shell基本命令以及正则表达式
1.diff命令
diff命令是用来比较两个文件或目录的不同
a表示添加 ---add
c表示更改 --change
d表示删除 --delete
[num1,num2][a|b|c][num3,num4]
num1,num2表示第一个文件中的行数
num3,num4表示第二个文件中的行数。
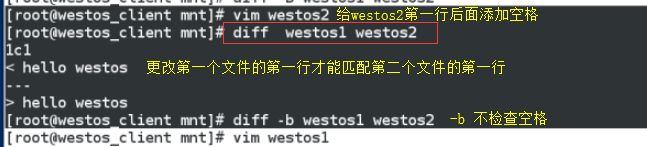
< 表示第一个文件的内容,>表示第二个文件的内容,---分割线
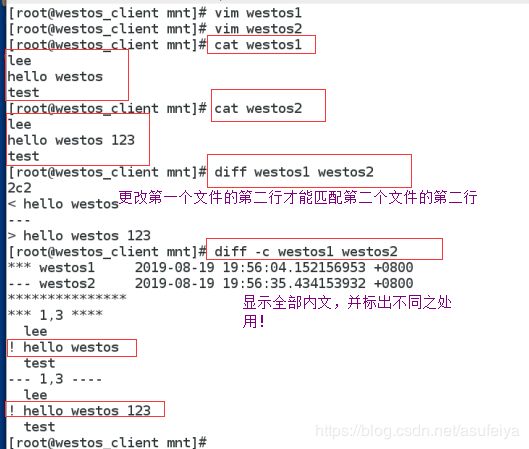
2,4c2,4表示改变第一个文件中的第二行和第四行才能匹配第二个文件中的第二行和第四行。
diff 中常用的参数:
-b 或 --ignore-space-change 不检查空格字符的不同
-B 或 --ignore-blank-lines 不检查空白行
-c 显示全部内文,并标出不同之处
-i 或 --ignore-case 不检查大小写的不同
-p :若比较的文件为 C 语言的程序码文件时,显示差异所在的函数名称;
-q 或 --brief :仅显示有无差异,不显示详细的信息
-r 或 --recursive :比较子目录中的文件
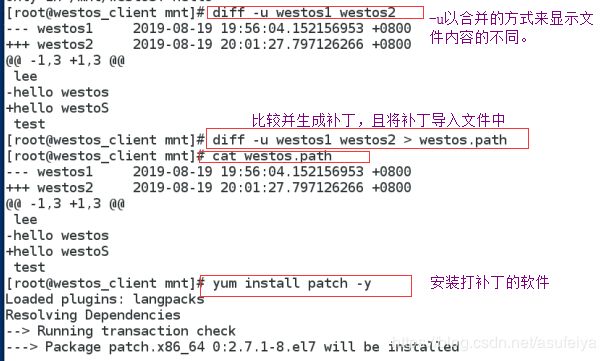
-u 以合并的方式来显示文件内容的不同
diff命令
diff file file1 比较文件的不同(以第二个文件为主)
diff -u file file1 比较文件的不同并生成补丁
diff -u file file1 > file.path 将补丁导入文件中(也可以不以.path结尾)
diff -r westos/ mnt/ 比较两个目录
yum install patch -y 安装打补丁的软件
patch file file.path 给file文件打补丁,使得file和file1相同
patch -b file file.path 给file文件打补丁,并保留原文件.orig文件
patch 用于文件不同打布丁
patch [options] file.old file.path
-b





