K8S+Harbor+gluster+haproxy 实践加坑
K8S+Harbor+gluster+haproxy 实践加坑
—阿特&Max Shen
半年未有blog,今日归来玩开源。莫问英雄归路,青山绿水总相逢。
一切缘起都是因为devops, 容器化已经很流行了。于是我们项目也打算从这方面发展。实践k8s 开始了痛苦之旅。 本着学习研究的找了文档看看,发现好像很简单,于是开了3台虚拟机,分分钟好像就可以完成构架。而走过一路发现所谓网上的种种文档,都是想当然的自己玩的开心。真的生产,要考虑的问题往往会复杂的多。
1、概述
-
docker ,就不讲了
-
k8s 是啥,不讲了
讲讲k8s 架构,否则搭建环境就算搞好了也是一头雾水。
k8s 是kubernetes 的简写,ks中间正好8个字母。不知道谁起名了 k8s。
这个集群主要包括两个部分:
- 一个Master节点(主节点)
- 一群Node节点(计算节点)
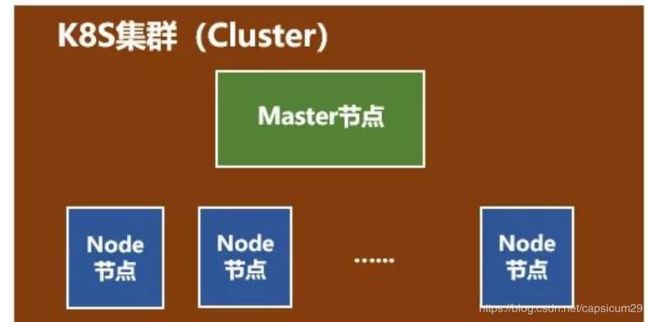
从命名来看就知道 Master节点主要还是负责管理和控制。Node节点是工作负载节点,里面是具体的容器。
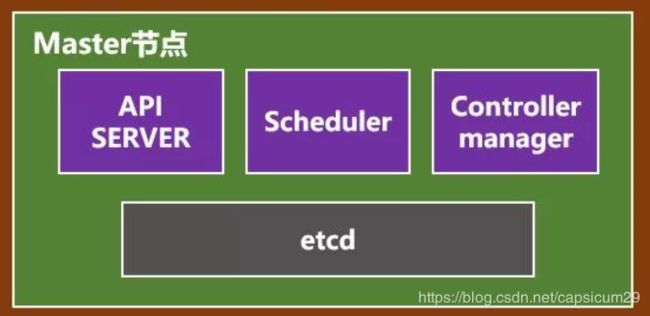
master 节点
Master节点包括API Server、Scheduler、Controller manager、etcd。
API Server是整个系统的对外接口,供客户端和其它组件调用 。
Scheduler负责对集群内部的资源进行调度 。
Controller manager负责管理控制器 。
etcd是一个高可用的分布式键值(key-value)数据库。etcd内部采用raft协议作为一致性算法,etcd基于Go语言实现。主要存储配置数据
Node节点
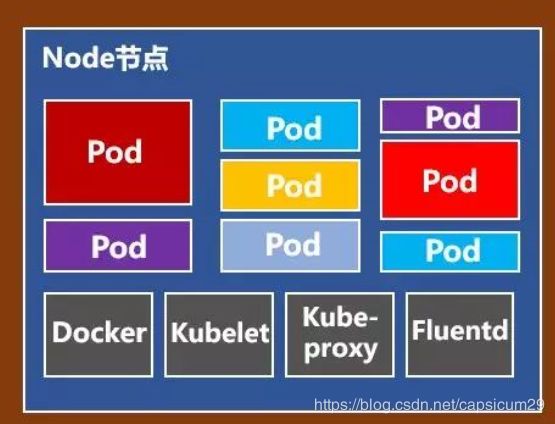
Node 节点简言之就是工作节点。
Node节点包括Docker、kubelet、kube-proxy、Fluentd、kube-dns(可选),还有就是Pod。
Pod是Kubernetes最基本的操作单元。一个Pod代表着集群中运行的一个进程,它内部封装了一个或多个紧密相关的容器。除了Pod之外,K8S还有一个Service的概念,一个Service可以看作一组提供相同服务的Pod的对外访问接口。
Docker,不用说了,创建容器的。
Kubelet,主要负责监视指派到它所在Node上的Pod,包括创建、修改、监控、删除等。
Kube-proxy,主要负责为Pod对象提供代理。
Fluentd,主要负责日志收集、存储与查询。
看了上面是不是感觉有点晕了? 是的,后来会更晕。
深入理解概念
引用博客 https://blog.csdn.net/maoyeqiu/article/details/79270625 的介绍
再来理解一遍
k8s这个容器管理系统根据以上的控制原则设计完成之后就要被使用,使用的话就是通过API的方式,这里也列出8条API的设计原则:
1、所有API应该是声明式的。正如前文所说,声明式的操作,相对于命令式操作,对于重复操作的效果是稳定的,这对于容易出现数据丢失或重复的分布式环境来说是很重要的。另外,声明式操作更容易被用户使用,可以使系统向用户隐藏实现的细节,隐藏实现的细节的同时,也就保留了系统未来持续优化的可能性。此外,声明式的API,同时隐含了所有的API对象都是名词性质的,例如Service、Volume这些API都是名词,这些名词描述了用户所期望得到的一个目标分布式对象。
2、API对象是彼此互补而且可组合的。这里面实际是鼓励API对象尽量实现面向对象设计时的要求,即“高内聚,松耦合”,对业务相关的概念有一个合适的分解,提高分解出来的对象的可重用性。事实上,K8s这种分布式系统管理平台,也是一种业务系统,只不过它的业务就是调度和管理容器服务。
3、高层API以操作意图为基础设计。如何能够设计好API,跟如何能用面向对象的方法设计好应用系统有相通的地方,高层设计一定是从业务出发,而不是过早的从技术实现出发。因此,针对K8s的高层API设计,一定是以K8s的业务为基础出发,也就是以系统调度管理容器的操作意图为基础设计。
4、低层API根据高层API的控制需要设计。设计实现低层API的目的,是为了被高层API使用,考虑减少冗余、提高重用性的目的,低层API的设计也要以需求为基础,要尽量抵抗受技术实现影响的诱惑。
5、尽量避免简单封装,不要有在外部API无法显式知道的内部隐藏的机制。简单的封装,实际没有提供新的功能,反而增加了对所封装API的依赖性。内部隐藏的机制也是非常不利于系统维护的设计方式,例如PetSet和ReplicaSet,本来就是两种Pod集合,那么K8s就用不同API对象来定义它们,而不会说只用同一个ReplicaSet,内部通过特殊的算法再来区分这个ReplicaSet是有状态的还是无状态。
