SQLSERVER群集故障转移笔记
出自《SQLSERVER2012实施与管理实战指南》
SQLSERVER故障转移 P41


事实上,从sqlserver2000到sqlserver2008 R2,sqsrvres.dll中定义的looksalive和isalive方法都是类似的。
具体来讲:
looksalive:通过服务器控制管理器(service control manager,SCM)来检查SQLSERVER服务在活跃节点
是否处于“启动状态”。根据SQLSERVER资源的Advanced Polices选项卡中的设置,这个检查默认是
每5秒做一次
isalive:根据SQLSERVER资源的Advanced Polices选项卡中的设置,这个检查默认是60秒做一次
也就是说每12次Looksalive检查就会伴随一个Isalive检查。SQLSERVER需要Isalive检查是因为即使
SQLSERVER服务是正在运行状态也不能说明SQLSERVER就可以良好地响应应用程序的请求。有时候
可能整个SQLSERVER已经挂起了,但是服务的状态还是“启动”,所以需要Isalive Check来进一步
检查SQLSERVER的状态。此外,一旦lookalive检查的结果失败,Windows群集服务就会立刻触发
Isalive检查
在SQL2012之前,Isalive所做的事情很简单,Windows群集服务会使用TCP/IP或者命名管道来连接
SQLSERVER群集实例。连接上之后,运行一句命令:“
select @@servername”。如果成功返回结果
那么Isalive检查就成功了。从第一次成功执行select @@servername开始,Isalive检查就会根据设定
的时间间隔,使用这个连接不断地重复检查工作
如果连接不上SQLSERVER群集实例或者语句运行失败,那么Isalive检查失败。此时Windows群集会
再做3~5次(Windows的版本和设置不同)Isalive检查。如果这些检查都失败,就要根据Policies选项卡
中的设置开始进行故障转移
你可以把故障转移简单地想象成SQLSERVER服务的重启,所不同的是故障转移的时候,SQLSERVER服务是在
当前节点停止的,然后在另一个节点上启动起来。因此故障转移所花费的时间和SQLSERVER服务重启的时间
是差不多的。当然共享磁盘和虚拟网络名等资源在另一个节点上线也会额外花费一点时间,不过在大多数
情况下这部分时间是比较短的。另外由于故障转移一般是意外发生的,所以你要预期SQLSERVER切换到
新节点以后,还需要一段时间来做数据库的修复
前面也提到过,除了
SQLSERVER和
SQLSERVER AGENT以外,SQLSERVER资源组里可能还会有
Analysis Service
资源。但是和SQLSERVER和SQLSERVER AGENT所不同的是,Analysis Service资源没有自己的资源类型,
也就是说他是一个GENERIC SERVICE(通用服务)。Analysis Service的isalive和lookalive检查就使用的是
clusres.dll中定义的通用服务检查方法。
SQLSERVER的诸多组件和服务中,SQLSERVER 、SQLSERVER AGNET、ANALYSIS SERVICE三个服务
无论是有自己专属的资源类型还是通用服务,都是被设计为可以通过resource dll形成群集资源。
这种类型的服务被称为
cluster-aware。SQLSERVER还有很多其他资源,比如:SQL broswer、Reporting Service
等,他们被设计为无法通过任何resource dll在Windows群集中形成资源,所以他们不是cluster-aware的。
对于不是cluster-aware的服务,即使被安装在了群集的节点上,Windows依旧把他当成是安装在了一个
单机环境中,他无法具有故障转移的功能。
