云计算编程模式漫谈(转)
云计算编程模式漫谈(转)
标签: 云计算 编程 2小时前近年来,云计算受到了工业界和学术界的广泛关注。随着智能手机和移动互联网的不断发展,云计算对于普通用户来说也已经触手可及,如iPhone用户可以使用iCloud提供的云存储功能,实现数据的云端存储和交换。云计算技术的发展也给小型创业公司以新的机遇,如2012年4月10日美国照片分享应用开发商Instagram被Facebook宣布以10亿美元收购,而Instagram公司仅仅以50万美元、10个人的团队起步,通过使用Amazon的云计算和云存储等服务,支持到3000多万用户,极大降低了成本。
作为一种新兴的计算模式,云计算以互联网服务和应用为中心,其背后是大规模集群和海量数据,新的场景需要新的编程模型来支撑。云计算场景下,新的 编程模型要能够方便快速的分析和处理海量数据,并提供安全、容错、负载均衡、高并发和可伸缩性等机制。
为了能够低成本高效率地处理海量数据,主要的互联网公司都在大规模集群系统上研发了分布式编程系统,使普通开发人员可以将精力集中于业务逻辑上,不用关注分布式编程的底层细节和复杂性,从而降低普通开发人员编程处理海量数据并充分利用集群资源的难度。
目前云计算编程模型的研究在工业界和学术界方兴未艾,各种新思想和新技术不断出现。本文首先重点介绍几种有代表性的通用编程模型:
通用编程模型
1)MapReduce
MapReduce是Google公司的Jeff Dean等人提出的编程模型,用于大规模数据的处理和生成。从概念上讲,MapReduce处理一组输入的key/value对(键值对),产生另一组输出的键值对。当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(化简)函数,用来保证所有映射的键值对中的每一个共享相同的键组。程序员只需要根据业务逻辑设计Map和Reduce函数,具体的分布式、高并发机制由MapReduce编程系统实现。
相信大家对MapReduce相关机制已经比较熟悉,这里不做更深入的阐述。
MapReduce在Google得到了广泛应用,包括反向索引构建、分布式排序、Web访问日志分析、机器学习、基于统计的机器翻译、文档聚类等。
Hadoop——作为MapReduce的开源实现——得到了Yahoo!、Facebook、IBM等大量公司的支持和应用。
2)Dryad
Dryad是Microsoft设计并实现的允许程序员使用集群或数据中心计算资源的数据并行处理编程系统。从概念上讲,一个应用程序表示成一个有向无环图(Directed Acyclic Graph,DAG)。顶点表示计算,应用开发人员针对顶点编写串行程序,顶点之间的边表示数据通道,用来传输数据,可采用文件、TCP管道和共享内存的FIFO等数据传输机制。Dryad类似Unix中的管道。如果把Unix中的管道看成一维,即数据流动是单向的,每一步计算都是单输入单输出,整个数据流是一个线性结构,那么Dryad可以看成是二维的分布式管道,一个计算顶点可以有多个输入数据流,处理完数据后,可以产生多个输出数据流,一个Dryad作业是一个DAG。
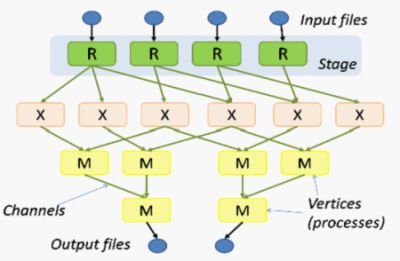
图1 Dryad作业结构
Dryad是针对运行Windows HPC Server的计算机集群设计的,是Microsoft构建云计算基础设施的核心技术之一。2011.2《程序员》杂志有文章专门介绍Dryad,这里不做深入阐述。
3)Pregel
Pregel是Google提出的一个面向大规模图计算的通用编程模型。许多实际应用中都涉及到大型的图算法,典型的如网页链接关系、社交关系、地理位置图、科研论文中的引用关系等,有的图规模可达数十亿的顶点和上万亿的边。Pregel编程模型就是为了对这种大规模图进行高效计算而设计。
Pregel的设计思想来自美国哈佛大学教授Leslie Valiant在1990年提出的BSP(Bluk Synchronous Parallel)模型。BSP模型包括三部分:BSP机器模型、BSP计算模型和BSP代价模型。其中BSP计算模型采用单程序多数据(SPMD)的执行方式。BSP计算由一组处理单元和一系列连续的超级步 (superstep)组成。在每个超级步内,每个处理单元并发地执行本地计算,并向其他的处理单元发送消息。在一个超级步结束时有一个全局的同步操作。因此,可以看作计算-通信-同步模式。
具体而言,Pregel计算由一系列的迭代(即超级步)组成。在每一个超级步中,计算框架会调用顶点上的用户自定义的Compute函数,这个过程是并行执行的。Compute函数定义了在一个顶点V以及一个超级步S中需要执行的操作。该函数可以读入前一超级步S-1中发送来的消息,然后将消息发送给在下一超级步S+1中处理的其他顶点,并且在此过程中修改V的状态以及其出边的状态,或者修改图的拓扑结构。消息通过顶点的出边发送,但一个消息可以送到任何已知ID的特定顶点上去。这种计算模式非常适合分布式实现:顶点的计算是并行的;它没有限制每个超级步的执行顺序,所有的通信都仅限于S到S+1之间。
Pregel是一个以顶点为中心的计算模型,边在这种计算模式中并不是第一类对象,在边上没有相应的计算。
计算模型
Pregel编程模型的输入是一个有向图,其中顶点有一个可以唯一标识的字符串ID,有向边包含源顶点和目标顶点的信息,顶点和有向边都允许用户自定义一些可修改的值。
