0,1.0,19.0]|[29.0, 7.0, 12.0, 5.0, 10.0, 3.0, 3.0, 1.0, 19.0]|
+-----------------------------------------+-------------------------------------------------+
具体的实践我们根据实际应用
zipWithIndex
zipWithIndex这一函数可以在访问数组元素的同时获得一个从0开始的计数器,
示例如下:
days.zipWithIndex.foreach {
case(day, count) => println(s"$count is $day")
}
输出以下数据:
0 is Sunday
1 is Monday
2 is Tuesday
3 is Wednesday
4 is Thursday
5 is Friday
6 is Saturday
对其原理进行分析,zipWithIndex产生一个二元元组的数组,元组内第一个值为原数组的每一项,第二项为计数器
Array((Sunday,0), (Monday,1), ...
通过这个函数我们可以很方便地链接两个数组,即通过第二个计数器作为另一个数组的索引值,对其进行访问
以下代码实现了将featuresArray这一数组类表格列按照info_elements分割成若干列
val info_elements = Array("age", "workclassIndex", "educationIndex", "maritial_statusIndex",
"occupationIndex", "relationshipIndex", "raceIndex", "sexIndex", "native_countryIndex")
val sqlExpr = info_elements.zipWithIndex.map{ case (alias, idx) =>
col("featuresArray").getItem(idx).as(alias) }
val split_table = dfArr.select(sqlExpr : _*)
效果如下:
+-------------------------------------------------+
|featuresArray |
+-------------------------------------------------+
|[37.0, 7.0, 13.0, 5.0, 10.0, 4.0, 4.0, 1.0, 41.0]|
|[57.0, 7.0, 12.0, 5.0, 10.0, 4.0, 4.0, 1.0, 41.0]|
|[46.0, 7.0, 13.0, 5.0, 10.0, 4.0, 4.0, 1.0, 41.0]|
|[21.0, 7.0, 13.0, 5.0, 9.0, 3.0, 4.0, 1.0, 41.0] |
|[49.0, 7.0, 11.0, 5.0, 10.0, 4.0, 3.0, 1.0, 20.0]|
|[70.0, 6.0, 11.0, 5.0, 9.0, 4.0, 4.0, 1.0, 40.0] |
|[29.0, 7.0, 13.0, 5.0, 10.0, 4.0, 4.0, 1.0, 41.0]|
|[29.0, 7.0, 12.0, 5.0, 10.0, 3.0, 3.0, 1.0, 19.0]|
+-------------------------------------------------+
+----+--------------+--------------+--------------------+---------------+-----------------+---------+--------+-------------------+
|age |workclassIndex|educationIndex|maritial_statusIndex|occupationIndex|relationshipIndex|raceIndex|sexIndex|native_countryIndex|
+----+--------------+--------------+--------------------+---------------+-----------------+---------+--------+-------------------+
|37.0|7.0 |13.0 |5.0 |10.0 |4.0 |4.0 |1.0 |41.0 |
|57.0|7.0 |12.0 |5.0 |10.0 |4.0 |4.0 |1.0 |41.0 |
|46.0|7.0 |13.0 |5.0 |10.0 |4.0 |4.0 |1.0 |41.0 |
|21.0|7.0 |13.0 |5.0 |9.0 |3.0 |4.0 |1.0 |41.0 |
|49.0|7.0 |11.0 |5.0 |10.0 |4.0 |3.0 |1.0 |20.0 |
|70.0|6.0 |11.0 |5.0 |9.0 |4.0 |4.0 |1.0 |40.0 |
|29.0|7.0 |13.0 |5.0 |10.0 |4.0 |4.0 |1.0 |41.0 |
|29.0|7.0 |12.0 |5.0 |10.0 |3.0 |3.0 |1.0 |19.0 |
+----+--------------+--------------+--------------------+---------------+-----------------+---------+--------+-------------------+
Attribute
Attribute是用于定义其他类型数据的一种数据类型,可以用于规定特定数据类型的数值,它也可以称作元数据(Metadata “data [information] that provides information about other data”),它还可以用于规定其他类型数据可进行的操作。
在Spark中定义了Attribute类:
Spark 2.3.2 ScalaDoc - Attribute
其包含以下子类:
BinaryAttribute, NominalAttribute, NumericAttribute, UnresolvedAttribute
以下代码使用了NumericAttribute,即用于描述某一类的数值信息:
val defaultAttr = NumericAttribute.defaultAttr
val attrs = Array("age", "workclassIndex", "educationIndex", "maritial_statusIndex",
"occupationIndex", "relationshipIndex", "raceIndex", "sexIndex", "native_countryIndex")
.map(defaultAttr.withName)
val attrGroup = new AttributeGroup("features", attrs.asInstanceOf[Array[Attribute]])
使用SparkContext来得到RDD,辅助取得DataFrame
如简介所讲,笔者想通过DataFrame来格式化表示聚类中心,通过查看文档看到createDataFrame函数有如下定义:
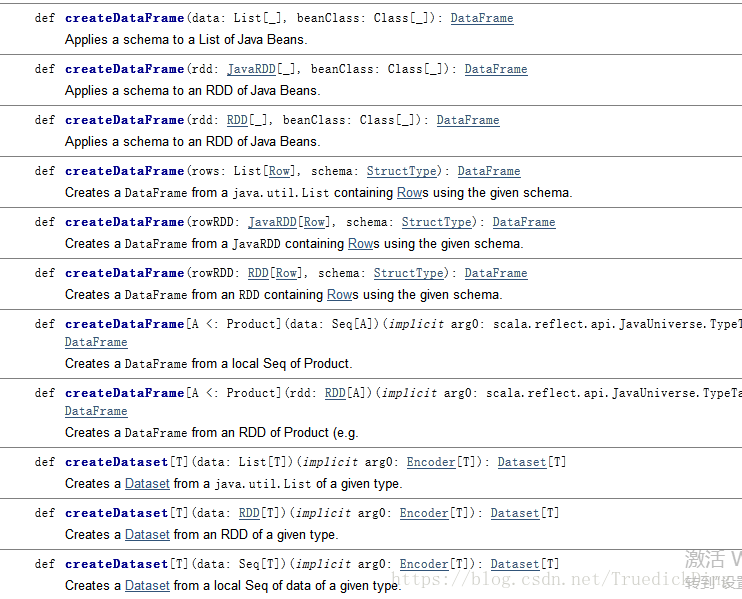
在其中找不到我所需要的重载,用以实现从Array到DataFrame的转换,故笔者转而寻求RDD作为过渡,注意到SparkContext提供了parallelize函数:
