Python 爬取豆瓣影片短评 生成词云统计
本文介绍利用python爬取豆瓣电影的影片短评,并生成词云和统计数据
github地址:https://github.com/736755244/douban_py
1、基本配置环境
版本:Python3.7
系统:Windows
2、所需模块及作用
以下模块如果没有安装,可以在cmd命令提示符里进行pip install + 模块名 进行安装。
(PS:或者使用清华镜像,速度较快:pip install 模块名 -i https://pypi.tuna.tsinghua.edu.cn/simple)
import requests # 处理网络请求
from bs4 import BeautifulSoup #将HTML转换成树形结构
import time # 时间模块
import random # 随机数
import pandas as pd # 数据分析包
import xlsxwriter # excel相关
from urllib.parse import quote # 编码
import jieba # 词云相关
from wordcloud import WordCloud # 词云
import matplotlib.pyplot as plt # matplotlib.pyplotPS:安装完wordcloud模块后,中文生成词云会乱码,需要做如下修改:
①方法一:使用的时候指定使用的文字字体
wordcloud.WordCloud(font_path='simhei.ttf').generate(xxx) # 使用微软雅黑字体②方法二:直接修改模块引用,彻底解决这个问题
将自己的字体库放在安装目录中,并修改wordcloud.py文件中的引用
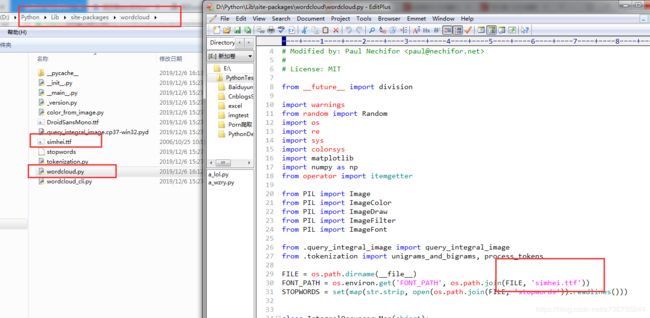
词频统计所需要的词语文件,可从搜狗词库中下载(.scel文件),然后格式转为txt文件
搜狗词库地址:https://pinyin.sogou.com/dict/
格式转换地址:http://tools.bugscaner.com/sceltotxt/
3、主要思路
①用户输入想搜索的电影名称
②对电影名称进行编码,并发送请求
③获取电影列表并打印,用户选择想要爬取的电影
④获取电影编号后,发送请求爬取页面
⑤对HTML页面进行处理,获取评论信息
⑥写入csv文件或excel文件
⑦生成词云图
⑧生成词频统计文件
4、代码相关
①获取影片列表接口:
在搜索栏输入名称时,发现会调用这个接口https://movie.douban.com/j/subject_suggest?q=编码后的电影名称
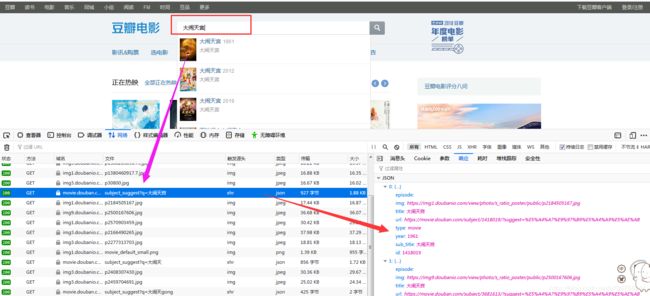
②获取评论接口:
点击分页发现会调用这个接口:
https://movie.douban.com/subject/'+ 影片id + '/reviews?start=(page+1)*10
或者这个接口:
https://movie.douban.com/subject/' + 影片id + '/comments?start={' + page+1 + '}&limit=20&sort=new_score&status=P

数据准备:
# 浏览器代理头
user_agent = [
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.168 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.9.168 Version/11.50',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; GTB7.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; ) AppleWebKit/534.12 (KHTML, like Gecko) Maxthon/3.0 Safari/534.12',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.3 (KHTML, like Gecko) Chrome/6.0.472.33 Safari/534.3 SE 2.X MetaSr 1.0',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.41 Safari/535.1 QQBrowser/6.9.11079.201',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E) QQBrowser/6.9.11079.201',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0'
]
cok='bid=IvV3BPXNahg; _pk_id.100001.4cf6=ce978a8d138f1315.1575613176.3.1575785754.1575621036.; __utma=30149280.1347665870.1575613177.1575621033.1575785749.3; __utmz=30149280.1575613177.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utma=223695111.1029442254.1575613177.1575621033.1575785755.3; __utmz=223695111.1575785755.3.2.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; ll="118159"; __utmb=30149280.2.10.1575785749; __utmc=30149280; __utmt=1; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1575785754%2C%22https%3A%2F%2Fwww.douban.com%2F%22%5D; _pk_ses.100001.4cf6=*; __utmb=223695111.0.10.1575785755; __utmc=223695111; ap_v=0,6.0; __yadk_uid=zHCYWt7NZH2tQi08F9GyUw1256zStXSG; _vwo_uuid_v2=DC415C5465AFD4240435B780F3852697D|7092204f7d5cfc68e89ef8843ed4212b'
# 随机选取用户代理
def get_ua():
au = random.choice(user_agent)
return au
①主程序入口:
# 主程序入口
def main():
movie_name = input("请输入想搜索的电影名称:")
searchkey = quote(movie_name, 'utf-8')