3.cut命令(截取文件)
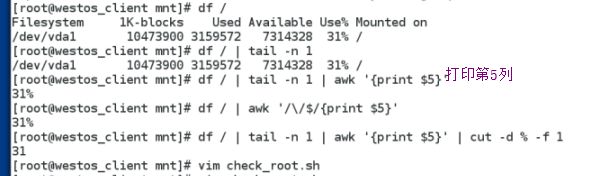
cut -d : -f 1 file 截取该文件的第一列 (-d 后跟分隔符)
cut -d : -f 1,3 file 截取文件的第一列和第三列
cut -d : -f 1-3 file 截取文件的1,2,3列
cut -d : -f 3- file 截取文件第三列以后的所有列
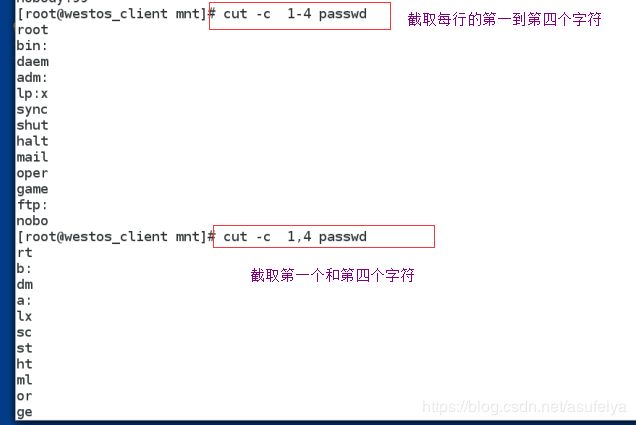
cut -c 1 file 截取文件的第一个字符
cut -c 1,4 截取文件的第一个和第四个字符
cut -c 1-4 截取文件的第一个到第四个字符


 例:
例:
只显示ip
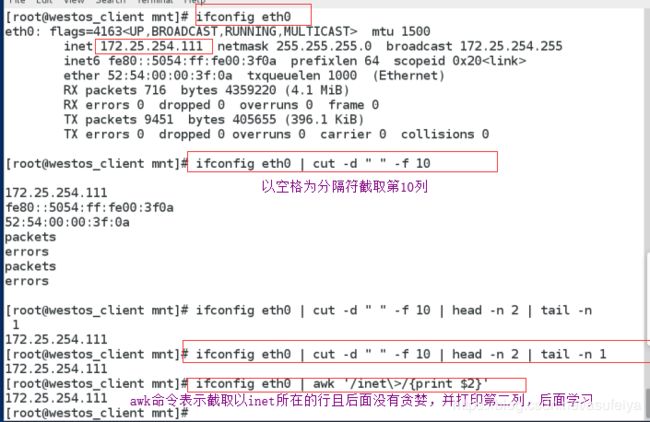
5.sort和uniq
sort -n 按纯属字排序(升序)
sort -r 倒序
sort -u 去掉重复数字
sort -o 输出到指定文件
sort -t 指定分隔符
sort -k 指定要排序的列
uniq -c 输出每个的个数并将重复的只输出一次
uniq -d 输出重复的
uniq -u 输出不重复的





