Kinect学习笔记
该博客只为记录点滴所学,若有误导,还请大家原谅,并不吝赐教。
**
Kinect 1.x 系列
**
Kinect硬件中,有三个摄像头,中间的摄像头是彩色相机,收集颜色数据,左边的是红外线发射器,右边的是深度感应器,就是通过接收发射的红外线来测算深度数据。放置高度在0.6m~1.8m之间都可以。
Kinect在V1.8版本只支持全身20块骨骼的运动
Kinect的坐标跟Unity的坐标有点不同,unity是遵循左手法则,Kinect遵循右手法则,且它的z轴正方向是它的摄像头超前的方向
任何想使用微软提供的API来操作Kinect,都必须在所有操作之前,调用NUI的初始化函数HRESULT NuiInitialize(DWORD dwFlags),即使用C#也是要这么做的。
kinect步骤:
a、首先初始化NuiInitialize函数,来告知kinect需要什么数据。参数是 NUI_INITIALIZE_FLAG
b、然后调用NuiImageStreamOpen函数
c、再次如果是等待数据回传的模式而不是事件模式的话,需调用
NuiImageStreamGetNextFrame函数,该函数第一个参数是数据流的句柄,即从哪里获取; 第二个参数是等待多长时间返回数据,如果是0,表示不等待,立即获取;第三个参数 是获得的数据指针
d、读取完一帧数据之后,要调用NuiImageStreamReleaseFrame函数,释放帧数据
e、在最后一定要调用NuiShutdown函数,不然别的应用程序接入Kinect设备时,会有 问题。
kinect传过来的数据,对于颜色数据来说,是每个元素占四个字节的数据,如果我们单字节取该元素的数据时,除了最后一个字节为0,别的都是值为0~255之间的值。而当我们要获得的数据是带用户信息的深度数据时,kinect传给我们的数据是每个元素占2个字节的数据,我们一般先把数据转换成USHORT类型,然后高13位表示真正的深度信息,低三位表示用户信息,当用户信息为0,即低三位为000时,就是背景的信息了;如果是不带用户信息的深度数据的话,则低12位是用户信息,高4位是空闲的。深度数据流所提供的图像帧中,每个像素点代表的是在深度感应器的视野中,该特定的(x,y)坐标处物体到摄像头平面的距离,如下图: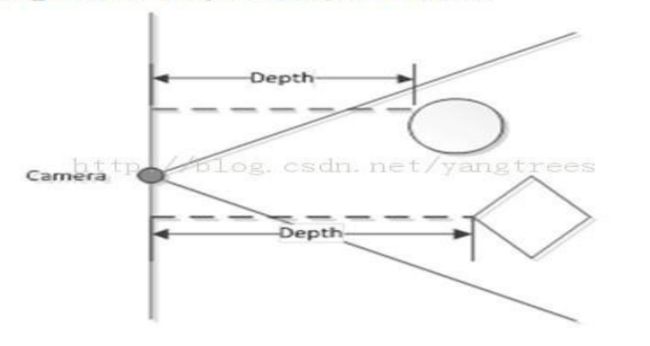
也就是说如果你要得到的是一个像素为640x480大小的图片的话,那么就会有640x480个深度值在一帧数据中。
Kinect中深度值最大为4096mm,0值通常表示深度值不能确定,一般应该将0值过滤掉。微软建议在开发中使用1220mm~3810mm范围内的值。
特别注意的是,深度数据的单位是mm(毫米)。
在进行其他深度图像处理之前,应该使用阈值方法过滤深度数据至1220mm-3810mm这一范围内。
下图显示了Kinect Sensor的感知范围,其中的default range对Xbox 360和Kinect for Windows都适用,而near range仅对后者适用:

深度数据有什么用?在带用户ID的深度数据中,我们可以抠出用户的图像(当作作业做)(已完成)。
10、kinect的骨骼空间:kinect感应器处在该空间原点,空间的z轴正方向是从感应器指向人的方向,Y轴是垂直感应器所在的平面并朝着感应器的上面的,x轴的正方向是朝左的(从kinect感应器的视角来看).所以有x=[-2.2,2.2],y=[-1.6,1.6],z=[0,4],它们的视角空间范围.而且得到的xyz值的单位是米(m).这里的z值应该就是深度信息了。这里x,y,z的取值范围是通过体感的辐射角度得到的。(至于为什么会是这个区间,下面会给予解释。)
11、Kinect获取骨骼数据的步骤:
a、同样是初始化感应器NuiSensor,NuiInitialize(NUI_INITIALIZE_FLAG_USES_SKELETON)
b、创建Windows事件句柄,CreateEvent();
c、打开骨骼跟踪事件 NuiSkeletonTrackingEnable(dNextEventHandler,dwFlags);