6、API操作复杂度与对象数量成正比。这一条主要是从系统性能角度考虑,要保证整个系统随着系统规模的扩大,性能不会迅速变慢到无法使用,那么最低的限定就是API的操作复杂度不能超过O(N),N是对象的数量,否则系统就不具备水平伸缩性了。
7、API对象状态不能依赖于网络连接状态。由于众所周知,在分布式环境下,网络连接断开是经常发生的事情,因此要保证API对象状态能应对网络的不稳定,API对象的状态就不能依赖于网络连接状态。
8、尽量避免让操作机制依赖于全局状态,因为在分布式系统中要保证全局状态的同步是非常困难的。
————————————————
根据k8s的设计理念、控制原则、API的设计原则,设计完之后的系统的样子,可以通过下边的架构图了解。
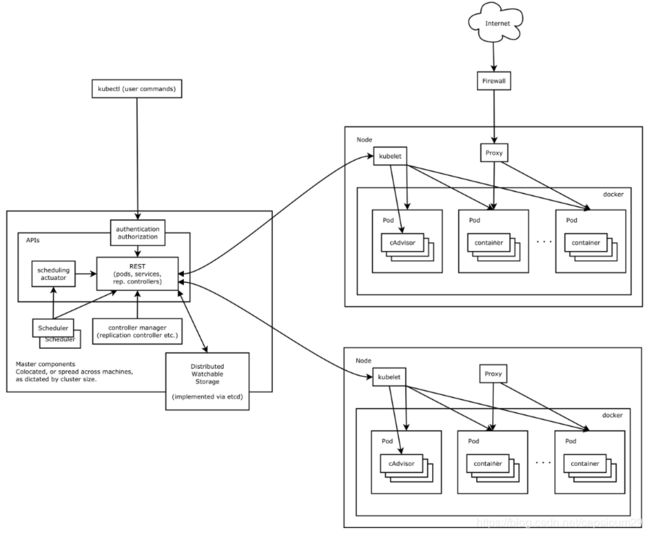
或者可以看一个更高层次的抽象,会更容易理解一些
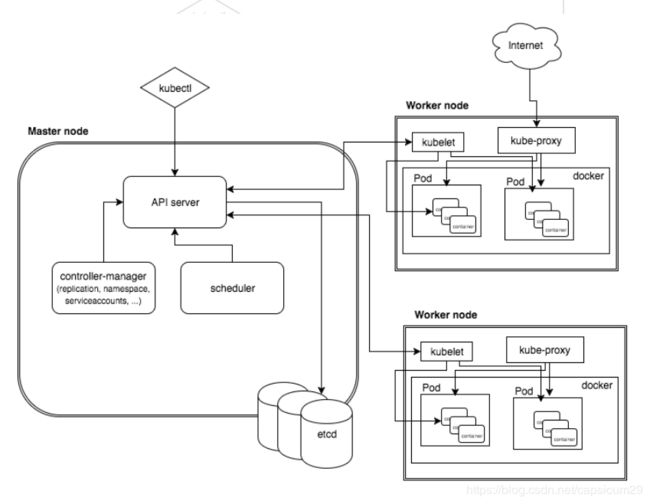
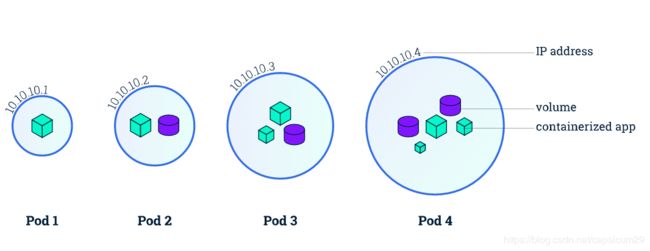
pod:从上边的架构图中,我们可以看到pod是运行在docker之上的,在 kubernetes 的设计中,最基本的管理单位是 pod,而不是 container。pod 是 kubernetes 在容器上的一层封装,由一组运行在同一主机的一个或者多个容器组成。如果把容器比喻成传统机器上的一个进程(它可以执行任务,对外提供某种功能),那么 pod 可以类比为传统的主机:它包含了多个容器,为它们提供共享的一些资源。Pod包含一个或者多个相关的容器,Pod可以认为是容器的一种延伸扩展,一个Pod也是一个隔离体,而Pod内部包含的一组容器又是共享的(包括PID、Network、IPC、UTS)。除此之外,Pod中的容器可以访问共同的数据卷来实现文件系统的共享。
通过下边这个图可以看到pod的几种形式,以及通过加卷的方式共享数据方式
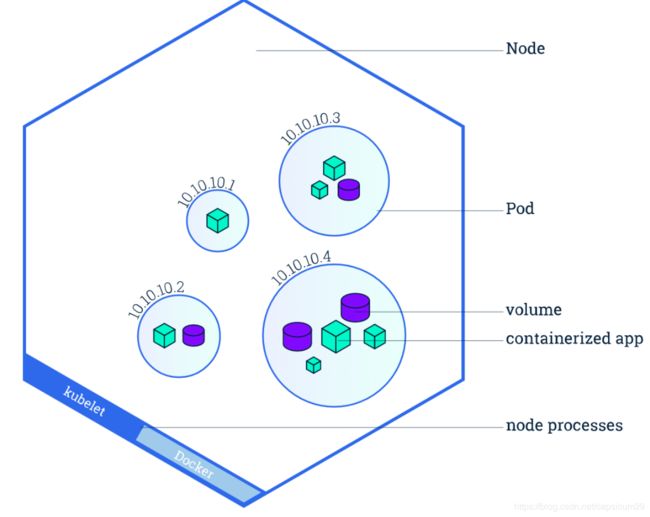
Node:Node是Kubernetes中的工作节点,最开始被称为minion。一个Node可以是VM或物理机。每个Node(节点)具有运行pod的一些必要服务,并由Master组件进行管理,Node节点上的服务包括Docker、kubelet和kube-proxy。目前Kubernetes支持docker和rkt两种容器
通过下边这个图可以更清晰的看出来node和pod的关系
**kubelet:**在每个节点(node)上都要运行一个 worker 对容器进行生命周期的管理,这个 worker 程序就是kubelet。kubelet的主要功能就是定时从某个地方获取节点上 pod/container 的期望状态(运行什么容器、运行的副本数量、网络或者存储如何配置等等),并调用对应的容器平台接口达到这个状态。kubelet 还要查看容器是否正常运行,如果容器运行出错,就要根据设置的重启策略进行处理。kubelet 还有一个重要的责任,就是监控所在节点的资源使用情况,并定时向 master 报告。知道整个集群所有节点的资源情况,对于 pod 的调度和正常运行至关重要。
**kube-proxy:**每个节点(node)都有一个组件kube-proxy,实际上是为service服务的,通过kube-proxy,实现流量从service到pod的转发,它负责TCP和UDP数据包的网络路由,kube-proxy也可以实现简单的负载均衡功能。其实就是管理service的访问入口,包括集群内Pod到Service的访问和集群外访问service。 kube-proxy管理sevice的Endpoints,该service对外暴露一个Virtual IP,也成为Cluster IP, 集群内通过访问这个Cluster IP:Port就能访问到集群内对应的serivce下的Pod。
**Service:**个人认为这是k8s重要性仅次于pod的概念,众所周知,pod生命周期短,状态不稳定,pod异常后新生成的pod ip会发生变化,之前pod的访问方式均不可达。通过service对pod做代理,service有固定的ip和port,ip:port组合自动关联后端pod,即使pod发生改变,kubernetes内部更新这组关联关系,使得service能够匹配到新的pod。这样,通过service提供的固定ip,用户再也不用关心需要访问哪个pod,以及pod是否发生改变,大大提高了服务质量。如果pod使用rc创建了多个副本,那么service就能代理多个相同的pod,所以service可以认为是一组pod的代理或者是更高层的抽象,其他的service通过本service提供的虚拟IP进行访问,也可以在service中对代理的一组pod提供负载服务。
通过这个图片可以看到Service和pod的关系
