DataOps,面向data的ops?No! 它是面向商业逻辑的ops
DevOps近几年可谓风生水起,这与它吸引人的使命有关-提升产品研发迭代的速度,当然也不能忽略历史的进程,比如虚拟化(尤其是Docker)技术的加持!
大数据(或团队)一般在前方业务线的存在感普遍偏较弱,甚至得不到认可,有时候还不如一个有经验的运营专员,何其怪哉?!在此,我们借助正在悄然兴起的DataOps来一并分析问题出在哪里,如何解决,需要什么客观条件的支持。

DataOps不是穿凿附会-类比与对偶
他山之石,可以攻玉。咱们首先粗看一下物理学界是如何做学问的,类比法是自然界一个神奇的现象,它跨越了微观与宏观、跨越数学形式而存在:
经典的,比如麦克斯韦方程:电与磁研究
量子力学中,基础概念对易子与经典力学中的泊松括号有可以类比的性质
相对论中,经典的泊松方程与广义相对论场方程有可类比的性质
狄拉克和爱因斯坦就是分别从泊松括号和泊松方程出发,通过“对比-拼凑”的方式,构建了量子力学和相对论的基础理论,由此开启了20世纪波澜壮阔的物理时代。看下这一组:

重点关注上面这组公式的右端,是不是已经发现一些端倪。
爱大神捣鼓引力场方程六七年,事情并未有条不紊的进展。眼看要功败垂成于一个普适的场景-“能量场”,突然关注到泊松方程,基于爱大神天才的洞察力,由对偶性马上就“凑”出了他的方程式,到这里才算是一气呵成。
过上面的简单例子发现,由类比原则出发,来探求新事物的特性/本质是一种重要的科学手段,在基础科学中甚至已经成为科学家们的主要手段。
严谨科学界都如此,我们当然有理由通过这个手段,把工程研发领域的DevOps理念应用到大数据领域,按照类比原则,来考察一下,大数据领域是否有未发现根本特征。
先说DevOps是什么
有时候,从目标出发比从定义出发,更容易理解DevOps是什么:缩短工程研发到上线的周期和迭代频率。
为了达成此目的,就需要一整套工具链的支撑,涵盖了代码的持续集成、测试、打包与发布、配置与监控等环节。
DevOps是一种新的研发方法论和工作方式。在不同的环节辅之以必要的工具支撑,尽可能消除研发到上线的冗余工作和依赖,如:
代码版本管理
打包编译器和环境管理
自动回归测试管理
代码上线与回滚管理
自动测试环境管理
监控报警等等
从另一个角度看,DevOps也是重构出了一种跨职能的新工作模式。
大数据里的Ops - DataOps
传统概念里,人们习惯于把DataOps与DevOps概念类比,并提出:
摘自wikipedia:
DataOps seeks to integrate data engineering, data integration, data quality, data security, and data privacy with operations....to improve the cycle time of extracting value from data analytics。
通过上面的定义可见,对DataOps的一个观点是:将集数据工程、数据集成、数据质量、数据安全与数据隐私等基础功能集成,并提供可运维的能力,以提升从数据洞察到价值发现的效率。
这种定义无可厚非,并且阿里、腾讯、滴滴等国内互联网巨头已经如此实践多年,但是能不能“提升从数据洞察到价值发现的效率”,可能只有入过坑的同学才知道。
目前常规做法已冠以DataOps的概念,但若我们的认识停留于此,这种跨领域的横向直接对比并未产生什么新东西,还只是简单的概念复制,对于我们今后的工作也没有什么指导意义。
假如爱大神把泊松方程里左侧部分势能的概念硬套到弯曲的时空中一样,必然不会探索到新事物中特有的东西,因为相对论场方程左侧表征的弯曲时空中,势能已经是个多余的概念了,也就不会产生相对论了。所以概念层面的复制不是我们想要的,思维方式才是知识传承的有效方式:)
从他们本身所承载的使命出发,重新审视工程研发和大数据这两种场景:
工程研发,是靠代码来驱动计算机的布尔逻辑 产生预期的逻辑。DevOps是为了解决这个过程中的效率问题,包括组织效率和工程效率。
大数据,是靠 某种能力 驱动业务(商业)逻辑的运转。DataOps是为了解决这个过程中的效率问题(含义同上)。
上面提到的这种能力,就是通过大数据洞察出来的行动建议,任何不闭环到商业逻辑中的大数据,只能演变成成本中心、进而逐渐失去存在感。
Data-driven的业务场景被抽象后发现,数据犹如隐形的指令一样,在特定收益的约束下(如ROI、GMV、DAU等),指示着系统、或运营人员有条不紊的进行相应操作。
通过上面的分析,可以做如下的假设:
隐藏在行动建议背后的商业逻辑,就是一台“机器”,它需要特定的指令来指示其如何运转
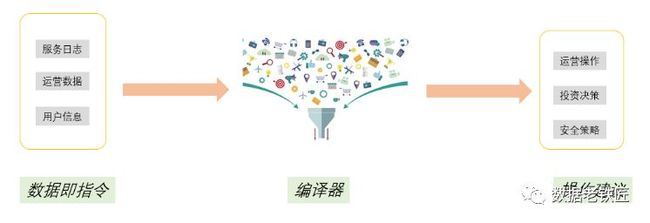