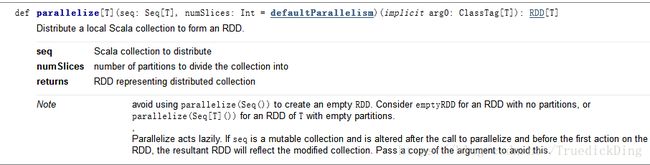
它可以将Array[Row[DenseVector]]类的数据转化为RDD。
我们使用之前定义的attrGroup来调用createDataFrame:
val clusters = model.clusterCenters
.map(fields => Row(Vectors.dense(fields.toArray.map(num => math.round(num).toDouble))))
val clusters_dt = spark.sparkContext.parallelize(clusters)
val cluster_table =
spark.createDataFrame(clusters_dt, StructType(Array(attrGroup.toStructField())))
成功创建:
+--------------------+
| features|
+--------------------+
|[37.0,7.0,13.0,5....|
|[57.0,7.0,12.0,5....|
|[46.0,7.0,13.0,5....|
|[21.0,7.0,13.0,5....|
|[49.0,7.0,11.0,5....|
|[70.0,6.0,11.0,5....|
|[29.0,7.0,13.0,5....|
|[29.0,7.0,12.0,5....|
+--------------------+
综合运用实现
使用之前介绍的类型的组装,成功将聚类中心通过DataFrame输出:
val info_elements = Array("age", "workclassIndex", "educationIndex", "maritial_statusIndex",
"occupationIndex", "relationshipIndex", "raceIndex", "sexIndex", "native_countryIndex")
val clusters = model.clusterCenters
.map(fields => Row(Vectors.dense(fields.toArray.map(num => math.round(num).toDouble))))
val clusters_dt = spark.sparkContext.parallelize(clusters)
val cluster_table =
spark.createDataFrame(clusters_dt, StructType(Array(attrGroup.toStructField())))
cluster_table.show()
val vecToArray = udf( (xs: Vector) => xs.toArray )
val dfArr = cluster_table.withColumn("featuresArray" , vecToArray($"features") )
dfArr.select("featuresArray").show(truncate = false)
val sqlExpr = info_elements.zipWithIndex.map{ case (alias, idx) =>
col("featuresArray").getItem(idx).as(alias) }
val split_table = dfArr.select(sqlExpr : _*)
split_table.show(truncate = false)
val cluster_info_split_table = getConverterPipline
.fit(split_table).transform(split_table).select("age", "workclass", "education", "maritial_status",
"occupation", "relationship", "race", "sex")
其中关于IndexToString的使用欢迎参考并斧正笔者之前的博文Spark SQL中使用StringIndexer和IndexToString来对字符串信息进行索引和反索引
输出结果如下:
+----+--------------+--------------+--------------------+---------------+-----------------+----+----------------+---------+---------------+-------------+-------------+-----+----+
|age |workclass |education|maritial_status|occupation |relationship |race |sex |
+----+----------------+---------+---------------+-------------+-------------+-----+----+
|37.0|Self-emp-not-inc|Bachelors|Never-married |Sales |Not-in-family|White|Male|
|57.0|Self-emp-not-inc|Masters |Never-married |Sales |Not-in-family|White|Male|
|46.0|Self-emp-not-inc|Bachelors|Never-married |Sales |Not-in-family|White|Male|
|21.0|Self-emp-not-inc|Bachelors|Never-married |Other-service|Own-child |White|Male|
|49.0|Self-emp-not-inc|Assoc-voc|Never-married |Sales |Not-in-family|Black|Male|
|70.0|Local-gov |Assoc-voc|Never-married |Other-service|Not-in-family|White|Male|
|29.0|Self-emp-not-inc|Bachelors|Never-married |Sales |Not-in-family|White|Male|
|29.0|Self-emp-not-inc|Masters |Never-married |Sales |Own-child |Black|Male|
+----+----------------+---------+---------------+-------------+-------------+-----+----+
大功告成!
参考资料
- User-defined function - Wikipedia
- Create User-defined Functions (Database Engine)
- Spark 2.3.2 ScalaDoc - User-defined function
- Scala Tutorial - Learn How To Use ZipWithIndex Function With Examples
- 10.11. Using zipWithIndex or zip to Create Loop Counters
- Attribute (computing) - Wikipedia
- Metadata - Wikipedia
- Spark 2.3.2 ScalaDoc - NumericAttribute