这两个参数,第一个的意思是应用程序所在位置的句柄,可传入第二步创建的句柄。当骨骼数据可用时,这个句柄就会被设置一个值,而且无论何时,只要有最新的帧数据返回时,这个句柄就会被设置一个新的值。
第二个参数是控制骨骼跟踪的,这个参数可以是NUI_SKELETON_TRACKING的位或运算的组合值。这些值有:
NUI_SKELETON_TRACKING_FLAG_SUPPRESS_NO_FRAME_DATA(阻止NuiSkeletonGetNextFrame函数返回空数据的错误,意思是如果返回的是空数据将继续等待,直到有数据可用或者等待时间超时);
NUI_SKELETON_TRACKING_FLAG_ENABLE_SEATED_SUPPORT(支持坐下的状态,意味着下身的10根骨骼将会被丢弃而不会跟踪);
NUI_SKELETON_TRACKING_FLAG_ENABLE_IN_NEAR_RANGE (支持近距离的跟踪)
NUI_SKELETON_TRACKING_FLAG_TITLE_SETS_TRACKED_SKELETONS (不知道什么意思)
当然也可以传0值,但是0值是代表什么意思还没有测过。
NuiTransformSkeletonToDepthImage(vPoint,pfDepthX,pfDepthY)函数的解析:该函数是将骨骼空间的坐标转换成深度空间的坐标
Kinect的深度图像的ID是0,1,2,3,4,5,6,7,其中0表示背景;骨骼图像的ID是0,1,2,3,4,5,6,其中0表示检测到的一个人,所以两者的关系是:骨骼ID+1=深度ID。
Kinect数据流(配合OpenCV显示):
ColorStream(图像数据流):需要一个窗口事件句柄(EventHandle),一个流句柄(StreamHandle);然后通过NuiImageStreamOpen()函数打开图像数据流;需要一个NUI_IMAGE_FRAME对象;调用NuiImageStreamGetNextFrame()函数来获取每帧得到的图像流数据;从FRAME对象里获得INuiFrameTexture对象,该对象是存储纹理信息的;把INuiImageFrameTexture对象的数据放到NUI_LOCKED_RECT里,然后对数据进行处理。
DepthStream(深度数据流):同图像数据流,就是在处理数据时有不同。
SkeletonStream(骨骼数据流):需要一个窗口事件句柄(EventHandle);然后打开骨骼跟踪事件
NuiSkeletonTrackingEnable();需要一个NUI_SKELETON_FRAME结构对象,后面所有的数据都会存储在这个结构对象里,比如骨骼是否跟踪到,哪块骨骼被跟踪到等等;调用
NuiSkeletonGetNextFrame()函数获取每帧得到的骨骼数据流;获得骨骼数据之后,调用
NuiTransformSmooth()函数对骨骼坐标数据进行平滑处理;然后再循环每一个检测到的用户的每一根骨骼,对其做处理,比如连线等。
使用Kinect SDK和openCV结合获取并展现彩色数据时,kinect传过来的是每个像素四个字节或者说四个通道的数据,其中最后一个通道的值永远是0,其余三个通道都只是一个数值,无关乎RGB;而当我们转成OpenCV展现时,如果我们定义的数据类型为CV_8UC3的话,那么这三个通道分别按照BGR的顺序排列。(ptr[j]=pbuffer[4*j];ptr[3*j+1]=pbuffer[4*j+1]; ptr[3*j+2]=pbuffer[4*j+2];能做到分成两张图像,有待分析原因)
NuiTransformSkeletonToDepthImage(Vector4 vPoint,float *fx,float *fy);
该函数是将获得的帧数据中的骨骼空间坐标转换成深度空间坐标,vPoint值就是需要转换的坐标值,至于为什么是4维向量,经试验得出最后一维w的值是1,可能是为了其次坐标与4阶矩阵相乘的原因。fx,fy是转换成深度空间坐标后所承载的x和y的坐标值,且不能传空值。而z轴的值就是深度值。