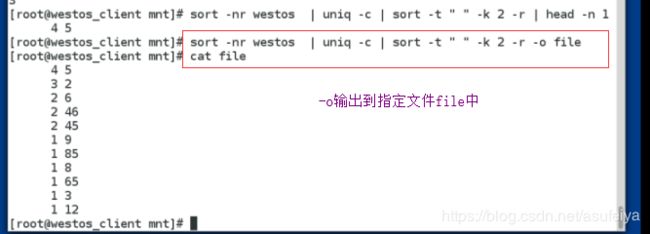
例:
cp /etc/* /mnt
ls 查看
抓出文件大小排名前五的文件名称


########&& 和 ||############
&& 用来执行条件成立后执行的命令
|| 用来执行条件不成立后执行的命令
例如:
ping -c1 -w1 172.25.254.111 && echo up
ping -c1 -w1 172.25.254.111 || echo up
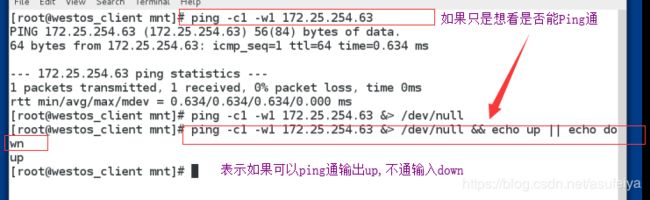
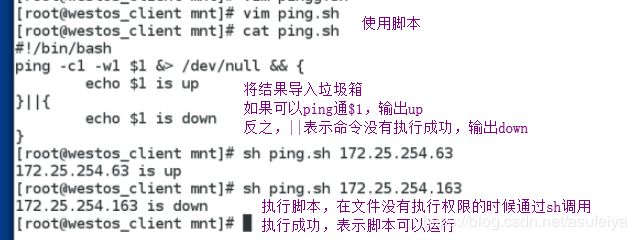
练习:ping 一个ip能ping通显示upping不通显示down
例如:
[root@shell mnt]# chmod 755 ping.sh ##给文件执行权限
[root@shell mnt]# vim ping.sh ##编辑文件
[root@shell mnt]# cat ping.sh
ping -c1 -w1 $1 &> /dev/null && echo $1 is up || echo $1 is down
[root@shell mnt]# . ping.sh 172.25.254.111 ##测试
172.25.254.111 is up
[root@shell mnt]# . ping.sh 172.25.254.103
172.25.254.103 is down
[root@shell mnt]# . ping.sh 172.25.254.203
172.25.254.203 is up
test命令
test命令和[]等同 []并且两边必须有空格
[ "$A" = "$B" ] =
[ "$A" != "$B" ] != ##不等于
[ "$A" -eq "$B" ] =
[ "$A" -ne "$B" ] !=
[ "$A" -le "$B" ] <=
[ "$A" -lt "$B" ] <
[ "$A" -ge "$B" ] >=
[ "$A" -gt "$B" ] >
[ "$A" -ne "$B" -a "$A" -gt "$B" ] !=并且>
[ "$A" -ne "$B" -o "$A" -gt "$B" ] !=或>
[ -z "$A" ] 文件为空
[ -n "$A" ] 文件为非空


挂载根下的Used下的值如果大于30%就给/var/log/messages输出警告信息,且每分钟检测一次。






[ "file1" -ef "file2" ] ##file1和file2是否为同一文件
[ "file1" -nt "file2" ] ##file1是否比file2新
[ "file1" -ot "file2" ] ##file1是否比file2老


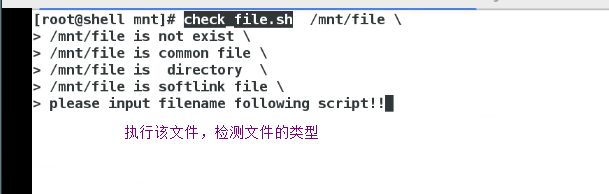
[ -e " file" ] 是否存在
[ -f " file" ] 是否普通文件
[ -L " file" ] 是否软链接
[ -b " file" ] 是否是块设备
[ -S " file" ] 是否套接字
[ -d " file" ] 是否是目录
[ -c " file" ] 是否是字符设备
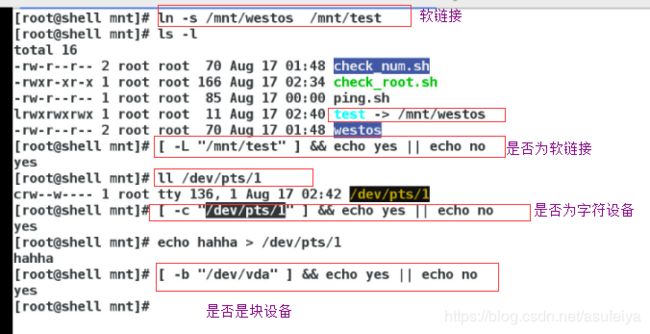
eg:
检测文件的类型



