Generative Adversarial Nets(小白学GAN系列 一)
原论文链接:https://arxiv.org/abs/1406.2661
简介
核心思想:借用了“零一”博弈的方式来训练生成网络。从而使得网络可以从已有的数据中学到其分布的概率。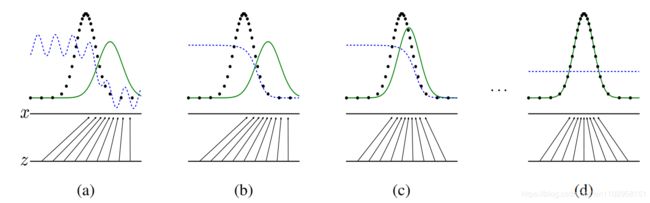
上图中黑色点是真实的数据分布,绿色实线是G(生成器)学习到的数据分布,蓝色虚线是判别器的划分界限,即在蓝虚线之下的判断为真实数据,在蓝虚线之上的判断为虚拟数据。由此可见,在训练刚开始之时(a)蓝线可以分部分真假的数据,到(b)时D(判别器)训练了一次后划分真假数据更为明显,再到(c)训练G使得G的数据分布向着真实数据在靠近,如此重复n次直到(d)G的数据分布已经完全拟合真实数据分布,D也无力再区分数据真假。
核心过程:
通过优化V来完成D与G的博弈过程。
![]()
基础结构
判别器训练:
判别器训练和普通的训练过程相同,自己为真实数据和生成数据打上标签,然后将数据经过判别器后的结果与标签求loss来优化判别器,而此时V的值是在增大的
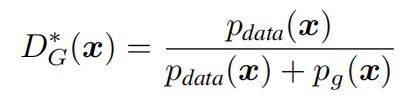

可知D结果的值域为(0,1),当G与真是数据分布相同时,D的结果为0.5。
生成器训练:
生成器的目标是尽可能地向实际数据分布拟合,从而使得判别器无法判断真伪,基于此来设计loss。
由上式展开可得:
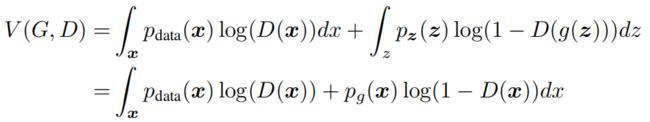
从上式感性的认识上来说,当D全判断为真或全判断为假时,其值都为零,其他情况时值都为负,且最小值正是当G完全拟合了实际数据时,D的结果为0.5,其取到最小值:

引入散度的概念后:
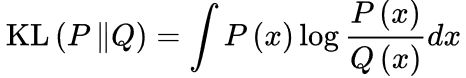
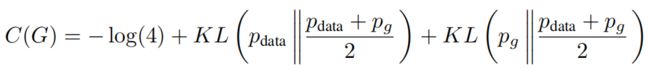
实际中去掉 -log4 ,则当G与Data完全拟合时,loss刚好等于零。
总体上看
![]()
单一的优化D时,V的值变大,优化G时,V的值变小,形成相互对抗的局面。
代码实践与结果
代码实现(参考:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/gan/gan.py)
自己做了少许修改,即训练两次G,再训练一次D:
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
# Loss function
adversarial_loss = torch.nn.BCELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
#真实数据打上标签
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
#生成数据打上标签
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator 1
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
#看G有多厉害,可以用假的来蒙混过D
g_loss.backward()
optimizer_G.step()
# -----------------
# Train Generator 2
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(real_imgs), valid)
#真判为真的能力
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
#假判为假的能力
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
用minist测试的结果