(原文链接:https://blog.csdn.net/maoyeqiu/article/details/79270625)
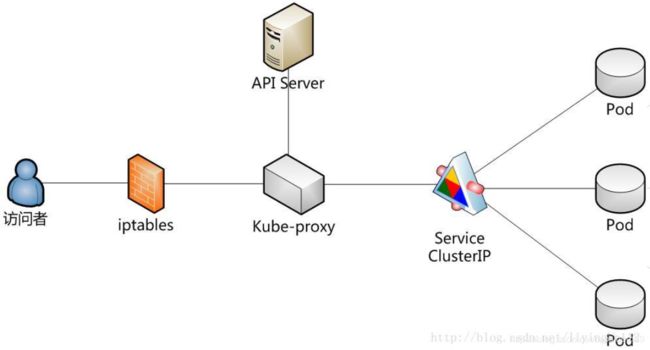
下边这个图从更整体的角度理解Service
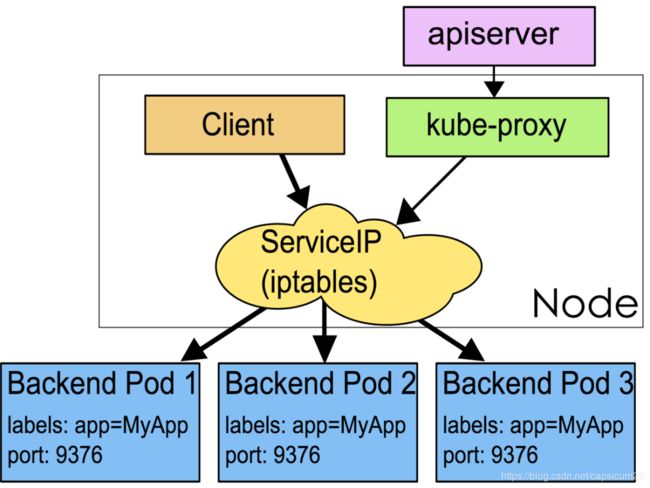
现在,假定有2个后台Pod,并且定义后台Service的名称为‘backend-service’,lable选择器为(tier=backend, app=myapp)。backend-service 的Service会完成如下两件重要的事情:会为Service创建一个本地集群的DNS入口,因此前端(frontend)Pod只需要DNS查找主机名为 ‘backend-service’,就能够解析出前端应用程序可用的IP地址。现在前端已经得到了后台服务的IP地址,但是它应该访问2个后台Pod的哪一个呢?Service在这2个后台Pod之间提供透明的负载均衡,会将请求分发给其中的任意一个。通过每个Node上运行的代理(kube-proxy)完成。
**Virtual IP:**k8s分配给Service一个固定IP,这是一个虚拟IP(也称为ClusterIP),并不是一个真实存在的IP,无法被ping,没有实体网络对象来响应,是由k8s虚拟出来的。虚拟IP的范围通过k8s API Server的启动参数 --service-cluster-ip-range=19.254.0.0/16配置;虚拟IP属于k8s内部的虚拟网络,外部是寻址不到的。在k8s系统中,实际上是由k8s Proxy组件负责实现虚拟IP路由和转发的,所以k8s
Node中都必须运行了k8s Proxy,从而在容器覆盖网络之上又实现了k8s层级的虚拟转发网络
**Endpoint:**每个pod都提供了一个独立的Endpoint( Pod ip + Container port )以被客户端访问
**Endpoints:**当有连接通过ClusterIP 到达Service的时候,service将根据endpoints提供的信息进行路由请求pod,Endpoints的变化可以通过k8s中的selectors手动或自动的被发现
**Label:**Label机制是Kubernetes中的一个重要设计,通过Label进行对象的弱关联,可以灵活地进行分类和选择,Label是识别Kubernetes对象(Pod、Service、RC、Node)的标签,以key/value的方式附加到对象上,Label不提供唯一性,比如可以关联Service和Pod。Label定义好后其他对象可以使用Label Selector来选择一组相同label的对象。
**Advisor:**Google的cAdvisor(Container Advisor)“为容器用户提供了了解运行时容器资源使用和性能特征的方法”。cAdvisor的容器抽象基于Google的lmctfy容器栈,因此原生支持Docker容器并能够“开箱即用”地支持其他的容器类型。cAdvisor部署为一个运行中的daemon,它会收集、聚集、处理并导出运行中容器的信息。这些信息能够包含容器级别的资源隔离参数、资源的历史使用状况、反映资源使用和网络统计数据完整历史状况的柱状图。
以上是node相关的一些概念的解释,从pod开始,根据关联性顺次解释,下边对master中的一些概念进行解读:
**master:**master节点负责管理整个k8s集群,这是所有管理任务的入口,master节点负责编排工作node。
Controller Manager作为集群内部的管理控制中心,负责集群内的Node、Pod副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的管理,当某个Node意外宕机时,Controller Manager会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。如果说APIServer做的是“前台”的工作的话,那controller
manager就是负责“后台”的。每个资源一般都对应有一个控制器,而controller manager就是负责管理这些控制器的。比如我们通过APIServer创建一个pod,当这个pod创建成功后,APIServer的任务就算完成了。而后面保证Pod的状态始终和我们预期的一样的重任就由controller manager去保证了。