输入无论大小写时均可通过tr转换大小写

#################################
1.grep(过滤搜索正则表达式)
grep ##命令是一种强大的文体搜索工具,根据用户指定的“模式”,
##对目标文本进行匹配检查,打印匹配到的行,由正则表达式
##或者字符及基本文字字符所编写的过滤条件
grep root passwd 含有root关键字的行
grep ^root passwd root开头的行
grep root$ passwd root结尾的行
grep -i ^root passwd root在开头的行不去分大小写
grep -i -E "^root|root$" passwd -E=\(转译字符)加-E后可以不使用
grep -i root passwd ##无论大小写都显示
grep -E "root|ROOT" passwd
-v 反向过滤,输出不符合条件的
-E 拓展正则表达式
-i 不区分大小写
grep -E =egrep
步骤:
170 cp /etc/passwd .
171 ls
174 vim passwd
175 cat passwd

176 grep root passwd ##过滤包含root的行
177 grep -E "root|ROOT" passwd ##过滤包含大小写的,-E表示或者
179 grep -Ei "root" passwd ##大小写都过滤可以用-i,不区分大小写
180 grep -Ei "^root" passwd ##过滤以root开头的
181 grep -Ei "root$" passwd ##过滤以root结尾的
182 grep -Ei "^root|root$" passwd ##过滤以root开头的或以root结尾的

183 grep -Ei "^root|root$" passwd -v ##-v过滤除此之外的其他,条件的反向输出
184 grep -Ei "^root|root$" passwd -v | grep root ##过滤出包含root的行
185 grep -Ei "^root|root$" passwd -n ##过滤且显示所在行数
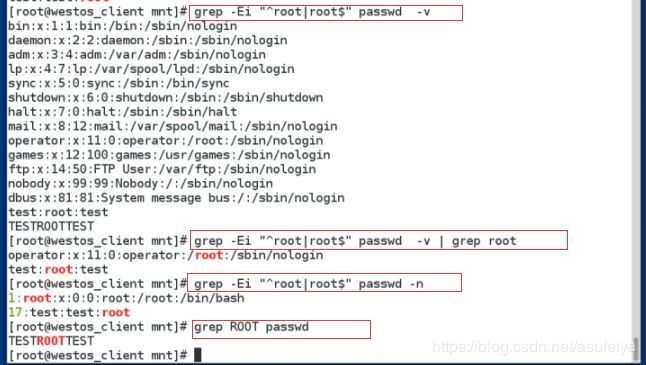
186 grep ROOT passwd -n ##过滤ROOT且显示行数
187 grep ROOT passwd -2 ##过滤出ROOT所在行以及所在上下两行
188 grep ROOT passwd -1
189 grep ROOT passwd -n1 ##过滤出ROOT所在行以及所在上下行并显示行数
190 grep ROOT passwd -A1 ##过滤出ROOT行以及下一行
191 grep ROOT passwd -B1 ##过滤出ROOT行以及上一行
grep 中的正则表达式
^westos
westos$
'w....s'
'w.....'
'.....s'
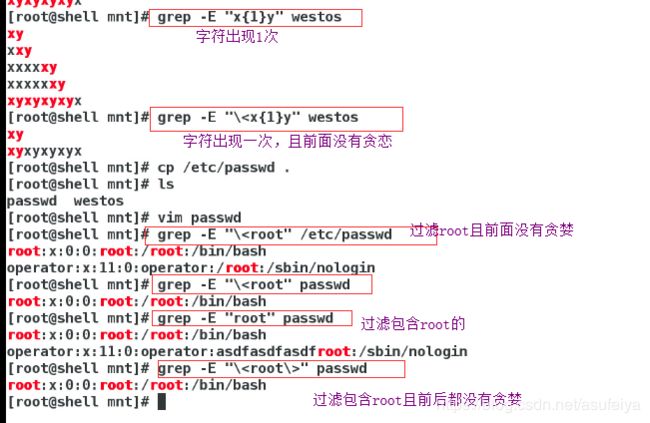
grep 中字符的匹配次数设定
* 字符出现 [0- 任意次 ]
? 字符出现 [0-1 次 ]
+ 字符出现 [1- 任意次 ]
{n} 字符出现 [n 次 ]
{m,n} 字符出现 [ 最少出现 m 次,最多出现 n 次 ]
{0,n} 字符出现 [0-n 次 ]
{m,} 字符出现 [ 至少 m 次 ]
(xy){n}xy 关键字出现 [n 次 ]
.* 关键字之间匹配任意字符



