Flink之数据流编程模型(上)
数据流编程模型
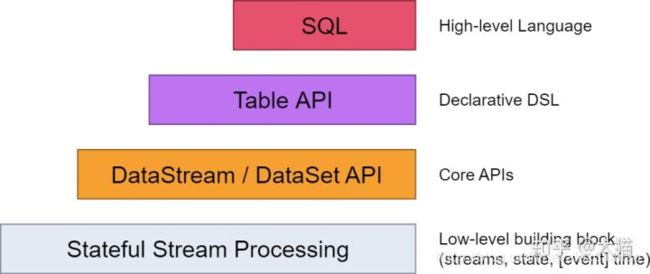
Statefule Stream Processing: 是最低级别(底层)的抽象,只提供有状态的流。它通过ProcessFunction嵌入到DataStream API之中。它使得用户可以自由处理来源于一个或者多个流的事件。
DataStream/DataSet API: 在我们的实际工作中,大多数的应用程序是不需要上文所描述的低级别(底层)抽象,而是相对于诸如DataStream API(有界/无界流)和DataSet API(有界数据集)的Core API进行编程。
Table API:是围绕着table的申明性DSL,可以被动态的改变(当其表示流时)。Table API遵循(扩展)关系模型:表有一个模式链接(类似与在关系数据库中的表),API也提供了一些类似的操作:select, project, join, group-by, aggregate等。
表和DataStream / DataSet之间可以无缝转换,允许程序混合使用Table API和DataStream 和DataSet API。
流式编程
用户实现的Flink程序是由Stream和Transformation这两个基本构建块组成:Stream是一个中间结果数据,而Transformation是一个操作,它对一个或多个输入Stream进行计算处理,输出一个或多个结果Stream。
当一个Flink程序被执行的时候,它会被映射为Streaming Dataflow。一个Streaming Dataflow是由一组Stream和Transformation Operator组成,它类似于一个DAG图,在启动的时候从一个或多个Source Operator开始,结束于一个或多个Sink Operator。 下面是一个由Flink程序映射为Streaming Dataflow的示意图,如下所示:
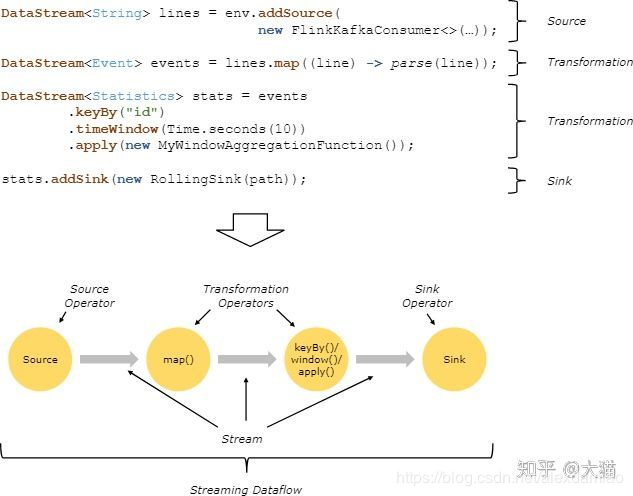
上图中,FlinkKafkaConsumer是一个Source Operator,map、keyBy、timeWindow、apply是Transformation Operator,RollingSink是一个Sink Operator。
并行数据流
在Flink中,程序天生是并行和分布式的:一个Stream可以被分成多个Stream分区(Stream Partitions),一个Operator可以被分成多个Operator Subtask,每一个Operator Subtask是在不同的线程中独立执行的。一个Operator的并行度,等于Operator Subtask的个数,一个Stream的并行度总是等于生成它的Operator的并行度。
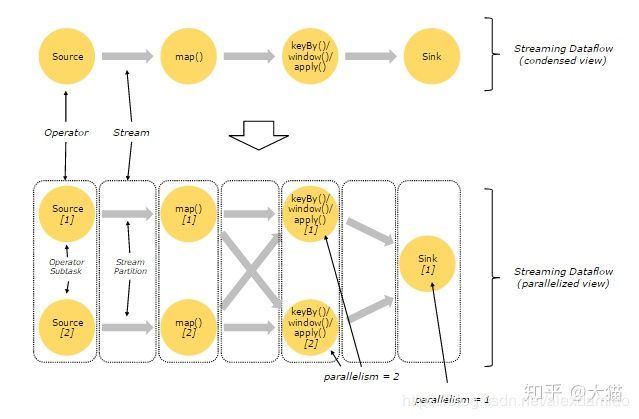
上图Streaming Dataflow的并行视图中,展现了在两个Operator之间的Stream的两种模式:
- One-to-one模式