Kinect的颜色坐标就是图片的像素坐标;深度空间有不同:它的x,y坐标也是像素坐标,z坐标就是实际的Kinect的摄像头平面到物体的那个点的平面的距离,是平面到平面的距离;骨骼空间就是人体的骨骼点在Kinect的视野范围内的坐标。
那么深度空间和骨骼空间的坐标是怎么换算的,如下图所示:

这里的两个点为什么会有相同的x,y值,因为这两个点在深度图像上只会显示一个点,后面或者说离摄像机远的那个点会被前面的点挡住,然后根据x,y和深度值还有摄像机的fov角度计算出骨骼空间的x’,y’。当然有一个计算公式为xSkeleton=(xNorm-0.5f)*depth*multipler.
这里的xNorm是归一化的深度x坐标值,即把坐标值按照分辨率比例变成0~1范围内的数,multiplier是一个固定的数,它只跟fov有关,在x轴上,该值是1.12032,在y轴上,该值是0.84024,xSkeleton就是我们最后得到的骨骼空间的x坐标。
通过这个公式我们就能推断到骨骼空间的x,y的取值范围了。例如当xNorm为0时,即其在深度像素空间的最左边时,且取depth的最大值4,则有-0.5f*4*1.12032=-2.24064,跟官方给的数据正好相等。那么它的fov的值有arctan(theta/2)=2.24064/4,得到的值差不多等于58.44,与官方给出的57相差无几。
通过NUI_SKELETON_FRAME获得的骨骼节点坐标是Kinect感应器的骨骼空间的绝对坐标,并不是相对于人的重心的坐标,这一点比较重要。
后面附上一个GestureDataSet的下载地址:
http://research.microsoft.com/en-us/downloads/4e1c9174-9b94-4c4d-bc5e-0a9c929869a7/default.aspx
Kinect 2.x系列
Kinect的Lasso手势,有点与拍照时摆“耶”的手势相似,只不过Lasso手势需要食指和中指紧挨着,而不是分开的。当然如果玩家的手指比较大的话,一个手指立起来,另外一个手指弯下去闭合着也是可以的。至于要两个手指,是因为可以更好地进行深度捕捉,得到更精确的捕捉效果。
当我们检测手的状态时,理想情况下是不会有NotKnown和NotTracked这两个状态的。但是由于Kinect的检测精度问题,这两个状态又会占比比较大。在实际应用过程中,我们可以假设Kinect检测是非常精确的,这样就没有NotKnown和NotTracked这两个状态了。如果检测到有这两个状态的话,那就取上一次的状态为该次的状态。
DepthImage,深度图像,它的坐标值(x,y)就是像素点的坐标,z值就是这个点在摄像机空间的深度。我们要取深度值的话,直接取Z值就好。
CoordinateMapper类,可以实现实现:
1、2D彩色图像坐标位置(即x,y坐标)到3D摄像机空间位置的转换。
2、色彩图像坐标位置和深度图像坐标位置的相互映射。
由于色彩摄像机和深度感应相机不是同一个摄像机,它们的位置是有偏差的,所以它们得到的图像是有偏差的。
过滤器 filters,在trackingstate 在inferred状态时应用。
Kinect的刷新帧率有可能会比Unity的帧率要低,即在Unity中Update里每帧去轮询数据,有可能是拿不到的,因为Kinect还没传输过来,这里需要注意。
Kinect2.0插上电脑后,会有时而断开时而连接的问题,怀疑是系统的kinect驱动问题,重启一下就好了。
CoordinateMapper是具体实现什么功能,比如将CamerePoint(测到的骨骼空间的点)转换到DepthPoint,或ColorPoint,转换的值是否跟我们眼睛观测到的值一样,还是说受我们传入的CameraPoint的值的影响。
人体跟踪使用的是深度感应器,所以得到的人体坐标值能完美地与深度帧匹配上。(这句话有待验证。做实验测得深度数据的单位与人体跟踪得到的数据单位不同。)
人体跟踪得到的数据单位是米