###grep 正则表达式与扩展正则表达式
正规的 grep 不支持扩展的正则表达式子 , 竖线是用于表示”
或”的扩展正则表达式元字符 , 正规的 grep 无法识别
加上反斜杠 , 这个字符就被翻译成扩展正则表达式 , 就像 egrp
和grep -E 一样
sed 行编辑器
stream editor
用来操作纯 ASCII 码的文本 处理时 , 把当 前处理的行存储在临时缓冲区中 , 称为“模式空 间” (pattern space) 可以指定仅仅处理哪些行 sed 符合模式条件的处理 不符合条件的不予处理
处理完成之后把缓冲区的内容送往屏幕
接着处理下一行 , 这样不断重复 , 直到文件末尾Sed 命令格式
调用 sed 命令有两种形式:
sed [options] 'command' file(s)
sed [options] -f scriptfile file(s)
sed 对字符的处理
p 显示
d 删除
a 添加
c 替换
w 写入
i 插入
p模式操作
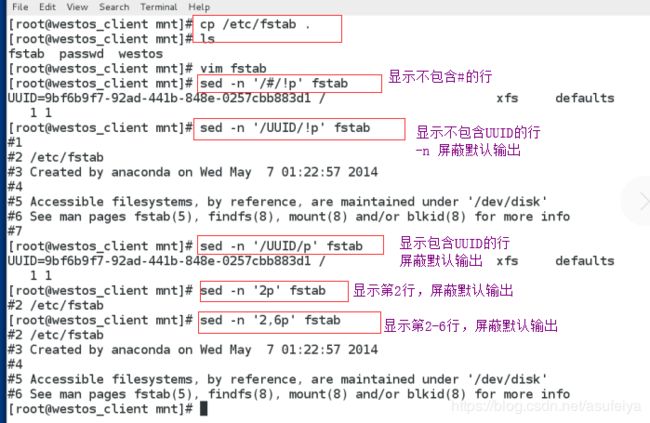
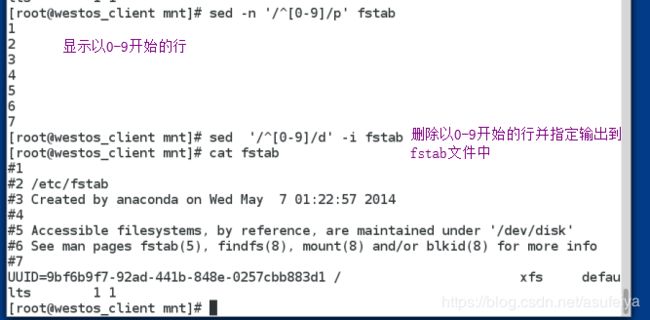
sed -n '/\:/p' fstab
sed -n '/UUID$/p'fstab
sed -n '/^UUID/p' fstab
sed -n '2,6p' fstab
sed -n '2,6!p' fstab


