Efficientdet学习笔记 --- EfficientDet: Scalable and Efficient Object Detection
论文:https://arxiv.org/abs/1911.09070
代码1(官方):https://github.com/google/automl/tree/master/efficientdet
代码2(最强复现):https://github.com/zylo117/Yet-Another-EfficientDet-Pytorch
上周Efficientdet的最强复现Pytorch版出来后,用它训练了自己的数据,感觉很不错,所以觉得有必要好好学习一下Efficientdet,先实践后理论~~~~~~~~
附上我训练自己数据的Efficientdet-D0的一张图片测试结果(图片过于简单,不要喷我):

重点是这张图片的infer速度:
test1: model inferring and postprocessing
inferring image for 1 times...
0.003389120101928711 seconds, 295.06183608863876 FPS, @batch_size 1
接近300FPS!!!美滋滋。。。。。。。。
言归正传,先直接看Efficientdet的效果:
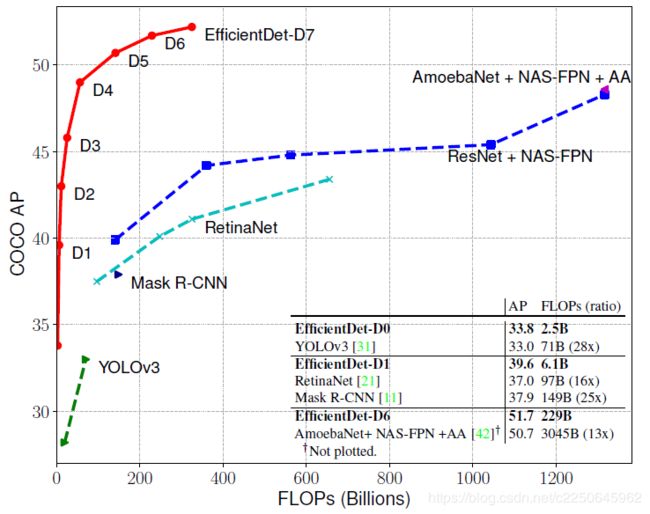
由图可以看出,Efficientdet系列的入门版Efficientdet-D0都比YoloV3具有0.8提升,并且减少28倍的FLOPS!Efficientdet-D6达到了51.7的map!的state-of-the-art 结果,相对于AmoebaNet + NAS-FPN 相比,FLOPS 仅为其十三分之一。
为何EfficientDet有如此惊人效果?主要依靠一下三个点:
1.优秀的主干网络。同样出自谷歌家族的 。
2.双向FPN(BiFPN,特征金字塔网络)。可以方便且更好的进行特征融合。
3.模型缩放技术。设计好模型的主干网络、特征网络、预测网络后,按照一定的优化规则,在网络的深度、宽度、输入图像的分辨率上进行模型缩放,故EfficientDet其实是一系列网络,可在统一架构下得到适合移动端和追求高精度的多个模型。
主干网络
Backbone采用谷歌去年出的Efficientnet系列,Efficientnet系列不用多说,是谷歌利用NAS方法,基于深度(depth),宽度(width),输入图片分辨率(resolution)的共同调节统一缩放模型的所有维度,达到精度最高效率最高。

BiFPN
BiFPN的主要思想:有效的双向交叉尺度连接和加权特征融合。

有效的双向交叉尺度连接
传统的top-down FPN只有自顶向下单向信息流,PANet增加了自底向上的信息流,NAS-FPN通过大量计算和搜索有更复杂的信息流。
传统的top-down FPN的定义方式如下:

第7层输出特征图是由第7层输入特征图经过一个卷积后得到的。对第7层输出特征图进行上采样后与第6层输入特征图相加所得的融合特征图做卷积,就可以得到第6层输出特征图。依此类推,对第4层输出特征图进行上采样后与第3层输入特征图相加所得的融合特征图做卷积,就可以得到第3层输出特征图。
可是传统的自上而下的FPN固有地受到单向信息流的限制。为了解决这个问题,PANet 添加了一个额外的自下而上的路径聚合网络,如图2(b)所示。
NAS-FPN 使用神经架构搜索(NAS)来搜索更好的跨尺度特征网络拓扑,但是在搜索过程中需要数千个GPU小时,并且发现的网络不规则且难以解释或修改,如图2(c)所示。
作者观察到,PANet的精度比FPN和NAS-FPN更好,但是需要更多参数和计算。为了提高模型效率,本文针对跨尺度连接提出了几种优化方法:
- 首先,删除那些只有一个输入边的节点。 作者的直觉很简单:如果一个节点只有一个输入边且没有特征融合,那么它将对旨在融合不同特征的特征网络贡献较小。这会形成一个简化的双向网络。
- 其次,如果原始输入与输出节点处于同一级别,则在原始输入和输出节点之间增加一条额外的边,以便在不增加成本的情况下融合更多功能。
- 第三,与PANet仅具有一个自上而下和一个自下而上的路径不同,我们将每个双向(自上而下和自下而上)路径一个模块,并拼接相同的模块多次以启用更多高级功能融合。
后面有提到利用复合缩放方法来确定不同资源约束的层数。 通过这些优化,作者将新特征网络网络命名为双向特征金字塔网络(BiFPN)。
加权融合
对不同尺度的特征进行融合时,通常的做法是先将尺度统一,然后对应特征相加。这种做法默认不同的特征对于最终融合特征的贡献/权重是一样的。而实际上,不同的输入特征由于其分辨率不同,对最终的融合特征的贡献也应该不同。因此研究者提出在特征融合过程中为每一个输入添加额外的权重,再让网络学习每个输入特征的重要性。因此作者提出了三种加权的特征融合方法。
-
一般加权融合特征:
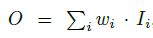
-
基于softmax的融合特征
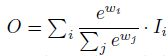
-
快速归一化融合特征