需要提一下的是Integration Services是一个比较特别的服务。Integration Services本身不是cluster-aware的服务
,但是用户可以通过一些步骤手动把他配置成一个群集资源。但是这样配置出来的Integration Services群集
资源不是一个真正的资源,是不具有自动故障转移功能的,因此微软并不推荐这麽做。
更多信息,参考
http://msdn.microsoft.com/en-us/library/ms345193.aspx
Configuring Integration Services in a Cluster
http://msdn.microsoft.com/kb/942176
2.2.4 SQLSERVER群集的拓扑结构
最简单的SQLSERVER故障转移群集拓扑结构就是“活跃/非活跃 ”群集,这种结构
下群集有两个节点,用户在群集上安装一个SQLSERVER群集实例,该实例的“可能的所有者(Possible Owners)”
包含上述两个节点。这样任意时间只有一个节点上有SQLSERVER服务在运行,而另一个节点就是“非活跃”
节点。这种配置优点就是结构简单明了,无论SQLSERVER运行在哪个节点上都能获得同样的性能表现。
缺点是总有一个节点处于空闲状态,浪费了50%的硬件资源
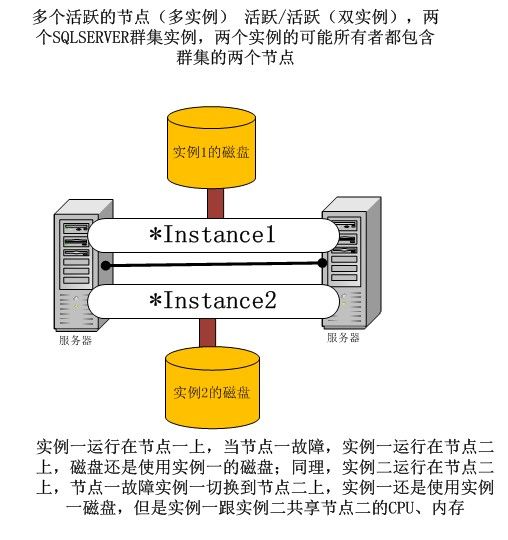
另一种拓扑结构是活跃/活跃集群,还是以一个两节点的群集为例,这个时候用户在群集上安装两个SQLSERVER
群集实例,每个实例的“可能的所有者”都包含群集两个节点。在正常情况下,两个实例分别运行在不同的节点上,
这样两个节点就都是“活跃”节点
这种结构的优势是:两个节点的硬件资源都能被充分利用(需要安装两个或多个SQLSERVER群集实例),并且节约成本。
缺点是:一旦某个节点发生故障转移,就会发生另一个节点上同时运行了两个SQLSERVER实例的情况。此时,这两个
实例可能会争用这个节点上的CPU、内存、I/O等资源,导致两个实例的性能都受到影响。有时可能两边的用户都不能
接受。因此要尽快解决异常节点上的问题,尽早把发生故障转移的实例切换回去
在此基础上,我们来介绍所谓的N+1结构,即N个活跃节点加上一个非活跃节点,以3个节点的群集为例
在上面安装两个SQLSERVER群集实例,每个实例的Possible Owner包含群集中的两个节点,但是只有
一个节点是两个实例共有的。正常情况下,两个SQLSERVER都运行在非共有的那个节点上,互不相干
。一旦某个节点发生故障转移,就会切换到那个共有的非活跃节点上
这个结构是一个介于“活跃/非活跃”和“活跃/活跃”之间的一种方案。相对于“活跃/非活跃”,
他浪费的节点资源比较少(1/N+1)。另外,两个以上的节点同时发生故障转移,需要同时切换到
共有节点的概率是比较低的,因此也在一定程度上解决了“活跃/活跃”结构的性能问题
无论什么样的拓扑结构,有两点是不会变的:
1、SQLSERVER集群
无法提供数据库端的负载均衡功能。
作为“活跃/活跃”群集,其实是几个
独立的数据库实例,他们彼此间没有联系。再次强调,群集技术只是一个提供“高可用性”的技术
,而不是提升性能的技术
2、无论群集有几个节点,
对于某个数据库实例而言他只有一份数据。
一旦数据本身出现问题,群集
对此便无能为力。所以,群集技术不是一个提供数据“灾难恢复”的技术。对重要的数据库,仅仅使用群集技术是不够的
2.2.5 SQL2012对故障转移群集的改进
SQLSERVER2012群集基本沿袭了SQLSERVER2008群集以来的一系列特点。不过他也带来了一些新特性
使得群集具有了更加强大的功能以及更高的可用性。
新特性介绍
1、多子网群集的支持
2、RegisterAllProvidersIP
3、存放数据库的物理位置
4、新的Resource DLL
5、Sp_server_diagnostics