d 模式操作
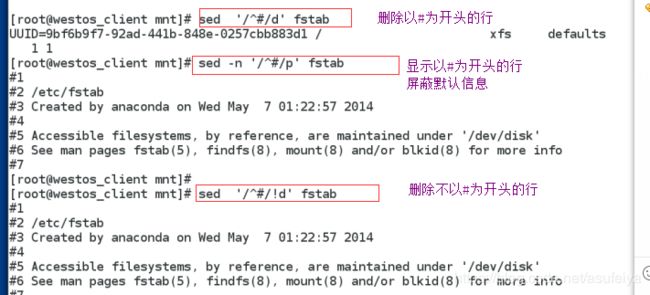
sed '/^UUID/d' /etc/fstab
sed '/^#/d' /etc/fstab
sed '/^$/d'/etc/fstab
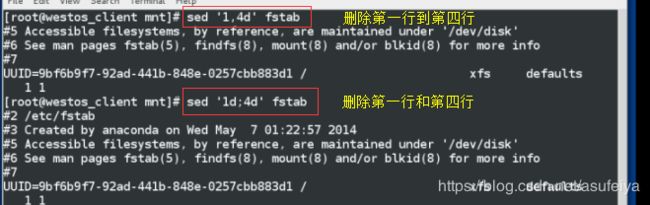
sed '1,4d'/etc/fstab
sed –n '/^UUID/!d' /etc/fstab


a 模式操作
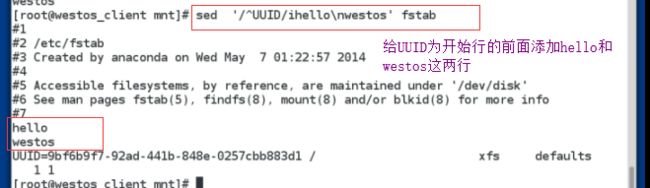
sed '/^UUID/a \hello sed /etc/fstab
sed '/^UUID/a \hello sed\nwestos /etc/fstab’i 模式操作
sed '/^UUID/i\hello sed\nwestos /etc/fstab’c 模式操作
sed ‘/^UUID/c\hello sed\nwestos /etc/fstab’

sed '/^UUID/i\hello sed\nwestos' fstab 在UUID的前一行插入hello sed和westos

w 模式操作
sed '/^UUID/w /tmp/fstab.txt' /etc/fstab
sed -n'/^UUID/w /tmp/fstab.txt' /etc/fstab
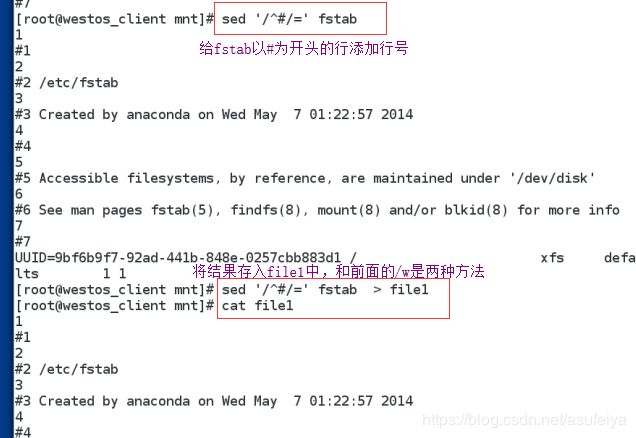
sed '/^UUID/='/etc/fstab
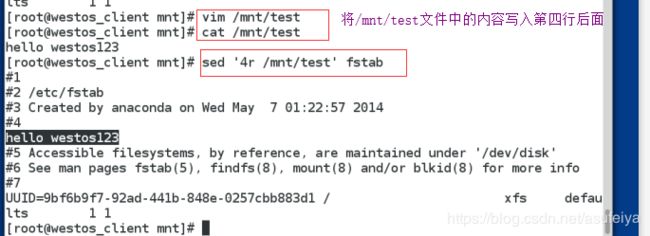
sed '6r /etc/issue' /etc/fstab

