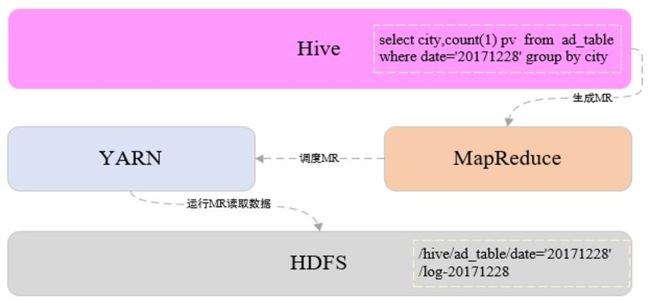
Hive由Facebook开源,是一个构建在Hadoop之上的数据仓库将结构化的数据映射成表支持类SQL查询,Hive中称为HQL无法实时更新,只支持向现有表中追加数据。
Hive常用文件格式类型
TEXTFILE
- 默认文件格式,建表时用户需要显示指定分隔符
- 存储方式:行存储
SequenceFile
- 二进制键值对序列化文件格式
- 存储方式:行存储
列式存储格式
- RCFILE/ORC
- 存储方式:列存储
常用数据类型
1.整数类型
- SMALLINT、INT、BIGINT
- 空间占用分别是1字节、2字节、4字节、8字节
2.浮点类型
- DOUBLE
- 空间占用分别是32位和64位浮点数
3. 布尔类型BOOLEAN
- 用于存储true和false
4.字符串文本类型STRING
- 存储变长字符串,对类型长度没有限制
5.时间戳类型TIMESTAMP
- 存储精度为纳秒的时间戳
复杂数据类型
1.ARRAY
- 存储相同类型的数据,可以通过下标获取数据
- 定义:ARRAY
- 查询:array[index]
2.MAP
- 存储键值对数据,键或者值的类型必须相同,通过键获取值。
- 定义:MAP
- 查询:map[‘key’]
3.STRUCT
- 可以存储多种不同的数据类型,一旦声明好结构,各字段的位置不能够改变。
- 定义:STRUCT
- 查询:struct.fieldname
一、Hive的安装
1.下载Hive安装包并解压
[hadoop@hadoop01 apps]$ tar -zxvf apache-hive-1.2.2-bin.tar.gz
2.使用Root用户创建软链接
[root@hadoop01 apps]# ln -s /home/hadoop/apps/apache-hive-1.2.2-bin /usr/local/hive
3.为Hive指定用户组
[root@hadoop01 apps]# chown -R hadoop:hadoop /usr/local/hive
4. 添加Hive到系统环境变量并生效
[root@hadoop01 apps]# vim /etc/profile
添加环境变量内容为:
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:${JAVA_HOME}/bin:${ZOOKEEPER_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
:${HIVE_HOME}/bin
生效环境变量
[root@hadoop01 apps]# source /etc/profile
5.配置Hive的默认metastore
修改Hive配置目录下的hive-site.xml配置文件,编辑内容如下:
javax.jdo.option.ConnectionURL
jdbc:mysql://192.168.43.50:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
hadoop
username to use against metastore database
javax.jdo.option.ConnectionPassword
xxxx
password to use against metastore database
说明:数据库连接地址为Mysql地址,且所配置用户具有外网访问数据库权限,ConnectionPassword配置成个人Mysql数据库用户密码
二、Hive的使用
1.运行hive
[hadoop@hadoop01 ~]$ hive
Logging initialized using configuration in jar:file:/home/hadoop/apps/apache-hive-1.2.2-bin/lib/hive-common-1.2.2.jar!/hive-log4j.properties
2.查看数据库
hive> show databases;
OK
default
Time taken: 0.99 seconds, Fetched: 1 row(s)
3.创建用户表: user_info
字段信息
| 字段名称 | 字段类型 |
|---|---|
| 用户id | string |
| 地域id | string |
| 年龄 | int |
| 职业 | string |
create table user_info(
user_id string,
area_id string,
age int,
occupation string
)
row format delimited fields terminated by '\t'
lines terminated by '\n'
stored as textfile;
4.查看表
查看default库中的表,发现新建的user_info表在default库中
hive> show tables;
OK
user_info
Time taken: 0.04 seconds, Fetched: 1 row(s)
查看对应文件目录信息
[hadoop@hadoop01 root]$ hadoop fs -ls /user/hive/warehouse
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2018-01-14 19:48 /user/hive/warehouse/user_info
5.hive删除表
删除user_info表,user_info表在hdfs的目录也会被同时删除
hive> drop table user_info;
OK
Time taken: 0.935 seconds
hive> show tables;
OK
Time taken: 0.041 seconds
查看文件目录位置
[hadoop@hadoop01 root]$ hadoop fs -ls /user/hive/warehouse
[hadoop@hadoop01 root]$
6.创建数据库,用于存储维度
hive> create database rel;
OK
Time taken: 0.098 seconds
hive> show databases;
OK
default
rel
Time taken: 0.025 seconds, Fetched: 2 row(s)
查看对应文件目录信息:
[hadoop@hadoop01 root]$ hadoop fs -ls /user/hive/warehouse
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2018-01-14 19:55 /user/hive/warehouse/rel.db
7.创建内部管理表
在数据库rel中创建学生信息表,字段信息:学号、姓名、年龄、地域。切换使用rel数据库:
use rel;
create table student_info(
student_id string comment '学号',
name string comment '姓名',
age int comment '年龄',
origin string comment '地域'
)
comment '学生信息表'
row format delimited
fields terminated by '\t'