**Replication Controller(RC):**是Kubernetes中的另一个核心概念,它的职责是确保集群中有且仅有N个Pod实例,N是RC中定义的Pod副本数量。通过调整RC中的spec.replicas属性值来实现系统扩容或缩容。通过改变RC中的Pod模板来实现系统的滚动升级。Replication Controller确保任意时间都有指定数量的Pod“副本”在运行。如果为某个Pod创建了Replication Controller并且指定3个副本,它会创建3个Pod,并且持续监控它们。如果某个Pod不响应,那么Replication Controller会替换它,保持总数为3.如果之前不响应的Pod恢复了,现在就有4个Pod了,那么Replication Controller会将其中一个终止保持总数为3。如果在运行中将副本总数改为5,Replication Controller会立刻启动2个新Pod,保证总数为5。
**Node Controller:**负责发现、管理和监控集群中的各个Node节点。
**Endpoint Controller:**定期关联service和pod(关联信息由endpoint对象维护),保证service到pod的映射总是最新的。
**Scheduler:**scheduler的职责很明确,就是负责调度pod到合适的Node上。如果把scheduler看成一个黑匣子,那么它的输入是pod和由多个Node组成的列表,输出是Pod和一个Node的绑定,即将这个pod部署到这个Node上。Kubernetes目前提供了调度算法,但是同样也保留了接口,用户可以根据自己的需求定义自己的调度算法。
**etcd:**etcd是一个高可用的键值存储系统,Kubernetes使用它来存储各个资源的状态,从而实现了Restful的API。
**API Server:**APIServer负责对外提供RESTful的Kubernetes API服务,它是系统管理指令的统一入口,任何对资源进行增删改查的操作都要交给APIServer处理后再提交给etcd。如架构图中所示,kubectl(Kubernetes提供的客户端工具,该工具内部就是对Kubernetes API的调用)是直接和APIServer交互的。只有API Server与存储通信,其他模块通过API Server访问集群状态。这样第一,是为了保证集群状态访问的安全。第二,是为了隔离集群状态访问的方式和后端存储实现的方式:API Server是状态访问的方式,不会因为后端存储技术etcd的改变改变。加入以后将etcd更换成其他的存储方式,并不会影响依赖依赖API Server的其他K8s系统模块。
————————————————
原文链接:https://blog.csdn.net/maoyeqiu/article/details/79270625
上面说完后基本上就晕了。 这就好办了
2、环境准备
为了满足生产要求, 那为了保证control plane稳定可靠,必须是多节点,而且是奇数节点。
有了多节点,前端访问则需要负载均衡接入,我使用了haproxy 接入群集。
主机列表,所有主机都是centos 7.7
| 主机名 | IP | 角色 | 软件 |
|---|---|---|---|
| POC-K8SHAProxy01 | 172.16.8.29 | 负载均衡 | HA-Proxy 1.5.18 |
| k8sm01 | 172.16.8.21 | master | docker 19.03.4/kubernetesVersion: v1.16.2 |
| k8sm02 | 172.16.8.22 | master | docker 19.03.4/kubernetesVersion: v1.16.2 |
| k8sm03 | 172.16.8.23 | master | docker 19.03.4/kubernetesVersion: v1.16.2 |
| k8snode01 | 172.16.8.24 | work node | docker 19.03.4/kubernetesVersion: v1.16.2 |
| k8snode02 | 172.16.8.25 | work node | docker 19.03.4/kubernetesVersion: v1.16.2 |
| k8snode03 | 172.16.8.26 | work node | docker 19.03.4/kubernetesVersion: v1.16.2 |