sed 的其他用法
sed -n '/^UUID/=' fstab
sed -n -e '/^UUID/p' -e '/^UUID/=' fstab
sed -e 's/brown/green/; s/dog/cat/' data
sed -f rulesfile file
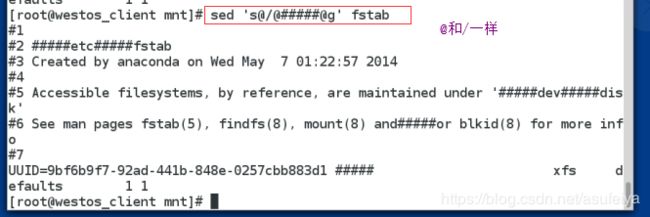
sed 's/^\//#/'/etc/fstab
sed 's@^/@#@g'/etc/fstab
sed 's/\//#/'/etc/fstab
sed 's/\//#/g/'/etc/fstab
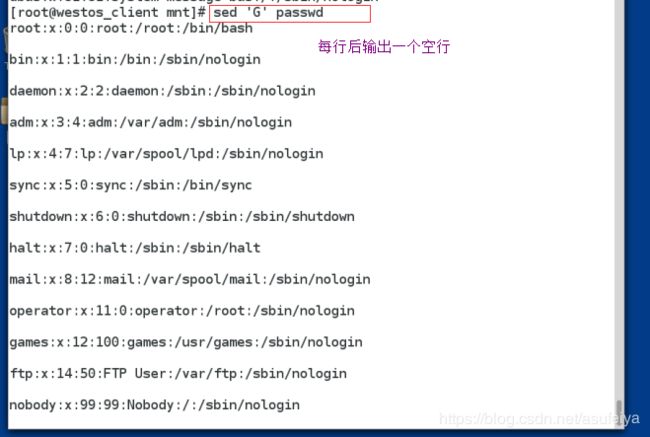
sed 'G' data
sed '$!G' data
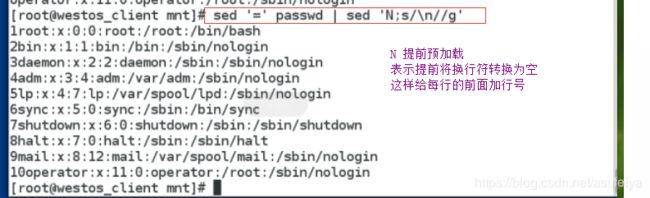
sed '=' data | sed 'N; s/\n/ /'
sed -e 一个程序 处理一行存一行 更高效
> 两个程序 处理完之后存入
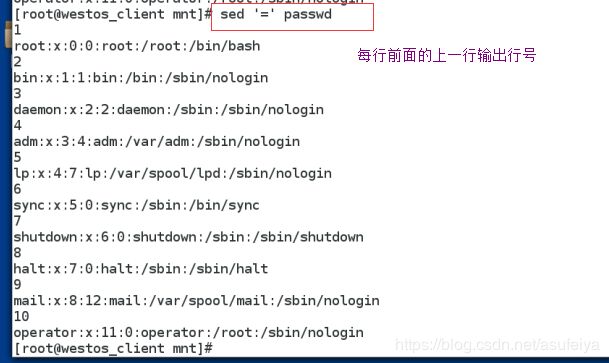
= 加入行号
i 将输出的结果指定输出到文件,将改变的内容存入源文件中,更改文件的内容
6r 将文件写入第六行后
$r 将文件内容写入末行
r 将文件内容写入每一行

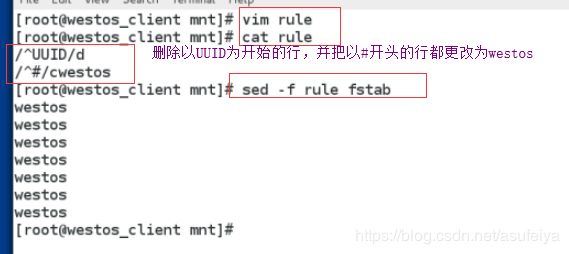
 将规则写入文件,并利用规则中的文件更改fstab文件
将规则写入文件,并利用规则中的文件更改fstab文件
替换模式
sed 's/nologin/westos/g' passwd 全文替换
sed '3,5s/nologin/linux/g' passwd 3,5行的替换