lines terminated by '\n'
stored as textfile;
查看对应目录信息
[hadoop@hadoop01 root]$ hadoop fs -ls /user/hive/warehouse/rel.db
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2018-01-14 19:59 /user/hive/warehouse/rel.db/student_info
8.使用load从本地加载数据到表
使用load从本地加载数据到表student_info
hive> load data local inpath '/home/hadoop/apps/hive_test_data/student_info_data.txt' into table student_info;
Loading data to table rel.student_info
Table rel.student_info stats: [numFiles=1, totalSize=341]
OK
Time taken: 1.144 seconds
查看student_info 表信息和对应文件路径
hive> select * from student_info;
OK
1 xiaoming 20 11
2 xiaobai 21 31
3 zhangfei 22 44
4 likui 19 44
5 zhaoyun 21 13
6 zhangsan 20 11
7 lisi 19 11
8 wangwu 23 31
9 zhaofei 19 21
10 zhangyan 20 21
11 lihe 20 22
12 caoyang 17 32
13 lihao 19 32
14 zhaoming 21 50
15 zhouhong 18 51
16 yangshuo 23 33
17 xiaofei 24 13
18 liman 23 13
19 qianbao 20 13
20 sunce 21 41
Time taken: 0.767 seconds, Fetched: 20 row(s)
查看对应文件夹路径信息
[hadoop@hadoop01 hive_test_data]$ hadoop fs -ls /user/hive/warehouse/rel.db/student_info
Found 1 items
-rwxr-xr-x 3 hadoop supergroup 341 2018-01-14 20:09 /user/hive/warehouse/rel.db/student_info/student_info_data.txt
9.使用load从HDFS上加载数据到表student_info
先删除原有数据文件
[hadoop@hadoop01 hive_test_data]$ hadoop fs -rm -f /user/hive/warehouse/rel.db/student_info/student_info_data.txt
18/01/14 20:15:31 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /user/hive/warehouse/rel.db/student_info/student_info_data.txt
将本地文件上传到HDFS根目录下
[hadoop@hadoop01 hive_test_data]$ hadoop fs -put /home/hadoop/apps/hive_test_data/student_info_data.txt /
[hadoop@hadoop01 hive_test_data]$ hadoop fs -ls /
Found 6 items
drwxr-xr-x - hadoop supergroup 0 2018-01-14 16:23 /addata
drwxr-xr-x - hadoop supergroup 0 2017-12-23 20:20 /data
-rw-r--r-- 3 hadoop supergroup 341 2018-01-14 20:16 /student_info_data.txt
drwxrwx--- - hadoop supergroup 0 2018-01-14 17:26 /tmp
drwxr-xr-x - hadoop supergroup 0 2018-01-14 19:48 /user
drwxr-xr-x - hadoop supergroup 0 2018-01-13 16:26 /wordcount
使用load将HDFS文件加载到student_info 表中
hive> load data inpath '/student_info_data.txt' into table student_info;
Loading data to table rel.student_info
Table rel.student_info stats: [numFiles=1, totalSize=341]
OK
Time taken: 0.602 seconds
hive> select * from student_info;
OK
1 xiaoming 20 11
2 xiaobai 21 31
3 zhangfei 22 44
4 likui 19 44
5 zhaoyun 21 13
6 zhangsan 20 11
7 lisi 19 11
8 wangwu 23 31
9 zhaofei 19 21
10 zhangyan 20 21
11 lihe 20 22
12 caoyang 17 32
13 lihao 19 32
14 zhaoming 21 50
15 zhouhong 18 51
16 yangshuo 23 33
17 xiaofei 24 13
18 liman 23 13
19 qianbao 20 13
20 sunce 21 41
Time taken: 0.143 seconds, Fetched: 20 row(s)
采用覆盖重写方式加载文件到student_info 表中
- 原hdfs根目录下的student_info_data.txt已经被剪切到student_info表的hdfs路径下/user/hive/warehouse/rel.db/student_info
hive> load data inpath '/student_info_data.txt' overwrite into table student_info;
Loading data to table rel.student_info
Table rel.student_info stats: [numFiles=1, numRows=0, totalSize=341, rawDataSize=0]
OK
Time taken: 0.41 seconds
10.Hive的数据类型
| 字段名 | 类型 | 注释 |
|---|---|---|
| user_id | string | 用户ID |
| salary | int | 工资 |
| worked_citys | array |
工作过的城市 |
| social_security | map |
社保缴费情况(养老,医保) |
| wealfare | struct |
福利(吃饭补助(float),是否转正(boolean),商业保险(float) |
创建员工表
hive> create table rel.employee(