MovieUrl='https://movie.douban.com/j/subject_suggest?q=%s'%searchkey
MovieList = get_movie(MovieUrl) # 获取相关电影列表
if len(MovieList)>0:
# 输出电影信息,供用户自己选择
for i,v in enumerate(MovieList,1):
print('影片编号:%d 影片名称:%s 影片上映时间:%s'%(i, v['title'], v['year']))
input_mid = input('请输入想查看的影片编号:') # 选择电影
mid = MovieList[int(input_mid)-1]['id'] # 获取电影编号
pq_num = int(input('爬取多少页数据?')) # 输入爬取页数
choose_movie(movie_name,mid,pq_num) # 爬取
else:
print('未获取到搜索结果')
return② 获取电影列表信息
# 抓取电影列表信息
def get_movie(url):
headers = {
'User-Agent': get_ua(),
'Host': 'movie.douban.com',
'Connection': 'keep-alive',
'Cookie':cok
}
res = requests.get(url, headers=headers)
movie_list = res.json()
if len(movie_list)>0:
return movie_list
else:
return []
③获取电影信息并解析
# 选择抓取的影片
def choose_movie(movie_name,movie_id,pq_num):
url = 'https://movie.douban.com/subject/' + movie_id + '/comments?start={}&limit=20&sort=new_score&status=P'
comments = []
print("开始爬取")
start_time = time.time()
for i in range(pq_num):
print("*******开始爬取第%d页数据*******" % (i + 1))
soup = get_soup(url.format(i * 20)) # 获取html
comments.extend(getText(soup)) # 添加列表中
print("*******爬取完成,随机等待0-5秒*******")
time.sleep(random.random() * 5)
end_time = time.time()
print("共用时%d秒" % (end_time - start_time))
# 写入excel
# writetoexcel(comments,movie_name)
# 写入csv
writetocsv(movie_name, comments)
# 抓取解析网页
def get_soup(url):
# 伪装浏览器发送请求
headers = {
'User-Agent': get_ua(),
'Host': 'movie.douban.com',
'Connection': 'keep-alive',
'Cookie':cok
}
res = requests.get(url, headers=headers)
# if res.status_code==200:
# print("请求成功")
time.sleep(random.random() * 5) # 设置时间间隔,防止太快被封
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
print("解析完成")
return soup
# 获取一页用户的评论
def getText(soup):
comment_list = []
for p in soup.select('.comment-item'):
comment = {}
# 根据元素选择器,获得所需的信息:用户名/评价/时间等
username = p.select('.comment-info')[0]('a')[0].text
watch = p.select('.comment-info')[0]('span')[0].text
intro = p.select('.comment-info')[0]('span')[1]['title']
cTime = p.select('.comment-time ')[0]['title']
pNum = p.select('.votes')[0].text
short = p.select('.short')[0].text.replace('\n', ' ')
comment['用户名'] = username
comment['观看情况'] = watch
comment['评分推荐'] = intro
comment['评论时间'] = cTime
comment['短评内容'] = short
comment['赞同该评论次数'] = pNum
comment_list.append(comment)
# comment_list.append([username,watch,intro,cTime,short,pNum])
return comment_list
④写入excel文件或csv文件
# 写入excel
def writetoexcel(list,name):
print('创建excel')
book = xlsxwriter.Workbook(u'海王评论.xlsx')
sheet = book.add_worksheet()
sheet.write(0, 0, '用户名')
sheet.write(0, 1, '观看情况')
sheet.write(0, 2, '评分推荐')
sheet.write(0, 3, '评论时间')
sheet.write(0, 4, '短评内容')
sheet.write(0, 5, '赞同该评论次数')
row = 1
col = 0
for index, item in enumerate(list):
# print('写入第%s行数据'%row)
sheet.write(row, col, item[0]) # 用户名
sheet.write(row, col + 1, item[1]) # 观看情况
sheet.write(row, col + 2, item[2]) # 评分推荐
sheet.write(row, col + 3, item[3]) # 评论时间
sheet.write(row, col + 4, item[4]) # 短评内容
sheet.write(row, col + 5, item[5]) # 赞同该评论次数
row += 1
print('写入完成')
book.close() # 关闭
# 是否生成词云
time.sleep(3)
isCleanData = input('是否生成词云(Y/N)?')