这种快速融合方法的学习行为和准确性与基于softmax的融合非常相似,但在GPU上的运行速度最高可提高30%,本文采用的就是快速归一化融合特征。
最终的BiFPN集成了双向跨尺度连接和快速归一化融合。 一个具体示例,作者描述了图2(d)所示的BiFPN在6级的两个融合特征:

Compound Scaling(模型联合缩放)
Efficientnet通过共同扩大网络宽度,深度和输入分辨率的所有维度,显示了在图像分类方面的卓越性能。受此启发,作者提出了一种新的用于对象检测的复合缩放方法,该方法使用简单的复合系数Φ来联合放大骨干网,BiFPN网络,分类/检测框网络和分辨率的所有维度。与Efficientnet不同,对象检测器的缩放比例要比图像分类模型高得多,因此对所有尺寸进行网格搜索的代价是昂贵的。因此,作者使用基于启发式的缩放方法,但仍然遵循共同扩大所有维度的主要思想。
- Backbone network
采用EfficientNet-B0 ~ B6, 其宽度w和深度d和它们7个网络也一样。
- BiFPN network
双向金字塔网络的宽度指数式增长,宽度线性增加:
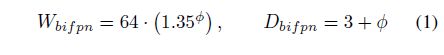
- Box/class prediction network
将其宽度固定为与BiFPN相同,
![]()
深度遵循以下公式:
![]()
- Input image resolution
由于BiFPN的输入是采用的骨干网络的P3~P7层,因此输入的图像的分辨率应该能被2^{7} = 128 整除,所以图像的分辨率应该满足如下公式:

至此,不同的Φ就得到了不同EfficientDet,如下图:
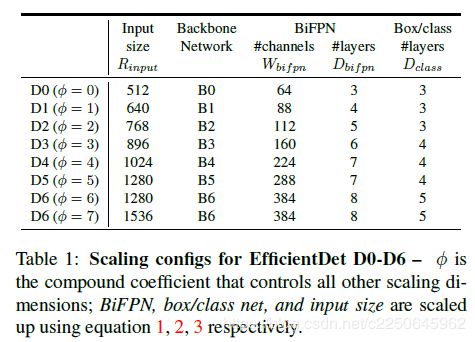
再次强调,只需一个参数控制input size, backbone, BiFPN layers和channels。
网络结构
综上,Efficientdet网络结构如下:
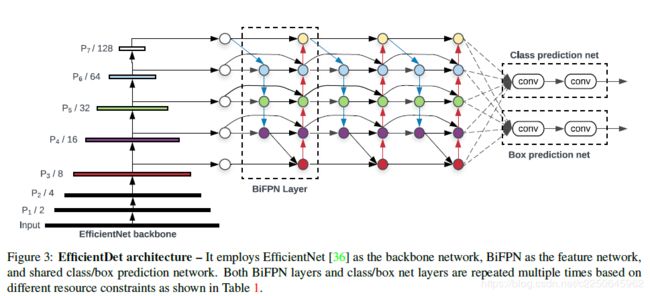
该结构由三部分组成,第一部分是由在ImageNet上预训练好的EfficientNet作为骨干网络;第二部分是BiFPN,作为特征提取网络,它将EfficientNet中的level 3~7的输出特征多次做top-down和bottom-up的特征融合;第三部分就是分类和检测框预测网络。第二部分和第三部的模块可以多次重复,依赖于硬件条件。
实验结果

牛逼!!
感想:很强,但是又怪怪的,backbone、模型缩放主要靠NAS搜索出来,但是这种采取NAS只有大厂才有资本去完成。
说到类FPN,其实都做烂了,后面也有用NAS搜索出来的更强的FPN结构~~~~~~
此外,backbone结构也陆续有大厂借助类NAS方法探索出了比Efficientnet更强的backbone结构,
比如最近Fackbook & 伯克利分校提出的FBNetV2:更轻、更快、更强。
颤抖吧~~~
参考:
https://zhuanlan.zhihu.com/p/93241232
https://zhuanlan.zhihu.com/p/93346058
https://blog.csdn.net/qwertyu_1234567/article/details/103885353