> user_id string,
> salary int,
> worked_citys array,
> social_security map,
> welfare struct
> )
> row format delimited fields terminated by '\t'
> collection items terminated by ','
> map keys terminated by ':'
> lines terminated by '\n'
> stored as textfile;
OK
Time taken: 0.212 seconds
hive> show tables;
OK
employee
student_info
Time taken: 0.057 seconds, Fetched: 2 row(s)
从本地加载数据到表employee
hive> load data local inpath '/home/hadoop/apps/hive_test_data/employee_data.txt' into table employee;
Loading data to table rel.employee
Table rel.employee stats: [numFiles=1, totalSize=206]
OK
Time taken: 0.388 seconds
hive> select * from employee;
OK
zhangsan 10800 ["beijing","shanghai"] {"养老":1000.0,"医疗":600.0} {"meal_allowance":2000.0,"if_regular":true,"commercial_insurance":500.0}
lisi 20000 ["beijing","nanjing"] {"养老":2000.0,"医疗":1200.0} {"meal_allowance":2000.0,"if_regular":false,"commercial_insurance":500.0}
wangwu 17000 ["shanghai","nanjing"] {"养老":1800.0,"医疗":1100.0} {"meal_allowance":2000.0,"if_regular":true,"commercial_insurance":500.0}
Time taken: 0.127 seconds, Fetched: 3 row(s)
查询已转正的员工编号,工资,工作过的第一个城市,社保养老缴费情况,福利餐补金额
select user_id,
salary,
worked_citys[0],
social_security['养老'],
welfare.meal_allowance
from rel.employee
where welfare.if_regular=true;
11.创建外部表 【常用】
| 字段名 | 字段类型 | 字段注释 |
|---|---|---|
| student_id | string | 学生ID |
| name | string | 学生姓名 |
| institute_id | string | 学院ID |
| major_id | string | 专业ID |
| school_year | string | 入学年份 |
可以提前创建好hdfs路径
hadoop mkdir -p /user/hive/warehouse/data/student_school_info
如果没有提前创建好,在创建外部表的时候会根据指定路径自动创建
| 字段名 | 字段类型 | 字段注释 |
|---|---|---|
| student_id | string | 学生ID |
| name | string | 学生姓名 |
| institute_id | string | 学院ID |
| major_id | string | 专业ID |
| school_year | string | 入学年份 |
create external table rel.student_school_info(
student_id string,
name string,
institute_id string,
major_id string,
school_year string
)
row format delimited
fields terminated by '\t'
lines terminated by '\n'
stored as textfile
location '/user/hive/warehouse/data/student_school_info';
查看对应文件目录
[hadoop@hadoop01 root]$ hadoop fs -ls /user/hive/warehouse/data/
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2018-01-15 14:08 /user/hive/warehouse/data/student_school_info
上传本地数据文件到hdfs
[hadoop@hadoop01 root]$ hadoop fs -put /home/hadoop/apps/hive_test_data/student_school_info_external_data.txt /user/hive/warehouse/data/student_school_info/
12.创建内部分区表
| 字段名称 | 类型 | 注释 |
|---|---|---|
| studnet_id | string | 学号 |
| name | string | 姓名 |
| institute_id | string | 学院ID |
| major_id | string | 专业ID |
create table student_school_info_partition(
student_id string,
name string,
institute_id string,
major_id string
)
partitioned by(school_year string)
row format delimited
fields terminated by '\t'
lines terminated by '\n'
stored as textfile;
使用insert into从student_school_info表将2017年入学的学籍信息导入到student_school_info_partition分区表中
insert into table student_school_info_partition partition(school_year='2017')
select t1.student_id,t1.name,t1.institute_id,t1.major_id
from student_school_info t1
where t1.school_year=2017;
13.查看分区
hive> show partitions student_school_info_partition;
OK
school_year=2017
Time taken: 0.191 seconds, Fetched: 1 row(s)
查看hdfs路径