| poc-gfs01 | 172.16.8.41 | 分布式存储 | glusterfs 6.5 |
| poc-gfs02 | 172.16.8.42 | 分布式存储 | glusterfs 6.5 |
| poc-gfs03 | 172.16.8.43 | 分布式存储 | glusterfs 6.5 |
| poc-gfsclient | 172.16.8.44 | 分布式存储API提供 | Heketi 8.0.0 |
3、安装docker
# Install Docker CE
## Set up the repository
### Install required packages.
yum install yum-utils device-mapper-persistent-data lvm2
### Add Docker repository.
yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
## Install Docker CE. 19.03
yum update && yum install docker-ce.x86_64
## Create /etc/docker directory.
mkdir /etc/docker
# Setup daemon.
cat > /etc/docker/daemon.json <4、网络端口需求
Control-plane node(s)
k8sm01,k8sm02,k8sm03
| Protocol | Direction | Port Range | Purpose | Used By |
|---|---|---|---|---|
| TCP | Inbound | 6443 | Kubernetes API server | All |
| TCP | Inbound | 2379-2380 | etcd server client API | kube-apiserver, etcd |
| TCP | Inbound | 10250 | Kubelet API | Self, Control plane |
| TCP | Inbound | 10251 | kube-scheduler | Self |
| TCP | Inbound | 10252 | kube-controller-manager | Self |
| UDP | Inbound | 8285 | FLANNEL port | |
| UDP | Inbound | 8472 | FLANNEL port |
#执行:
firewall-cmd --zone=public --add-port=6443/tcp --permanent
firewall-cmd --zone=public --add-port=30443/tcp --permanent
firewall-cmd --zone=public --add-port=30080/tcp --permanent
firewall-cmd --zone=public --add-port=30116/tcp --permanent
firewall-cmd --zone=public --add-port=2379-2380/tcp --permanent
firewall-cmd --zone=public --add-port=10250/tcp --permanent
firewall-cmd --zone=public --add-port=10251/tcp --permanent
firewall-cmd --zone=public --add-port=10252/tcp --permanent
firewall-cmd --zone=public --add-port=8285/udp --permanent
firewall-cmd --zone=public --add-port=8472/udp --permanent
firewall-cmd --reload
firewall-cmd --zone=public --list-ports
Worker node(s)
| Protocol | Direction | Port Range | Purpose | Used By |
|---|---|---|---|---|
| TCP | Inbound | 10250 | Kubelet API | Self, Control plane |
| TCP | Inbound | 30000-32767 | NodePort Services** | All |
| UDP | Inbound | 8285 | FLANNEL port | |
| UDP | Inbound | 8472 | FLANNEL port |
firewall-cmd --zone=public --add-port=10250/tcp --permanent
firewall-cmd --zone=public --add-port=30000-32767/tcp --permanent
firewall-cmd --zone=public --add-port=8285/udp --permanent
firewall-cmd --zone=public --add-port=8472/udp --permanent
firewall-cmd --reload
firewall-cmd --zone=public --list-ports
5、部署haproxy
配置 kube-apiserver 高可用需要一个负载均衡器,这里直接使用了一个单节点 haproxy 代替一下,实际生产环境中可能使用 keepalived 保证 haproxy 的高可用
在POC-K8SHAProxy01 节点进行下面安装:
sudo yum install -y haproxy
firewall-cmd --zone=public --add-port=6443/tcp --permanent
firewall-cmd --reload
firewall-cmd --zone=public --list-ports
将 master node 的 kube-apiserver 的 6443 添加到 haproxy做负载均衡**
vi /etc/haproxy/haproxy.cfg
frontend k8s_apiserver *:6443
mode tcp
default_backend k8s
backend k8s
mode tcp
balance roundrobin
server k8smaster01 172.16.8.21:6443 check
server k8smaster02 172.16.8.22:6443 check
server k8smaster03 172.16.8.23:6443 check
# 由于后面的业务需要80和443 ,同时加上 30116 给dashbord使用
frontend k8s_apiserver *:443
mode tcp
default_backend k8s443
backend k8s
mode tcp
balance roundrobin
server k8smaster01 172.16.8.21:30443 check
server k8smaster02 172.16.8.22:30443 check
server k8smaster03 172.16.8.23:30443 check
frontend k8s_apiserver *:80
mode tcp
default_backend k8s80
backend k8s
mode tcp
balance roundrobin
server k8smaster01 172.16.8.21:30080 check
server k8smaster02 172.16.8.22:30080 check
server k8smaster03 172.16.8.23:30080 check
frontend k8s_apiserver *:30116
mode tcp
default_backend k8s30116
backend k8s
mode tcp
balance roundrobin
server k8smaster01 172.16.8.21:30116 check
server k8smaster02 172.16.8.22:30116 check
server k8smaster03 172.16.8.23:30116 check
reload 应用配置
systemctl reload haproxy
查看6443端口是否已经在监听状态**
运行 netstat -lntp查看
6、安装 kubeadm, kubelet and kubectl
友情提示:切记版本一定要一致,否则一定会失败。
##配置kubernetes.repo的源,由于官方源国内无法访问,这里使用阿里云yum源
cat < /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
# Set SELinux in permissive mode (effectively disabling it)
setenforce 0
swapoff -a
sed -i '/ swap / s/^/#/' /etc/fstab
sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
systemctl start kubelet
systemctl enable --now kubelet
cat < /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
kubectl -n kube-system get deployments
7、安装 master node
1、首先生成 配置文件
cat < kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
kubernetesVersion: v1.16.0
controlPlaneEndpoint: "172.16.8.29:6443"
imageRepository: "registry.aliyuncs.com/google_containers"
networking:
podSubnet: "10.244.0.0/16" ## 后面的网络准备使用 flannel,所以必须设置为此网段
apiServer:
certSANs:
-"k8s.50yc.cn"
EOF
#由于gcr.io 镜像不能访问,使用阿里云的镜像,但是使用阿里的也有问题,建议使用azure的镜像。注意 k8s.50yc.cn 为我测试使用的域名, 自己可以设置自己的域名。
2. 初始化集群
##重置群集,如有问题可以重置群集
#kubeadm reset
#systemctl daemon-reload && systemctl restart kubelet
sudo kubeadm init --config=kubeadm-config.yaml --upload-certs
- 初始化成功,记录下最后提示的 kubeadm join xxx 命令, 第一个是往集群添加master node,第二个是往集群添加 worker node
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 172.16.8.29:6443 --token 55yied.ytynuulcecqo35ly \