比如从Source[1]到map()[1],它保持了Source的分区特性(Partitioning)和分区内元素处理的有序性,也就是说map()[1]的Subtask看到数据流中记录的顺序,与Source[1]中看到的记录顺序是一致的。 - Redistribution模式
这种模式改变了输入数据流的分区,比如从map()[1]、map()[2]到keyBy()/window()/apply()[1]、keyBy()/window()/apply()[2],上游的Subtask向下游的多个不同的Subtask发送数据,改变了数据流的分区,这与实际应用所选择的Operator有关系。
另外,Source Operator对应2个Subtask,所以并行度为2,而Sink
Operator的Subtask只有1个,故而并行度为1。
执行链
在Flink分布式执行环境中,会将多个Operator Subtask串起来组成一个Operator Chain,实际上就是一个执行链,每个执行链会在TaskManager上一个独立的线程中执行,如下图所示:
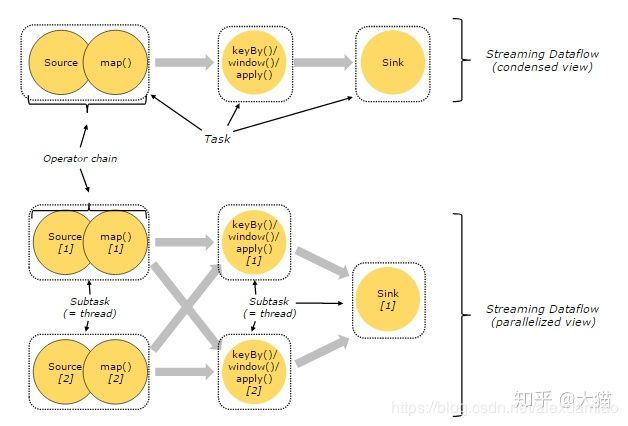
上图中上半部分表示的是一个Operator Chain,多个Operator通过Stream连接,而每个Operator在运行时对应一个Task;图中下半部分是上半部分的一个并行版本,也就是对每一个Task都并行化为多个Subtask。
窗口
Flink将Window分为两类,一类叫做Keyed Window,另一类叫做Non-Keyed Window。
标题Keyed Window
stream
.keyBy(...) <- keyed versus non-keyed windows
.window(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
Non-Keyed Windows
stream
.windowAll(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
Keyed Window编程结构,可以直接对输入的stream按照Key进行操作,输入的stream中识别Key,即输入stream中的每个数据元素哪一部分是作为Key来关联这个数据元素的,这样就可以对stream中的数据元素基于Key进行相关计算操作,如keyBy,可以根据Key进行分组(相同的Key必然可以分到同一组中去)。如果输入的stream中没有Key,比如就是一条日志记录信息,那么无法对其进行keyBy操作。
Non-Keyed Window编程结构来说,无论输入的stream具有何种结构(比如是否具有Key),它都认为是无结构的,不能对其进行keyBy操作,而且如果使用Non-Keyed Window函数操作,就会对该stream进行分组(具体如何分组依赖于我们选择的WindowAssigner,它负责将stream中的每个数据元素指派到一个或多个Window中),指派到一个或多个Window中,然后后续应用到该stream上的计算都是对Window中的这些数据元素进行操作。