经测得,将手的跟踪得到的骨骼坐标数据转换成颜色像素坐标,得到的值会比原来的稳定很多。但是在一定区域内,超过这个区域也是容易有误差。这种方法对于做手掌控制鼠标的应用要好很多,现在需要了解的是Kinect的骨骼数据获取范围很精确的范围是多少到多少。
Kinect的ColorSpace的(0,0)点在左上角,深度图像的原点也一样。
Kinect骨骼捕捉,SpineBase关节点是Kinect的摄像机空间的位置。但是别的关节点的位置,其x和y值是相对于SpineBase关节点的位置,要得到特定关节点的x、y在摄像机空间的位置,只需要跟SpineBase的x、y值相加减就可以。而z值却是在Kinect的摄像机空间的位置值,不知道Kinect为什么要这么做。
Kinect获取的深度值是两字节的大小ushort类型。一般我们要转换成Unity里图片的像素值的话,由于图片像素值都是byte类型的,所以需要将ushort转换成byte,但是需要注意它们的界限。因为Kinect获取的深度值有效的范围是[500,4500]之间,是超过byte类型的大小的(byte 大小是0~256),但是小于ushort的界限(ushort界限是0~65536).
Unity里我们可以给Texture指定byte数组,来显示这张图片。在new一个Texture时我们可以给它指定图片的通道、压缩等。
texture=newTexture2D(depthDescription.Width,depthDescription.Height,TextureFormat.ARGB32,false);
这里TextureFormat.ARGB32也是默认的纹理格式,即如果不指定的话,它就是这个纹理格式。它表示有ARGB4个通道,每个通道是一个8位的值。也可以指定图片为灰度图,TextureFormat.Alpha8.
当我们给一个多通道的图片赋值时,比如这个图片的大小为W * H,那么我们需要一个4*W*H大小的字节数组赋给它。每4个字节作为一个像素,得到一张图片。Kinect得到的彩色图数据是两个字节的数据,如果要得到彩色的话,需要自己做转换,这个网上找了好久没找到答案。不过好在Kinect自己有转换的方法,可以按照我们需要的图片编码格式来转换。比如是RGBA还是Alpha。
在Unity里处理Kinect传过来的图像要慎用LockBuffer这样的函数,容易引起崩溃。这也限制了在Unity里使用Kinect最好用主动查询数据的方式,而不是事件来了通知的方式。因为主动查询的方式我们一般会在Update里写,如果这一帧还没处理完,是不会去请求下一帧的,所以不太会有数据读写在两个地方有交叉的问题,就不需要加锁。但是如果用事件通知的方式的话,有可能这一帧数据还没处理完,下一帧数据就来了,会同时改动某个变量的值,这时比较安全的方式就是用LockBuffer这样的操作。
以下是将Kinect收到的深度数据转换成Unity的图片纹理的算法过程。
int index = 0;
for (int i = 0; i < (int)(depthDescription.LengthInPixels); ++i)
{
//这里做这个转换,是因为在Kinect里它的原点坐标在左上角,而Unity里的原点坐标在左下角。
int row = depthDescription.Height - (i / depthDescription.Width + 1);
int col = i % depthDescription.Width;
ushort depth = depthData[i];
index = (row * depthDescription.Width + col);
this.depthPixels[4 * index] = 255;
this.depthPixels[4 * index + 1] = 0;// aa[0];
this.depthPixels[4 * index + 2] = 0;// aa[1];
this.depthPixels[4 * index + 3] = (byte)(depth >= 500 && depth <= 4500 ? (depth / MapDepthToByte) : 0);
}