数据,本身就是指令,它指示底层机器(商业逻辑)如何运转
为了让数据能够精确的操作如此复杂的商业机器,就需要原始数据到行动建议之间的桥梁-编译器。就如同传统的 Java/C/C++编译器,最终用户只需要了解上层编程语言,不需要直接用二进制X86指令编程一样。
这台“商业机器”如何运转
编译器,原始数据到行动建议之间的这个桥梁,是这个商业机器的关键。从目前系统的角度来看,他包括数据采集&同步、任务调度、数据质量、监控告警、场景化配置(数据任务开发)等等。
数据,指示机器如何运转的行动建议,在DataOps里,它就是指令,就是“代码”。
在DataOps概念体系下,以往传统的数据开发(如写SQL代码、CNN深度学习代码等)可以理解为"编译器"的场景化配置;而在DevOps则略有不同,在传统工程开发中,主要精力在于工程代码的开发,对编译器的定制相对较少。
注:其实传统工程开发中,对编译器的场景下配置也很多,尤其是商业软件,linux下执行man gcc,就可以看到有多少可选项了,应该有几百上千个...
DataOps运作方式如下:
到此为止,我们发现工程研发与大数据赋能业务是可以做类比和映射的,即他们有相同的基础结构和运转原理。因此,我们可以认为两者在拓扑结构上是同胚的。由于它们的同胚性,我们可以借助已经比较成功的DevOps理论来研究DataOps了(即数据如何高效赋能商业)。
DataOps需要具备的能力
“代码”版本管理
DevOps中,代码的版本管理能力,给团队协作和持续集成提供了强大的工具支持,工程人员可以自行提交、合并、回退代码,无形中极大的提高了研发效率和交付的稳定性。
同样,在DataOps中,“代码”也是需要版本管理的。
不同的是,DataOps中的“代码”指的是数据本身,一个形象的理解就是 :“A/B Test”。
每个“分组”即代表不同的“代码”版本(一套不同的数据集),通过验证,找到效果最好的版本进一步提交(推广),而其他版本则回退或丢弃。
我们总是希望大数据可以发掘出商业中潜在的价值,但在实际的操作中,大部分工作方式还是“试试看”,上线-效果不理想-改改-再来一次。慢不说,即使有点效果,也是根本没法量化的。这就导致在业务线同学的眼中,大数据始终是“nice to have”,而非 “must to have”。
因此在DataOps理念中,版本管理同样扮演非常重要的角色:
通过效果的量化,让大数据融入业务部门决策中
快速找出最佳版本,提升商业迭代的速度
协同办公
DevOps的目的是提升工程研发迭代的速度,靠的是不同环节有机整合的工具链来支撑。DataOps基础设施同理,从数据本身到行动建议,大致上可以划分为:
编译器支持
编译器场景化配置
代码与版本管理
指令系统等模块
这种协同,体现的在工具链建设上,而不是体现在最终用户工作路径上,这是与传统系统建设理念不同的地方。
自助服务
减少不必要的人工干预是提升效率有效手段,因此传统的人工干预和依赖部分需要尽可能的沉淀到工具链中(比如test case),为最终用户提供自助化(self-service)的能力。研发工程师的诉求如此,数据科学家的诉求也是如此。
数据赋能思路的升级
DataOps的理念距离落地还有一定的距离,各个重数据的大厂仍然有传统数据研发惯性的存在,这不妨碍我们用DataOps的思路来看问题。通过前面的讨论,至少我们可以得出两个值得关注的结论:
自助服务是关键。应以最终用户的自助服务为导向,其他环节的因素尽量向工具沉淀
通过价值的量化,可以有效提升迭代速度。如果每一步的价值都可以量化,就可以整体上减少盲目迭代的次数,或及早放弃不可能的尝试。
DataOps没有从数据架构的角度来分析大数据如何赋能业务。因为从数据架构角度来讨论如何赋能,需要时刻考虑与业务逻辑的兼容,是被动的,是滞后的,是无法在业务上取得话语权的。
我们需要重新认识大数据赋能的本质,它不再仅仅是数仓模型与建设、不再仅仅是周报日报、不再仅仅是运营分析,它需要产生可用于行动的指令。我们需要将大数据的能力释放出来,赋能数据科学家(或业务代表),让数据科学家以此为武器,结合上自己在战场上的经验,来取得战斗的胜利。

战场上,可以有分工:军医、补给、通信兵、步兵等。但是分工也需要适可而止:最终子弹上膛、扣动扳机的步兵人员则不需要再分工,这是老幼皆知的道理。
但是到了大数据领域,这个道理就没有那么明显了,通常一个简单的事情需要横跨多个团队来协同完成,我们这个讨论的目的,就是让大家知道,数据科学家(或业务代表)就是商业战场的步兵,所有的后勤、基础建设,都是为了让他们可以一气呵成的完成子弹上膛、扣动扳机。
这就是DataOps需要以自助化服务为出发点的简单原因。
历史好文推荐
如何从0到1搭建大数据平台
从0到1搭建大数据平台之数据采集系统
从0到1搭建大数据平台之调度系统
谈谈ETL中的数据质量