从计算上看,Keyed Window编程结构会将输入的stream转换成Keyed stream,逻辑上会对应多个Keyed stream,每个Keyed stream会独立进行计算,这就使得多个Task可以对Windowing操作进行并行处理,具有相同Key的数据元素会被发到同一个Task中进行处理。而对于Non-Keyed Window编程结构,Non-Keyed stream逻辑上将不能split成多个stream,所有的Windowing操作逻辑只能在一个Task中进行处理,也就是说计算并行度为1。
Flink支持基于时间窗口操作,也支持基于数据的窗口操作,如下图所示:
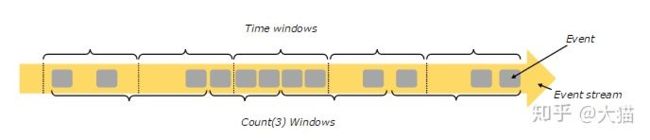
基于时间的窗口操作,在每个相同的时间间隔对Stream中的记录进行处理,通常各个时间间隔内的窗口操作处理的记录数不固定;
基于数据驱动的窗口操作,可以在Stream中选择固定数量的记录作为一个窗口,对该窗口中的记录进行处理。
基于数据的窗口
- CountWindows
基于时间的窗口:
- Tumbling Windows,记录没有重叠
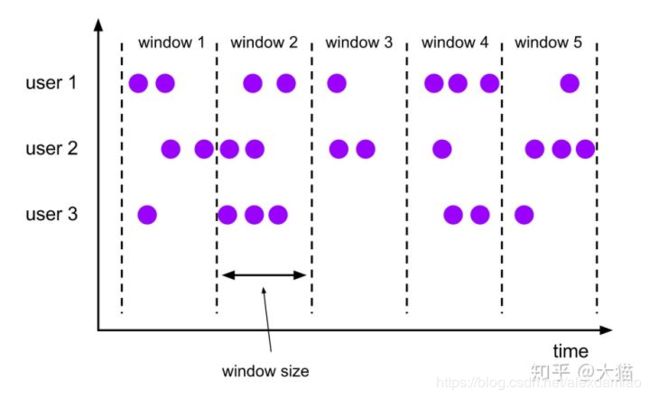
固定相同间隔分配窗口,每个窗口之间没有重叠看图一眼明白。
下面的例子定义了每隔3毫秒一个窗口的流:
WindowedStream Rates = rates
.keyBy(MovieRate::getUserId)
.window(TumblingEventTimeWindows.of(Time.milliseconds(3)));
- Slide Windows,记录有重叠
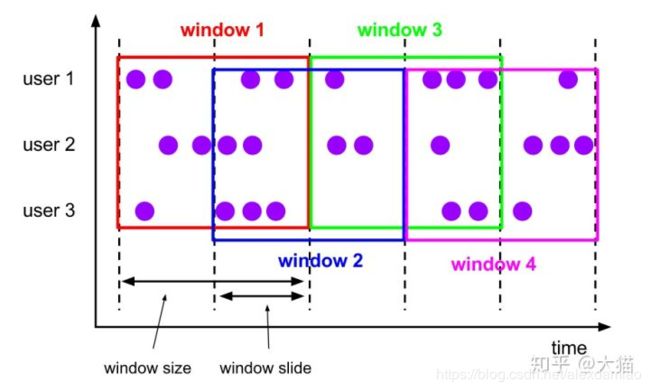
跟上面一样,固定相同间隔分配窗口,只不过每个窗口之间有重叠。窗口重叠的部分如果比窗口小,窗口将会有多个重叠,即一个元素可能被分配到多个窗口里去。
下面的例子给出窗口大小为10毫秒,重叠为5毫秒的流
WindowedStream Rates = rates
.keyBy(MovieRate::getUserId)
.window(SlidingEventTimeWindows.of(Time.milliseconds(10), Time.milliseconds(5)));
- Session Windows
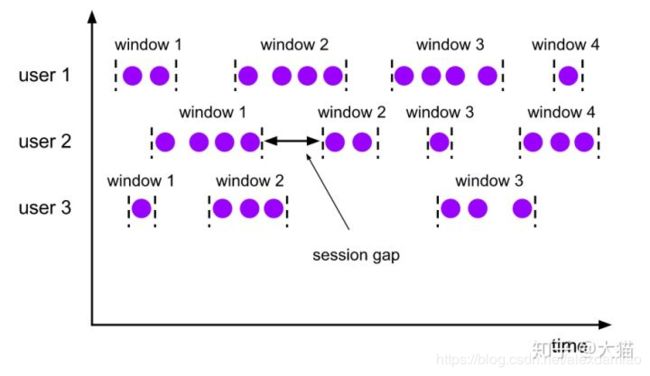
这种窗口主要是根据活动的事件进行窗口化,他们通常不重叠,也没有一个固定的开始和结束时间。一个session window关闭通常是由于一段时间没有收到元素。在这种用户交互事件流中,我们首先想到的是将事件聚合到会话窗口中(一段用户持续活跃的周期),由非活跃的间隙分隔开。
// 静态间隔时间
WindowedStream Rates = rates
.keyBy(MovieRate::getUserId)
.window(EventTimeSessionWindows.withGap(Time.milliseconds(10)));
// 动态时间
WindowedStream Rates = rates
.keyBy(MovieRate::getUserId)
.window(EventTimeSessionWindows.withDynamicGap(()))
-
Global Windows

将所有数据放在一个窗口内:WindowedStream