texture.LoadRawTextureData(depthPixels);
texture.Apply();
Kinect的Color数据的Description,有两种获取方式,一种是直接调用属性Description,它默认的数据每个像素是两个字节的长度。但是在彩色数据里,两个字节长度明显不够,所以需要调用第二种方法:CreateFrameDescrition(ColorImageFormat.rgba),才能得到4个字节的彩色数据。
神经网络的组织和判断是基于概率和统计的。
除了能够识别复杂和精细的手势,神经网络方法还能解决基于算法手势识别存在的扩展性问题。神经网络包含很多神经元,每一个神经元是一个好的算法,能够用来判断手势的细微部分的运动。在神经网络中,许多手势可以共享神经元。但是每一中手势识别有着独特的神经元的组合。而且,神经元具有高效的数据结构来处理信息。这使得在识别手势时具有很高的效率。
使用基于神经网络进行手势识别的缺点是方法本身复杂。虽然神经网络以及在计算机科学中对其的应用已经有了好几十年,建立一个好的神经网络对于大多数程序员来说还是有一些困难的。大多数开发者可能对数据结构中的图和树比较熟悉,而对神经网络中尺度和模糊逻辑的实现可能一点都不了解。这种缺乏建立神经网络的经验是一个巨大的困难,即使能够成功的构建一个神经网络,程序的调试相当困难。
和基于算法的方法相比,神经网络依赖大量的参数来能得到精确的结果。参数的个数随着神经元的个数增长。每一个神经元可以用来识别多个手势,每一个神经远的参数的变化都会影响其他节点的识别结果。配置和调整这些参数是一项艺术,需要经验,并没有特定的规则可循。然而,当神经网络配对机器学习过程中手动调整参数,随着时间的推移,系统的识别精度会随之提高。
Kinect Face:
FaceFrame类包含一系列基础的人脸信息。它可以告诉你脸在哪里,脸朝向哪里,基本的表情信息,以及是否有戴眼镜。
FaceFrame里的数据大都是通过红外检测(Infrared)得到的,这说明不论在什么样的灯光条件下都是可以用的。但有一个例外,那就是LeftEyeClose和RightEyeClose这两个属性是需要彩色摄像头的,会受弱灯光的影响。
Math.Atan2(y,x)函数的功能:
这个函数返回的是在一个笛卡尔坐标系里,x轴正轴到向量(x,y)的旋转角度值。它与arctan(z)的函数关系是:theta = Math.Atan2(y,x);tan(theta) = y/x;
所以有如下关系:
Atan2(y,x)函数返回的角度值在(-pi,pi)之间,其中:
若x,y在第一象限,返回值在(0,pi/2)之间;
若x,y在第二象限,返回值在(pi/2,pi)之间;
若x,y在第三象限,返回值在(-pi,-pi/2)之间;
若x,y在第四象限,返回值在(-pi/2,0)之间;
若在x轴正向上,返回值为0;
若在x轴负向上,返回值为pi;
若在y轴正向上,返回值为pi/2;
若在y轴负向上,返回值为-pi/2;
该函数对于求一个向量的旋转角度很方便。比如两个点(x0,y0) (x1,y1),那么向量
(x1-x0,y1-y0)的旋转角度就是Math.Atan2(y1-y0,x1-x0)
Unity里,不能在申明全局变量的时候赋系统的值,比如:
public string path = Application.dataPath;这样会报错,说构造函数需要在主线程里执行。
C#中的枚举类型,只能是int型的,虽然你可以指定它为别的类型。
Kinect的FaceDetect有好多坑在里面,罗列如下:
1、 要做人脸检测,需要开启BodyFrame,检测到人。因为人脸检测有个类FaceSourceFrame,需要赋一个TrackID。开始默认是赋0,但是这不是一个合法的值,需要在检测到人之后动态改变这个ID。
2、 你如果想要什么数据,就得在FaceFrameFeatures里指定。如果不指定的话,那取到的值都是0.比如你想获得眼睛在彩色图像里的位置信息,如果不指定FaceFrameFeatures.PointsInColorSpace,则获取到的值是0.