--discovery-token-ca-cert-hash sha256:a5b44874fdf62ffb14b76dd995aa1ea4d7ead0e2776f629336ec14cc8e3e7fe7 \
--control-plane --certificate-key 5653c297d882948b8af3b825cd6815a05be9975828072dab41d82d0a11415440
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 172.16.8.29:6443 --token 55yied.ytynuulcecqo35ly \
--discovery-token-ca-cert-hash sha256:a5b44874fdf62ffb14b76dd995aa1ea4d7ead0e2776f629336ec14cc8e3e7fe7
3、为 kubectl 配置kube-config
每台master需要执行
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
4. 安装 CNI插件 flannel
#参考此配置
https://github.com/maxshen29/maxstudy/blob/master/k8s/kube-flannel.yaml
kubectl apply -f kube-flannel.yaml
- 默认是从quay.io拉取flannel镜像,但是经常因为网络原因拉不了,这里从阿里云找了一个替换了一下
sed -i s#'quay.io/coreos/flannel:v0.11.0-amd64'#'regi:stry.cn-hangzhou.aliyuncs.com/mygcrio/flannel:v0.11.0-amd64'#g kube-flannel.yaml
5. 加入master节点
使用上面记录的kubeadm jion … 命令将另外两个master节点添加进集群
kubeadm join 172.16.8.29:6443 --token 55yied.ytynuulcecqo35ly \
--discovery-token-ca-cert-hash sha256:a5b44874fdf62ffb14b76dd995aa1ea4d7ead0e2776f629336ec14cc8e3e7fe7 \
--control-plane --certificate-key 5653c297d882948b8af3b825cd6815a05be9975828072dab41d82d0a11415440
6、加入work节点
将3个work节点执行下面命令
kubeadm join 172.16.8.29:6443 --token 55yied.ytynuulcecqo35ly \
--discovery-token-ca-cert-hash sha256:a5b44874fdf62ffb14b76dd995aa1ea4d7ead0e2776f629336ec14cc8e3e7fe7
7、相关命令
kubectl get node #查看节点
kubectl get pods -A -o wide #查看所有pods
kubectl get svc -A #查看所有服务
kubectl get ing -A #查看所有ingress(后续部署)
kubectl get secret -A # 查看所有secret
8 、安装ingress
由于从外部访问到k8s提供的服务,有几种方式,一种是nodeport,以端口方式提供出来。 但是应用越来越多,用这种方式就很麻烦,于是可以使用ingress,具体文档可以参考:
https://kubernetes.io/docs/concepts/services-networking/ingress/
相当于部署了一个nginx-ingress-controller 利用nginx 提供转发。
https://github.com/maxshen29/maxstudy/blob/master/k8s/ingress.yaml
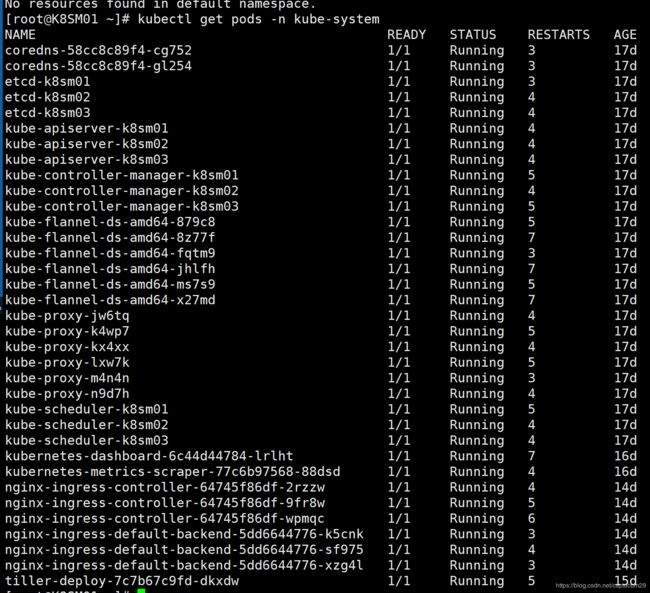
kubectl apply -f ingress.yaml
正常情况安装完成查看pods 应该都running
创建ingress 文件
在环境中我有相应的证书,因此创建了tls secret,注意证书 secret 命名空间要和服务空间相同
kubectl create secret tls tls-ingress-secret --cert=1.crt --key=1.key -n kube-system
创建 testingres文件内容如下
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: test-ingress
namespace: kube-system
annotations:
nginx.ingress.kubernetes.io/rewrite-target:
spec:
tls:
- hosts:
- k8s.50yc.cn
secretName: tls-ingress-secret
rules:
- host: k8s.50yc.cn
http:
paths:
- path: /testpath
backend:
serviceName: nginx-ingress-default-backend
servicePort: 80
完成后
默认访问没有内容的服务会转到404
9、 安装helm
helm 是很有用的工具,后面由于安装 harbor 用helm很好,于是把helm也部署上。helm版本安装的是 v2.14.3
https://github.com/maxshen29/maxstudy/tree/master/helm
在目录下载 helm 和 tiller 放在 /usr/local/bin
安装服务端
使用 helm init 即可安装
helm init --upgrade -i registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.5.1 --stable-repo-url https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
完成后执行
k8s 1.6 以上版本加入了RBAC的机制,因此需要添加Role Binding:
kubectl create clusterrolebinding add-on-cluster-admin --clusterrole=cluster-admin --serviceaccount=kube-system:default
执行
helm version
应该有如下
[root@K8SM01 storage]# helm version
Client: &version.Version{SemVer:"v2.14.3", GitCommit:"0e7f3b6637f7af8fcfddb3d2941fcc7cbebb0085", GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.14.3", GitCommit:"0e7f3b6637f7af8fcfddb3d2941fcc7cbebb0085", GitTreeState:"clean"}
10、 安装 Dashboard
https://github.com/maxshen29/maxstudy/blob/master/k8s/kubernetes-dashboard.yaml
安装dashboard 必须安装在master节点,并且1.16版本必须使用2.0版本的dashbord,请参考上面的链接的配置文件
kubectl label node k8sm01 dashboard=true
再yaml找到
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
nodeSelector:
dashboard: "true"
#由于我使用nodeport 服务配置如下
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
spec:
type: NodePort
ports:
- port: 443
nodePort: 30116
targetPort: 8443
#赋权 创建 token.yaml
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: admin
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: admin
namespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
-----
kubectl apply -f token.yaml
安装完成后,正常情况访问 https://172.16.8.29:30116/可以打开界面
使用token访问,由于我没有配置证书,只能用IP地址访问,并且浏览器也用fox
token 来源于:
kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}')
#这是所有用户的token,找到管理员的token即可登录
11、安装gluster
由于打算在环境中安装harbor,harbor作为hub需要持久化存储,比较好的选择是部署分布式存储,我选择了gluster作为分布式存储
在poc-gfs01,poc-gfs02,poc-gfs03加载了一块100g的裸磁盘sdb
# poc-gfs01,poc-gfs02,poc-gfs03,poc-gfsclient 上面编辑
vim /etc/hosts
172.16.8.41 poc-gfs01
172.16.8.42 poc-gfs02
172.16.8.43 poc-gfs03
sed -i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/selinux/config #关闭SELinux
setenforce 0
ntpdate time.windows.com #同步时间
firewall-cmd --add-service=glusterfs --permanent # poc-gfs01,poc-gfs02,poc-gfs03 执行
firewall-cmd --reload
firewall-cmd --zone=public --add-port=6443/tcp --permanent #poc-gfsclient执行
firewall-cmd --reload
yum install centos-release-gluster -y #如果没有安装 此,则版本会是 3.12版本。
yum -y install glusterfs-server glusterfs-fuse
gluster peer probe poc-gfs02
gluster peer probe poc-gfs03
[root@poc-gfs01 ~]# gluster peer status
Number of Peers: 2
Hostname: poc-gfs03
Uuid: 68b8519e-d6a1-464f-9781-004e40d7eaaf
State: Peer in Cluster (Connected)
