MySQL45讲 索引(2)
MySQL索引
MySQL为什么有时候会选错索引
我们知道,MySQL是有很多索引的,但是我们在写SQL语句的时候,并没有主动指定使用哪个索引,也就是说,使用哪个索引是由MySQL来确定的。因此有时就会发生一种情况,由于MySQL选错了索引,导致本来应该执行的很快的语句执行的很慢。
一个例子
对于如下建表语句
create table t(
id int(11) not null,
a int(11) default null,
b int(11) default null,
primary key(id),
key a (a),
key b (b)
)engine=InnoDB;
表中有10万行数据即(1,1,1),(2,2,2)一直到(100000,100000,100000).
接下来我分析下面这条SQL语句
select * from t where a between 10000 and 20000;
这个情况由于a上有索引,所以优化器选择使用了索引a

看起来很正常,但是在如下过程中,MySQL不会使用索引a
| session A | session B |
|---|---|
| start transaction with consistend snapshop; | |
| delete from t; call idata(); |
|
| commit; | |
| explain select * from t where a between 10000 and 20000 |
session A 的操作为开启一个事务,随后session B把数据都删除后,调用了idata这个存储过程,插入了10万行数据。这时候session B的查询语句就不会在选择索引a了,我们通过慢查询日志来查看一下具体的情况
我们通过一下两条语句来
set sql_long_query=0;
select * from t where a between 10000 and 20000;
select * from t force index(a) where a between 10000 and 20000;
- 第一句,讲慢查询日志的阈值设置为0,标识这个线程接下来的语句都会被记录入慢查询日志中。
- 第二句,Q1是sessionB原来的查询;
- 第三句,Q2是加了force index(a)来和sessionB原来的查询语句做对比
下图为三条SQL语句执行完成后的慢查询日志
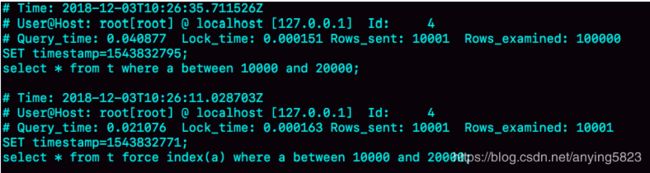
我们从中看到Q1扫描了10万行,显然走了全表扫描,执行时间40ms,Q2扫描了10001行,执行了21毫秒。也就是说,我们在没有使用force index的时候,MySQL用错了索引,导致了更长的执行时间。
优化器的逻辑
在第一篇文章中,我们就提到过,选择索引是优化器的工作,优化器选择索引的目的,是找到一个最优的执行方案,使用最小的代价去执行语句。在数据库里面,扫描行数是影响执行代价的因素之一,扫描的行数越少,意味着访问磁盘数据的次数越少,消耗的CPU资源越少。
当然扫描行数不是唯一的判断标准,优化器还会结合是否使用临时表,是否排序等因素进行综合判断。但是我们这个简单的查询语句并没有涉及到临时表和排序,所以MySQL选错索引肯定实在判断扫描行数的时候出问题了。
那么扫描行数是怎么判断的呢
MySQL在真正开始执行语句之前,并不能精确的知道满足这个条件的记录有多少条,而只能根据统计信息来估算记录数。这个统计信息就是索引的区分度。显然,一个索引上不同的值越多,这个索引的区分度就越好,而一个索引上不同的值的个数,我们称之为“基数”,也就是说,这个基数越大,索引的区分度越好。
我们用show index可以看到一个索引的基数,如下图所示,就是表t的show index的结果。虽然这个表的第一行的三个字段值都是一样的,但是在统计信息中,这三个索引的基数值并不同,而且都不准确。

MySQL如何得到索引的基数?