[hadoop@hadoop01 root]$ hadoop fs -ls /user/hive/warehouse/rel.db/student_school_info_partition/
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2018-01-16 13:20 /user/hive/warehouse/rel.db/student_school_info_partition/school_year=2017
查询student_school_info_partition
hive> select * from student_school_info_partition where school_year='2017';
OK
1 xiaoming information software 2017
2 xiaobai information computer 2017
3 zhangfei information computer 2017
4 likui information bigdata 2017
5 zhaoyun information bigdata 2017
6 zhangsan information software 2017
7 lisi information bigdata 2017
8 wangwu information computer 2017
Time taken: 0.226 seconds, Fetched: 8 row(s)
14.删除分区
hive> alter table student_school_info_partition drop partition (school_year='2017');
Dropped the partition school_year=2017
OK
Time taken: 0.71 seconds
15.使用动态分区添加数据
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table student_school_info_partition partition(school_year)
select t1.student_id,t1.name,t1.institute_id,t1.major_id,t1.school_year
from student_school_info t1
查看分区
hive> show partitions student_school_info_partition;
OK
school_year=2017
Time taken: 0.12 seconds, Fetched: 1 row(s)
查看hdfs路径
[hadoop@hadoop01 root]$ hadoop fs -ls /user/hive/warehouse/rel.db/student_school_info_partition/
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2018-01-16 13:27 /user/hive/warehouse/rel.db/student_school_info_partition/school_year=2017
15.创建外部分区表【常用】
create external table rel.student_school_info_external_partition(
student_id string,
name string,
institute_id string,
major_id string
)
partitioned by(school_year string)
row format delimited
fields terminated by '\t'
lines terminated by '\n'
stored as textfile
location '/user/hive/warehouse/data/student_school_info_external_partition';
在分区表的hdfs路径中添加school_year=2017目录
hadoop fs -mkdir /user/hive/warehouse/data/student_school_info_external_partition/school_year=2017
将student_school_external_partition_data.txt文件上传到school_year=2017文件夹下
hadoop fs -put student_school_external_partition_data.txt /user/hive/warehouse/data/student_school_info_external_partition/school_year=2017
虽然数据已经添加到了分区对应的hdfs路径,但是表还没有添加分区,所以查询的时候没有数据
手动添加分区
hive> alter table student_school_info_external_partition add partition(school_year='2017');
OK
Time taken: 0.111 seconds
hive> select * from student_school_info_external_partition;
OK
1 xiaoming information software 2017
2 xiaobai information computer 2017
3 zhangfei information computer 2017
4 likui information bigdata 2017
5 zhaoyun information bigdata 2017
6 zhangsan information software 2017
7 lisi information bigdata 2017
8 wangwu information computer 2017
Time taken: 0.127 seconds, Fetched: 8 row(s)
删除分区
hive> alter table student_school_info_external_partition drop partition(school_year='2017');
Dropped the partition school_year=2017
OK
Time taken: 0.19 seconds
查看分区,分区已经被删除
hive> show partitions student_school_info_external_partition;
OK
Time taken: 0.168 seconds
查看hdfs分区数据,分区数据还在
[hadoop@hadoop01 hive_test_data]$ hadoop fs -ls /user/hive/warehouse/data/student_school_info_external_partition/school_year=2017
Found 1 items
-rw-r--r-- 3 hadoop supergroup 250 2018-01-16 13:33 /user/hive/warehouse/data/student_school_info_external_partition/school_year=2017/student_school_external_partition_data.txt