Other names:
172.16.8.43
Hostname: poc-gfs02
Uuid: 6b84e435-396e-4bcb-954a-da10c2814f8f
State: Peer in Cluster (Connected)
Other names:
172.16.8.42
12、安装Heketi
完成gluster安装,再进行heketi安装
#,poc-gfsclient 安装
yum install heketi heketi-client -y
[root@poc-gfsclient ~]# heketi --version
Heketi 8.0.0
#修改配置
vi /etc/heketi/heketi.json
# 这里只展示需要修改的配置,其他默认配置参考原始文件(这里采用默认值)
{
# 服务端口,可以根据需要进行修改,防止端口使用冲突
"port": "8080",
# 启用认证
"use_auth": true,
# 配置admin用的key
"admin": {
"key": "admin_secret"
},
# executor有三种,mock,ssh,Kubernets,这里使用ssh
"executor": "ssh",
# ssh相关配置
"sshexec": {
"keyfile": "/etc/heketi/heketi_key",
"user": "root",
"port": "22",
"fstab": "/etc/fstab"
},
# heketi数据库文件位置(这里是默认路径)
"db": "/var/lib/heketi/heketi.db",
# 日志级别(none, critical, error, warning, info, debug)
"loglevel" : "warning"
}
# 选择ssh执行器,heketi服务器需要免密登陆GlusterFS集群的各节点;
# -t:秘钥类型;
# -q:安静模式;
# -f:指定生成秘钥的目录与名字,注意与heketi.json的ssh执行器中"keyfile"值一致;
# -N:秘钥密码,””即为空
[root@heketi ~]# ssh-keygen -t rsa -q -f /etc/heketi/heketi_key -N ""
# heketi服务由heketi用户启动,heketi用户需要有新生成key的读赋权,否则服务无法启动
[root@heketi ~]# chown heketi:heketi /etc/heketi/heketi_key
# 分发公钥;
# -i:指定公钥
[root@heketi ~]# ssh-copy-id -i /etc/heketi/heketi_key.pub root@poc-gfs01
[root@heketi ~]# ssh-copy-id -i /etc/heketi/heketi_key.pub root@poc-gfs02
[root@heketi ~]# ssh-copy-id -i /etc/heketi/heketi_key.pub root@poc-gfs03
root@poc-gfsclient heketi]# systemctl enable heketi
root@poc-gfsclient heketi]# systemctl start heketi
root@poc-gfsclient heketi]# systemctl status heketi
● heketi.service - Heketi Server
Loaded: loaded (/usr/lib/systemd/system/heketi.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2019-10-29 09:19:28 EDT; 18s ago
Main PID: 9640 (heketi)
CGroup: /system.slice/heketi.service
└─9640 /usr/bin/heketi --config=/etc/heketi/heketi.json
Oct 29 09:19:38 poc-gfsclient heketi[9640]: ├─19334 /usr/sbin/glusterfsd -s 172.16.8.43 --volfile-id vol_0c6b20101809623f55e6652895f442fd.172.16.8.43.var….8.43-var-li
Oct 29 09:19:38 poc-gfsclient heketi[9640]: ├─19396 /usr/sbin/glusterfsd -s 172.16.8.43 --volfile-id vol_f776a9f4544c3d4ee550000d439fe792.172.16.8.43.var….8.43-var-li
Oct 29 09:19:38 poc-gfsclient heketi[9640]: ├─19413 /usr/sbin/glusterfsd -s 172.16.8.43 --volfile-id vol_e592b107953baca0a5e46394494714d2.172.16.8.43.var….8.43-var-li
Oct 29 09:19:38 poc-gfsclient heketi[9640]: ├─19572 /usr/sbin/glusterfsd -s 172.16.8.43 --volfile-id vol_eb9607e384f759efab47fb181ba78cd9.172.16.8.43.var….8.43-var-li
Oct 29 09:19:38 poc-gfsclient heketi[9640]: ├─19685 /usr/sbin/glusterfsd -s 172.16.8.43 --volfile-id vol_5b9305dc77808cc951b93d48034e0565.172.16.8.43.var….8.43-var-li
Oct 29 09:19:38 poc-gfsclient heketi[9640]: └─19706 /usr/sbin/glusterfs -s localhost --volfile-id gluster/glustershd -p /var/run/gluster/glustershd/glustershd.pid …-6
Oct 29 09:19:38 poc-gfsclient heketi[9640]: Oct 25 11:17:59 poc-gfs03 systemd[1]: Starting GlusterFS, a clustered file-system server...
Oct 29 09:19:38 poc-gfsclient heketi[9640]: Oct 25 11:17:59 poc-gfs03 systemd[1]: Started GlusterFS, a clustered file-system server.
Oct 29 09:19:38 poc-gfsclient heketi[9640]: [heketi] INFO 2019/10/29 09:19:38 Periodic health check status: node c967daf92994dd712fa8d15cd0361691 up=true
Oct 29 09:19:38 poc-gfsclient heketi[9640]: [heketi] INFO 2019/10/29 09:19:38 Cleaned 0 nodes from health cache
配置 top文件
vim /etc/heketi/topology.json
{
"clusters": [
{
"nodes": [
{
"node": {
"hostnames": {
"manage": [
"172.16.8.41"
],
"storage": [
"172.16.8.41"
]
},
"zone": 1
},
"devices": [
"/dev/sdb"
]
},
{
"node": {
"hostnames": {
"manage": [
"172.16.8.42"
],
"storage": [
"172.16.8.42"
]
},
"zone": 1
},
"devices": [
"/dev/sdb"
]
},
{
"node": {
"hostnames": {
"manage": [
"172.16.8.43"
],
"storage": [
"172.16.8.43"
]
},
"zone": 1
},
"devices": [
"/dev/sdb"
]
}
]
}
]
}
heketi-cli --server http://172.16.8.44:8080 --user admin --secret admin_secret topology load --json=/etc/heketi/topology.json
正常会输出添加成功的报告
下面命令可以查看当前的top信息
heketi-cli --user admin --secret admin_secret topology info
# 查看heketi topology信息,此时volume与brick等未创建;
# 通过”heketi-cli cluster info“可以查看集群相关信息;
# 通过”heketi-cli node info“可以查看节点相关信息;
# 通过”heketi-cli device info“可以查看device相关信息
13、在K8S中使用存储
需要声明一个StorageClass
#创建一个secret。因为是级域base64code的,需要把 密钥 转换。
[root@K8SM01 storage]# vim heketi-secret.yaml
apiVersion: v1
kind: Secret
type: kubernetes.io/glusterfs
metadata:
name: heketi-secret
namespace: kube-system
data:
# base64 encoded. key=admin_secret
key: YWRtaW5fc2VjcmV0
[root@K8SM01 storage]# kubectl apply -f heketi-secret.yaml
#创建 storege classe
[root@K8SM01 storage]# vim storageclass-glusterfs.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: glusterfsclass
provisioner: kubernetes.io/glusterfs
parameters:
resturl: "http://172.16.8.44:8080"
clusterid: "8f5ae0affa498605e44b2f29bd51e079"
restauthenabled: "true"
restuser: "admin"
secretNamespace: "kube-system"
secretName: "heketi-secret"
gidMin: "40000"
gidMax: "50000"
volumetype: "replicate:3"
[root@K8SM01 storage]# kubectl apply -f storageclass-glusterfs.yaml
#创建5个10g的PV 安装harbor可以使用。