if isCleanData == 'Y':
get_text(name)
# 写入csv
def writetocsv(name,list):
commentFile = pd.DataFrame(list)
commentFile.to_csv(r'%s.csv'%name, encoding='utf_8_sig')
# 是否生成词云
time.sleep(3)
isCleanData=input('是否生成词云(Y/N)?')
if isCleanData=='Y':
get_text(name)
⑤生成词云和统计数据
# 生成词云和统计数据
def get_text(name):
# 读取爬取的评论
fp = open(r'%s.csv'%name, 'r', encoding='utf-8').read()
jieba.load_userdict('scel_to_text.txt')
# jieba.add_word() # 可以添加自定义词典
# 将文件中所有文字分词
words_list = jieba.lcut(fp)
# 用空格分隔词语
tokenstr = ' '.join(words_list)
mywc1 = WordCloud().generate(tokenstr)
# 显示词云
plt.imshow(mywc1)
plt.axis('off')
plt.show()
mywc1.to_file('%s.png'%name) # 生成词云图片
# 是否生成词频统计
time.sleep(3)
issum = input('是否生成词频统计(Y/N)?')
if issum == 'Y':
word_dict = {}
# set:无序非重对象
words_set = set(words_list)
for w in words_set:
# 高频词大于一个字的,当然这里可以自定义取值规则
if len(w) > 1:
word_dict[w] = words_list.count(w)
# 排序 word_dict.items() : [('尤其', 1), ('雷神', 2), ('再现', 1), ('之子', 1), ('热泪盈眶', 1), ('不过', 3), ('记住', 1)]
'''
sorted:
iterable -- 可迭代对象。
cmp -- 比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。
key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
'''
words_sort = sorted(word_dict.items(), key=lambda x: x[1], reverse=True)
# 输出词频TOP20
words_sort1 = words_sort[:20]
pd.DataFrame(data=words_sort1).to_csv('统计数据.csv', encoding='utf-8')
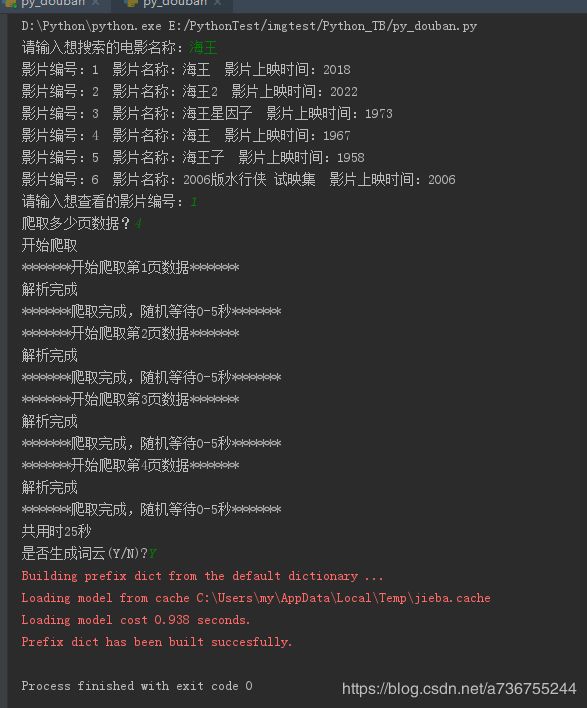
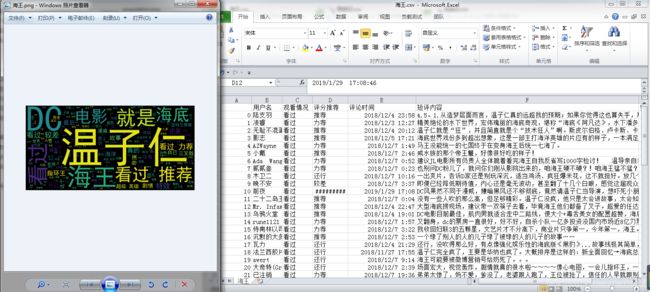
5、运行结果
相关问题欢迎留言讨论!