一个典型的Pregel计算过程包括以下步骤:读取输入,初始化该图,然后是一系列由全局同步点分隔的超级步,直到算法结束,输出结果。
每个顶点通过“vote to halt”的方式说明计算结束。在超级步0中,所有顶点都会被初始化为活动(active)状态。每一个活动的顶点都会在某一次的超级步中被计算。完成计算任务后,顶点将自身设置为非活动状态。除非该顶点收到一个其他超级步发送的消息,否则Pregel框架将不会在接下来的超级步中再计算该顶点。如果顶点接收到消息,该消息将该顶点重新置为活动状态,那么在随后的计算中该顶点必须再次将自身置为非活动状态。
整个计算在所有顶点都达到非活动状态,并且没有消息再传送的时候结束。这种简单的状态机制在图2中描述:
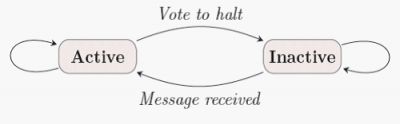
图2 顶点状态机
整个Pregel程序的输出是所有顶点输出的集合。
Pregel选择消息传递模式主要基于以下两点考虑:首先,消息传递有足够高效的表达能力;其次,性能原因,通过异步和批量的方式传递消息,该模式可以缓解集群环境中远程读取的延迟。
C++ API
Pregel的接口非常简单,只需要继承Vertex类并重写虚函数Compute()即可,其中参数msgs为其他顶点发送来的消息。
Pregel在Googel的PageRank中有所应用。开源的Apache Hama采用了类似的思想。
4)All-Pairs
All-Pairs是从科学计算类应用中抽象出来的一种编程模型。从概念上讲,All-Pairs 解决的问题可以归结为求集合A和集合B的笛卡尔积。All-Pairs模型典型应用场景是比较两个图片数据集中任意两张图片的相似度。典型的All-Pairs 计算包括四个阶段:首先对系统建模求最优的计算节点个数;随后向所有的计算节点分发数据集;接着调度任务到响应的计算节点上运行;最后收集计算结果。
下面我们对上述的代表性编程模型做一个比较。我们选取以下几个维度作为比较的指标:
任务间依赖关系描述,表示用户如何描述其任务间的依赖关系,如MapReduce模型的用户只能通过Map/Reduce这两个固定的阶段来描述其程序的任务;
动态控制流描述,表示模型是否支持对于动态控制流的描述还是只是支持数据流的描述,控制流包括:判断、选择、合并、分发等控制信息;
适用环境。
比较结果如下表所示:

Hadoop作为MapReduce的开源实现得到了业界的广泛支持,已经几乎成为海量数据处理的事实标准。Dryad主要是Microsoft在其计算机集群中使用,目前Microsoft也在其Azure云平台上提供了Hadoop支持。
高级编程模型
在通用编程模型的基础上,又发展了很多高级编程模型,下面再介绍其中的几种代表性模型。
1)Sawzall
Sawzall是Google建立在其MapReduce编程模型之上的查询语言,Sawzall的典型任务是在成百或上千台机器上并发操作上百万条记录。整个计算分为两个阶段:过滤阶段(相当于Map阶段)和聚合阶段(相当于Reduce阶段),并且过滤和聚合均可以在大量的分布式节点上并行执行。Sawzall程序实现非常简洁,据统计一个完成相同功能的MapReduce C++程序代码量是Sawzall程序代码量的10―20倍。
2)FlumeJava
FlumeJava是一个建立在MapReduce之上的Java库,适合由多个MapReduce作业拼接在一起的复杂计算场景使用。FlumeJava能简单的开发、测试和执行数据并行管道。
FlumeJava库位于MapReduce等原语的上层,在允许用户表达计算和管道(Pipeline)信息的前提下,通过自动的优化机制后,调用MapReduce等底层原语进行执行。Flumejava首先优化执行计划,然后基于底层的原语来执行优化了的操作。
3) DryadLINQ
DryadLINQ是Microsoft的高级编程语言。DryadLINQ结合了Microsoft的两个重要技术:Dryad语言和查询语言LINQ。DryadLINQ使用和LINQ相同的编程模型,并扩展了少量操作符和数据类型以适用于分布式计算。DryadLINQ程序是一个顺序的LINQ代码,对数据集做任何无副作用的操作,编译器会自动地将数据并行的部分翻译成执行计划,交给底层的Dryad完成计算。
4)Pig Latin
Pig Latin是Yahoo!研发的运行在其Pig系统上数据流语言。Pig是高层次的声明式SQL与低层次过程式的MapReduce之间的折中。Pig系统将Pig Latin程序编译成一组Hadoop(MapReduce的开源实现)作业然后进行执行。Pig不仅提供了常见的数据处理操作,包括加载、存储、过滤、分组、排序和连接等,同时Pig还提供了丰富的数据模型,支持原子类型、字典、元组等数据结构,以及嵌套操作的支持。
结束语

随着商业智能分析、社交网络分析、在线推荐、数据挖掘、机器学习等应用的普及和深入,海量数据处理的应用领域越来越呈现出多样化的趋势。而这些应用领域的问题可以抽象为结构化数据处理、大规模图计算、迭代计算等多种不同类型的计算。这些不同的问题领域适合采用不同的编程模型,不存在能解决所有数据密集型应用的通用编程模型。可以预见,会不断出现新的编程模型来解决领域相关的应用。
本文是在与中科院计算所高级工程师王磊和中科院计算所博士生导师詹剑锋两位老师讨论后撰写的,在此对他们表示感谢。
臧秀涛,2010年硕士研究生毕业于中科院计算所。现在计算所从事数据中心计算与云计算的测试床研究工作。关注虚拟机、分布式计算等技术。曾在完美世界等公司工作