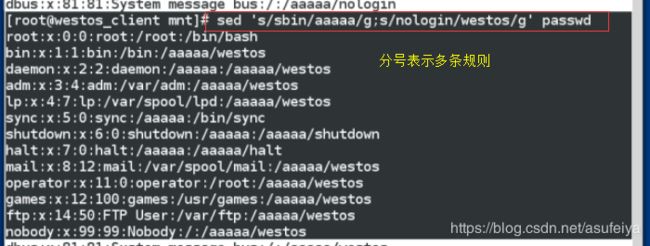
sed '/lp/,/gdm/s/nologin/linux/g' passwd 关键字到关键字行替换
sed -e '/lp/,/gdm/s/nologin/linux/g;s/sbin/123/g' passwd 多条规则替换

sed '=' fstab | sed 'N;s/\n/ /g'
sed 'G' fstab
sed '$!G' fstab
sed -n '$p' fstab


awk 报告生成器
awk 处理机制:awk 会逐行处理文本,支持在处理第一行之前做一些准备工作,以及在处理完最后一行做一些总结性质的工作,在命令格式上分别体现如下:
BEGIN{}:读入第一行文本之前执行,一般用来初始化操作
{}:逐行处理,逐行读入文本执行相应的处理,是最常见的编辑指令快
END{}:处理完最后一行文本之后执行,一般用来输出处理结果
awk 基本用法
linux 上面默认使用 gawk
awk '{print FILENAME}' passwd
awk '{print 第"NR"行,有"NF"列}'
awk 'BEGIN{print NAME}'
awk 'END{print WESTOS}'
awk -F : 'BEGIN{print NAME}{print $1}END{WESTOS}'
awk '/bash$/'
awk -F : '/bash$/{print $1}'





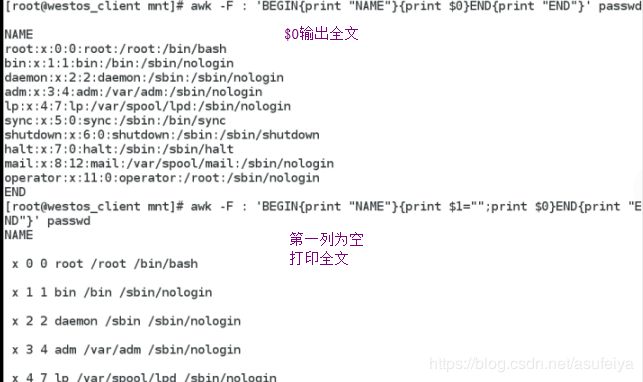

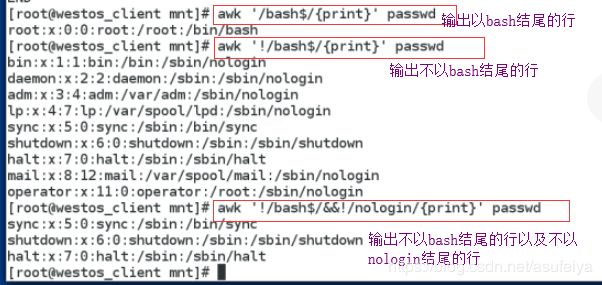


awk 的基本用法
awk 'BEGIN{a=34;print a+12}'
awk -F : '/^ro/{print}' /etc/passwd
awk -F : '/^[a-d]/{print $1,$6}' passwd.txt
awk -F : '/^a|nologin$/{print $1,$7}' passwd.txt
awk -F : '$6~/bin$/{print $1,$6}'
awk -F : '$7!~/nologin$/{print $1,$7}' passwd.txt