MySQL使用采样统计的方法,为什么要采样统计呢,因为把整张表取出来一行行的统计,虽然可以得到精确的结果,但是代价太高了,所以只能选择“采样统计”。采样统计的时候,InnoDB默认会选择N个数据页,统计这些页面上的不同值,得到一个平均值,然后乘这个索引的页面数,就得到了这个索引的基数。数据表是会持续更新的,索引同居信息也不会固定不变,所以,当变更的数据行数超过1/M的时候,会自动触发重新做一次索引统计。
在MySQL中,有两种存储索引统计的方式,可以通过设置参数Innodb_stats_persistent的值来选择:
- 设置为on的时候,表示统计信息会持久化存储,默认的N是20,M是10;
- 设置为off的时候,表示统计信息只会存储在内存中,这是,默认的N是8,M是16
所以这个基数总是不准的。但是我们可以看到虽然索引统计值(cardinality列)虽然不够精准,但大体上还是差不多的,选错索引一定还有别的原因。
其实索引统计只是一个输入,对于一个具体的语句来说,优化器还要判断,执行这个语句本身要扫描多少行。
这里我们来看优化器预估的,这两个语句的扫描行数是多少。
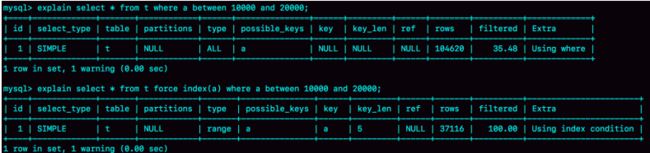
rows这个字段表示预计扫描行数。其中Q1的结果好事符合预期的,rows的值是104620,但是Q2的rows的值是37116,偏差就大了,而图1中我们用explain命令看到row只有10001行,这个偏差误导了优化器的判断。那么为什么优化器不扫描37000行的执行计划,而选择了扫描行数是100000的执行计划呢。
这是因为如果使用索引a,每次从索引a上拿到一个值,都要回到主键索引上查出整行数据,这个代价优化器也要算进去的。而入伙选择扫描10万行,是直接在主键索引上扫描的,没有额外的代价。优化器会估算这两个选择的代价,从结果来看,优化器认为直接扫描主键索引更快,当然能,从执行时间来看,这个选择并不是最优的。
使用普通索引需要把回表的代价算进去,在图1执行explain的时候,页考虑了这个策略的代价,但是图1的选择是对的。也就是说,这个策略并没有问题。所以MySQL选错索引,还要归咎到没有能判断出扫描行数,值域为什么会得到错误的扫描行数,这个问题需要考虑。
通过analyze table 命令,可以用来重新统计索引信息。下图为执行此语句后的执行效果。
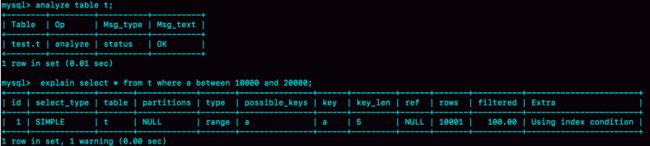
如果我们发现explain的结果预估的rows值跟实际情况差距比较大,可以采用这个方法处理,如果只是索引统计不准确,通过analyze命令可以解决很多问题,但是,优化器不仅仅是看扫描行数。
另一个例子
依然是基于这个表t,我们看下面SQL语句
select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order by b limit 1;
从条件上看,这个查询没有符合条件的记录,因此会返回空集合,我们可以设想一下,如果我们来选择索引,会选择哪一个
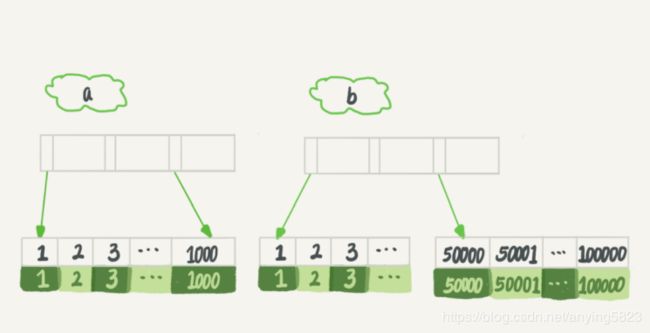
如上图所示,如果使用a进行查询,那么就是扫描索引a的前1000个值,然后取到对应的id,再到主键索引上去查出每一行,然后根据字段b来guolv,显然这样需要扫描1000行。
如果索引b进行查询,那么就是扫描索引b的最后50001个值,与上面的执行过程先攻,也是需要回到主键索引上取值再判断,此时需要扫描50001行。所以你一定回想,如果使用索引a的话,执行速度会明显快很多,我们就来看看到底是不是这么一回事。
我们执行explain
explain select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order by b limit 1;

可以看到返回结果中key字段显示,这次优化器选择了索引b,而rows字段显示需要扫描的行数是50198.
- 从这个结果,我们得到两个结论,扫描行数的估计智依然不准确
- 这个例子里面MySQL有选错的索引。
索引选择异常处理
大多数时候优化器都能找到正确的索引,但是偶尔还是会碰到我们上面举例的两种情况:原本可以执行的很快的SQL语句,执行速度却比你预期的慢很多,我们应该怎么办?
第一种方法,force index强行选择一个索引,MySQL会根据词法分析解惑分析出可能可以使用的索引作为候选项,然后再候选列表中判断每个索引需要扫描多少行。如果force index指定的索引在候选索引列表中,就直接选择这个索引,不在评估其他索引的执行代价。
第二种方法,我们可以考虑修改语句,引导MySQL使用我们期望的索引,比如,在这个例子中,我们的 order by b limit 1 改成 order by b,a limit 1,语义逻辑时相同的。我们看看更改之后的效果。

之前优化器选择使用索引b,是因为它认为使用索引b可以避免排序,b本身是索引,已经有序,如果选择索引b,不需要再做排序,只需要遍历,即使扫描行数多,页判定为代价更小。如果更改为order by b,a limit 1,就一位这使用这两个索引都需要排序,因此,扫描行数成了影响决策的主要条件,于是此时优化器会选择值需要扫描1000行的索引a。
第三种方法,在有些场景下,我们可以新建一个更合适的索引,来提供给优化器做选择,或删掉误用的索引。
如何给字符串字段加索引
另一个例子
例如一个邮箱登陆系统,用户表是这么定义的
create table SUser(
ID bigint unsigned primary key,
email varchar(64),
...
