Python 随机森林的实现与参数优化
关注微信公共号:小程在线
关注CSDN博客:程志伟的博客
通过n_estimators,random_state,boostrap和oob_score这四个参数了解袋装法的基本流程和重要概念。
estimators_ 和 .oob_score_ 这两个重要属性。
随机森林也有.feature_importances_这个属性。
Python 3.7.3 (default, Apr 24 2019, 15:29:51) [MSC v.1915 64 bit (AMD64)]
Type "copyright", "credits" or "license" for more information.
IPython 7.6.1 -- An enhanced Interactive Python.
导入需要的包
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
导入需要的数据集,并查看数据的情况
wine = load_wine()
wine.data
Out[3]:
array([[1.423e+01, 1.710e+00, 2.430e+00, ..., 1.040e+00, 3.920e+00,
1.065e+03],
[1.320e+01, 1.780e+00, 2.140e+00, ..., 1.050e+00, 3.400e+00,
1.050e+03],
[1.316e+01, 2.360e+00, 2.670e+00, ..., 1.030e+00, 3.170e+00,
1.185e+03],
...,
[1.327e+01, 4.280e+00, 2.260e+00, ..., 5.900e-01, 1.560e+00,
8.350e+02],
[1.317e+01, 2.590e+00, 2.370e+00, ..., 6.000e-01, 1.620e+00,
8.400e+02],
[1.413e+01, 4.100e+00, 2.740e+00, ..., 6.100e-01, 1.600e+00,
5.600e+02]])
wine.target
Out[4]:
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2])
sklearn建模的基本流程,将决策树与随机森林进行对比建立
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
clf = DecisionTreeClassifier(random_state=0)
rfc = RandomForestClassifier(random_state=0)
clf = clf.fit(Xtrain,Ytrain)
rfc = rfc.fit(Xtrain,Ytrain)
score_c = clf.score(Xtest,Ytest)
score_r = rfc.score(Xtest,Ytest)
print("Single Tree:{}".format(score_c)
,"Random Forest:{}".format(score_r)
)
Single Tree:0.8888888888888888 Random Forest:0.9814814814814815
H:\Anaconda3\lib\site-packages\sklearn\ensemble\forest.py:245: FutureWarning: The default value of n_estimators will change from 10 in version 0.20 to 100 in 0.22.
"10 in version 0.20 to 100 in 0.22.", FutureWarning)
画出随机森林和决策树在一组交叉验证下的效果对比,随机森林明显高于决策树
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf,wine.data,wine.target,cv=10)
plt.plot(range(1,11),rfc_s,label = "RandomForest")
plt.plot(range(1,11),clf_s,label = "Decision Tree")
plt.legend()
plt.show()


画出随机森林和决策树在十组交叉验证下的效果对比
rfc_l = []
clf_l = []
for i in range(10):
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
rfc_l.append(rfc_s)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf,wine.data,wine.target,cv=10).mean()
clf_l.append(clf_s)
plt.plot(range(1,11),rfc_l,label = "Random Forest")
plt.plot(range(1,11),clf_l,label = "Decision Tree")
plt.legend()
plt.show()
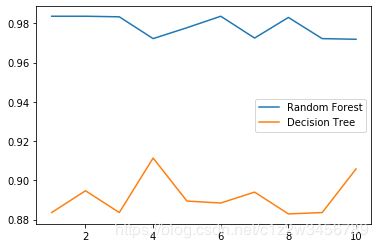 

n_estimators的学习曲线
superpa = []
for i in range(200):
rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
superpa.append(rfc_s)
print(max(superpa),superpa.index(max(superpa)))
plt.figure(figsize=[20,5])
plt.plot(range(1,201),superpa)
plt.show()
0.9888888888888889 24

rfc = RandomForestClassifier(n_estimators=20,random_state=2)
rfc = rfc.fit(Xtrain, Ytrain)
随机森林的重要属性之一:estimators,查看森林中树的状况
rfc.estimators_[0].random_state
Out[12]: 1872583848
for i in range(len(rfc.estimators_)):
print(rfc.estimators_[i].random_state)
1872583848
794921487
111352301
1853453896
213298710
1922988331
1869695442
2081981515
1805465960
1376693511
1418777250
663257521
878959199
854108747
512264917
515183663
1287007039
2083814687
1146014426
570104212
bootstrap用来控制抽样技术的参数
#无需划分训练集和测试集
rfc = RandomForestClassifier(n_estimators=25,oob_score=True)
rfc = rfc.fit(wine.data,wine.target)
#重要属性oob_score_
rfc.oob_score_
Out[14]: 0.9775280898876404
rfc = RandomForestClassifier(n_estimators=25)
rfc = rfc.fit(Xtrain, Ytrain)
rfc.score(Xtest,Ytest)
Out[15]: 1.0
#变量的重要性
rfc.feature_importances_
Out[16]:
array([0.142124 , 0.01909514, 0.02403409, 0.01899112, 0.0193338 ,
0.02468989, 0.13933826, 0.00954206, 0.0209506 , 0.11482895,
0.11151954, 0.12664953, 0.22890302])
#变量在每棵树中叶子节点的位置
rfc.apply(Xtest)
Out[17]:
array([[17, 8, 20, ..., 16, 19, 10],
[17, 8, 20, ..., 16, 20, 10],
[ 4, 1, 2, ..., 4, 2, 1],
...,
[ 8, 3, 2, ..., 5, 17, 1],
[ 8, 3, 2, ..., 5, 17, 1],
[ 4, 1, 10, ..., 7, 4, 4]], dtype=int64)
#被预测的类别
rfc.predict(Xtest)
Out[18]:
array([0, 0, 1, 2, 2, 1, 2, 1, 2, 2, 0, 1, 0, 0, 1, 2, 0, 1, 0, 1, 0, 0,
0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 2, 1, 2, 2, 0, 0, 1, 2, 2, 1, 0, 1,
1, 1, 0, 2, 1, 0, 1, 1, 1, 2])
#被预测为某类的概率
rfc.predict_proba(Xtest)
Out[19]:
array([[0.64, 0.36, 0. ],
[1. , 0. , 0. ],
[0. , 0.84, 0.16],
[0. , 0.04, 0.96],
......
[0.04, 0.96, 0. ],
[0. , 0.12, 0.88]])