[root@K8SM01 storage]# vim harbor-pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: harbor-pvc01
namespace: harbor-system
spec:
storageClassName: glusterfsclass
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: harbor-pvc02
namespace: harbor-system
spec:
storageClassName: glusterfsclass
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: harbor-pvc03
namespace: harbor-system
spec:
storageClassName: glusterfsclass
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: harbor-pvc04
namespace: harbor-system
spec:
storageClassName: glusterfsclass
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: harbor-pvc05
namespace: harbor-system
spec:
storageClassName: glusterfsclass
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
[root@K8SM01 storage]# kubectl apply -f harbor-pvc.yaml
#成功后
[root@K8SM01 storage]# kubectl get storageclass
NAME PROVISIONER AGE
glusterfsclass kubernetes.io/glusterfs 3d11h
[root@K8SM01 storage]# kubectl get pv -A
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-423d1e5f-8457-4dbc-b9bd-6c2d51c45248 10Gi RWX Delete Bound harbor-system/harbor-pvc02 glusterfsclass 3d10h
pvc-4b1049b9-d392-46ed-ba60-b5e831f5a121 10Gi RWX Delete Bound default/glusterfs-vol-pvc01 glusterfsclass 3d11h
pvc-9c432ad7-b02d-4988-bb23-31186e91737a 10Gi RWX Delete Bound harbor-system/harbor-pvc01 glusterfsclass 3d10h
pvc-af37a4ab-69e3-4ffe-994f-e53870c864c9 10Gi RWX Delete Bound harbor-system/harbor-pvc03 glusterfsclass 3d10h
pvc-d33ee1e5-6e1b-42e3-bcf2-c5d0a29c978d 10Gi RWX Delete Bound harbor-system/harbor-pvc05 glusterfsclass 3d10h
pvc-ea777653-e92c-4c5b-b085-a7a97a155766 10Gi RWX Delete Bound harbor-system/harbor-pvc04 glusterfsclass 3d10h
[root@K8SM01 storage]# kubectl get pvc -A
NAMESPACE NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
default glusterfs-vol-pvc01 Bound pvc-4b1049b9-d392-46ed-ba60-b5e831f5a121 10Gi RWX glusterfsclass 3d11h
harbor-system harbor-pvc01 Bound pvc-9c432ad7-b02d-4988-bb23-31186e91737a 10Gi RWX glusterfsclass 3d10h
harbor-system harbor-pvc02 Bound pvc-423d1e5f-8457-4dbc-b9bd-6c2d51c45248 10Gi RWX glusterfsclass 3d10h
harbor-system harbor-pvc03 Bound pvc-af37a4ab-69e3-4ffe-994f-e53870c864c9 10Gi RWX glusterfsclass 3d10h
harbor-system harbor-pvc04 Bound pvc-ea777653-e92c-4c5b-b085-a7a97a155766 10Gi RWX glusterfsclass 3d10h
harbor-system harbor-pvc05 Bound pvc-d33ee1e5-6e1b-42e3-bcf2-c5d0a29c978d 10Gi RWX glusterfsclass 3d10h
可以看到相应的存储。
在gluster和heketi 同样可以看到
可以使用 df -l 查看
14、 安装harbor
有了pv资源,安装harbor就轻松多了, 下载 harbor-helm 安装包
git clone https://github.com/goharbor/harbor-helm.git
创建独立的命名空间
kubectl create namespace harbor-system
修改
harbor-helm-1.2.0 目录下 values.yaml
修改内容如下,目的是修改访问链接,替换生成的pv
tls:
enabled: true
secretName: "tls-ingress-secret"
commonName: "tls-ingress-secret"
ingress:
hosts:
core: reg.50yc.cn
notary: reg.50yc.cn
externalURL: https://reg.50yc.cn
persistence:
enabled: true
# Setting it to "keep" to avoid removing PVCs during a helm delete
# operation. Leaving it empty will delete PVCs after the chart deleted
#resourcePolicy: "keep"
resourcePolicy: ""
persistentVolumeClaim:
registry:
# Use the existing PVC which must be created manually before bound,
# and specify the "subPath" if the PVC is shared with other components
existingClaim: "harbor-pvc01"
# Specify the "storageClass" used to provision the volume. Or the default
# StorageClass will be used(the default).
# Set it to "-" to disable dynamic provisioning
storageClass: "glusterfsclass"
subPath: ""
accessMode: ReadWriteOnce
size: 10Gi
chartmuseum:
existingClaim: "harbor-pvc02" #之前生成的pv
storageClass: "glusterfsclass"
subPath: ""
accessMode: ReadWriteOnce
size: 10Gi
jobservice:
existingClaim: "harbor-pvc03"
storageClass: "glusterfsclass"
subPath: ""
accessMode: ReadWriteOnce
size: 10Gi
# If external database is used, the following settings for database will
# be ignored
database:
existingClaim: "harbor-pvc04"
storageClass: "glusterfsclass"
subPath: ""
accessMode: ReadWriteOnce
size: 10Gi
# If external Redis is used, the following settings for Redis will
# be ignored
redis:
existingClaim: "harbor-pvc05"
storageClass: "glusterfsclass"
subPath: ""
accessMode: ReadWriteOnce
size: 10Gi
------
helm add
kubectl create secret tls tls-ingress-secret --cert=1.crt --key=1.key -n harbor-system
helm repo add stable http://mirror.azure.cn/kubernetes/charts
helm install --name harbor -f values.yaml . --namespace harbor-system
完成后可以查看pod是否运行
成功输入网址应该可以看到登录界面
harbor 的功能有很多,还需要更多的研究。这里就不深入了
15、错误排查
整个的安装过程遇到很多的问题,主要有几种
1、拿不到镜像,解决办法推荐使用azure的 镜像代理,参考:https://github.com/Azure/container-service-for-azure-china/blob/master/aks/README.md#limitations-of-current-aks-private-preview-on-azure-china
2、版本不一致会导致很多问题,多参考官网文档。网上很多人写的未必靠谱
3、排错
journalctl -f # 当前输出日志
journalctl -f -u kubelet # 只看当前的kubelet进程日志 查看kubenetes的log
kubectl log
kubect describe
4、在重启k8s节常常遇到no route等的报错。 这问题很有可能是防火墙(iptables)规则错乱或者缓存导致的,和可能是flannel的bug,可以依次执行以下命令进行解决:
systemctl stop kubelet
systemctl stop docker
iptables --flush
iptables -tnat --flush
systemctl start kubelet
systemctl start docker