)engine=InnoDB
要使用邮箱登陆的话,业务逻辑代码中一定会出现类似这样的语句:
select f1,f2 from SUser where email=“xxx”;
如果email字段上没有索引,那么这个语句就只能做全表扫描。
我们有两种方法给email字段上创建索引
alter table SUser add index index1(email);
alter table SUser add index index2(email(6));
第一个语句创建的index1索引里面,包含了每个记录的整个字符串;第二个语句创建的index2索引里面,对于每个记录都只取前6个字节。
下图所示为两种索引创建的区别
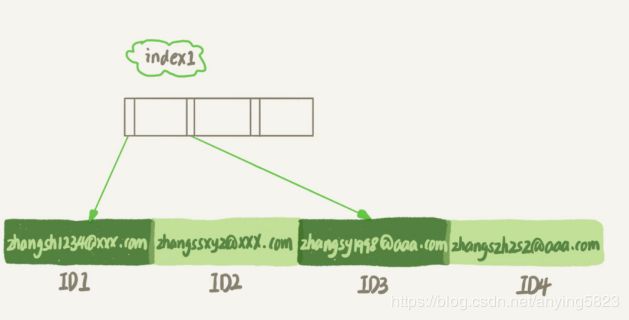
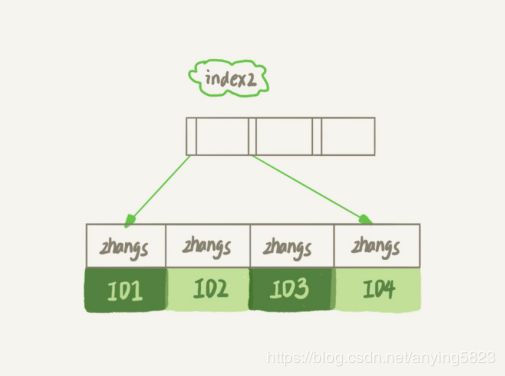
我们来分析这两种索引分别是怎么执行上述查询语句的
如果是第一种索引
- 从index1索引树找到满足索引值是"[email protected]"的这条记录,取得ID2的值;
- 到主键上查到主键是ID2的行,判断email的值是正确的,讲这条记录加入结果集
- 到index1索引树上刚刚查到位置的下一条记录,发现已经不满足[email protected]的条件了,循环结束。
如果使用的是index2,执行顺序是这样的:
- 从index2索引树找到满足索引值是zhangs的记录,找到第一个是ID1;
- 到主键上查到主键值是ID1的行,判断出email的值不是[email protected],这行记录丢弃。
- 取index2上刚刚查到的位置的下一条记录,发现征战史zhangs,取出ID2,在待ID索引上取整行然后判断,这次值对了,将这行记录加入结果集。
- 重复上一次,知道值不是zhangs时,循环结束
因此我们发现,使用前缀索引后,可能呆滞查询语句度数据的次数表多。我们可以得到结论使用前缀索引,定义好长度,就可以做到既节省空间,有不用额外增加太多的查询成本。
我们在建立索引的时候关注的时字段中不同行之间的区分度,区分度越高越好,因为区分度越高,意味着重复的键越少。因此,我们可以通过统计索引上有多少个不同的值来判断要使用多长的前缀。
前缀索引堆覆盖索引的影响
我们来看一个SQL语句
select id,email from SUser where [email protected];
这个语句只要求返回id和email字段。如果使用index1的话,可以利用覆盖索引,从index1查到结果就返回了,不需要返回到ID索引再去查一次,但是如果使用index2的话,就需要回到ID索引在其判断email字段的值。
因此前缀索引就用不上覆盖索引堆查询性能的优化了,这也是我们在选择是否使用前缀索引时需要考虑的一个因素。
其他的方法
有时候前缀索引可能区分度不是特别高,这个时候,我们一般有两种方法
- 倒序存储
select field_list from t where id_card = reverse('input_id_card_string');
因为身份证号的后六位没有重复的逻辑,所以可以这样做
- 使用hash字段
alter table t add id_card_crc int unsigned , add index(id_card_crc);
每次插入新记录的时候都使用crc32来得到校验码填到这个新字段。由于hash值可能存在冲突,因此在查询时where部分需要判断id_card是否精确相同。
- 相同点
不支持倒叙查找,只支持等值查询。
-
不同点
- 从占用空间来看,倒叙查找建立在原有字段上,不会消耗额外的空间,但是hash字段方法需要增加一个字段,当然,倒叙存储方式使用了4个字节的前缀长度应该时不够的,如果在长一点,这个消耗跟额外这个hash字段也差不多抵消了。
- 在CPU消耗方面,倒叙方式每次写和读的时候,都需要额外调用一次reverse函数,而在hash字段的方式需要额外调用一次crc32()函数。如果只从这两个函数的计算复杂度来看的话,reverse函数额外消耗的CPU资源会更小些。
- 从查询效率上来看,使用hash方式的查询性能要更稳定一些。